Researchers from the National University of Singapore Developed a Groundbreaking RMIA (Robust Membership Inference Attack) Technique for Enhanced Privacy Risk Analysis in Machine Learning
Privacy in machine learning models has become a critical concern owing to Membership Inference Attacks (MIA). These attacks gauge whether specific data points were part of a model’s training data. Understanding MIA is pivotal as it assesses the inadvertent exposure of information when models are trained on diverse datasets. MIA’s scope spans various scenarios, from statistical models to federated and privacy-preserving machine learning. Initially rooted in summary statistics, MIA methods have evolved, utilizing diverse hypothesis testing strategies and approximations, especially in deep learning algorithms.
Previous MIA approaches have faced significant challenges. Despite enhancements in attack effectiveness, computational demands have rendered many privacy audits impractical. Some cutting-edge methods, particularly for generalized models, verge on random guessing when constrained by computation resources. Moreover, the lack of clear, interpretable means for comparing different attacks has led to their mutual dominance, where each attack outperforms the other based on varying scenarios. This complexity necessitates the development of more robust yet efficient attacks to evaluate privacy risks effectively. The computational expense associated with existing attacks has limited their practicality, underscoring the need for novel strategies that achieve high performance within constrained computation budgets.
In this context, a new paper was published to propose a novel attack approach within the realm of Membership Inference Attacks (MIA). Membership inference attacks, aiming to discern if a specific data point was utilized during training of a given machine learning model θ, are depicted as an indistinguishability game between a challenger (algorithm) and an adversary (privacy auditor). This involves scenarios where a model θ is trained with or without the data point x. The adversary’s task is to infer, based on x, the trained model θ, and their knowledge of the data distribution, which scenario they are positioned in within these two worlds.
The new Membership Inference Attack (MIA) methodology introduces a finely-tuned approach to construct two distinct worlds where x is either a member or non-member of the training set. Unlike prior methods simplifying these constructions, this novel attack meticulously composes the null hypothesis by replacing x with random data points from the population. This design leads to many pairwise likelihood ratio tests to gauge x’s membership relative to other data points z. The attack aims to collect substantial evidence favoring x’s presence in the training set over a random z, offering a more nuanced analysis of leakage. This novel method computes the likelihood ratio corresponding to x and z, distinguishing between scenarios where x is a member and non-member through a likelihood ratio test.
Named Relative Membership Inference Attack (RMIA), this methodology leverages population data and reference models to enhance attack potency and robustness against adversary background knowledge variations. It introduces a refined likelihood ratio test that effectively measures the distinguishability between x and any z based on shifts in their probabilities when conditioned on θ. Unlike existing attacks, this method ensures a more calibrated approach, avoiding dependencies on uncalibrated magnitude or overlooking essential calibration with population data. Through a meticulous pairwise likelihood ratio computation and a Bayesian approach, RMIA emerges as a robust, high-power, cost-effective attack, outperforming prior state-of-the-art methods across various scenarios.
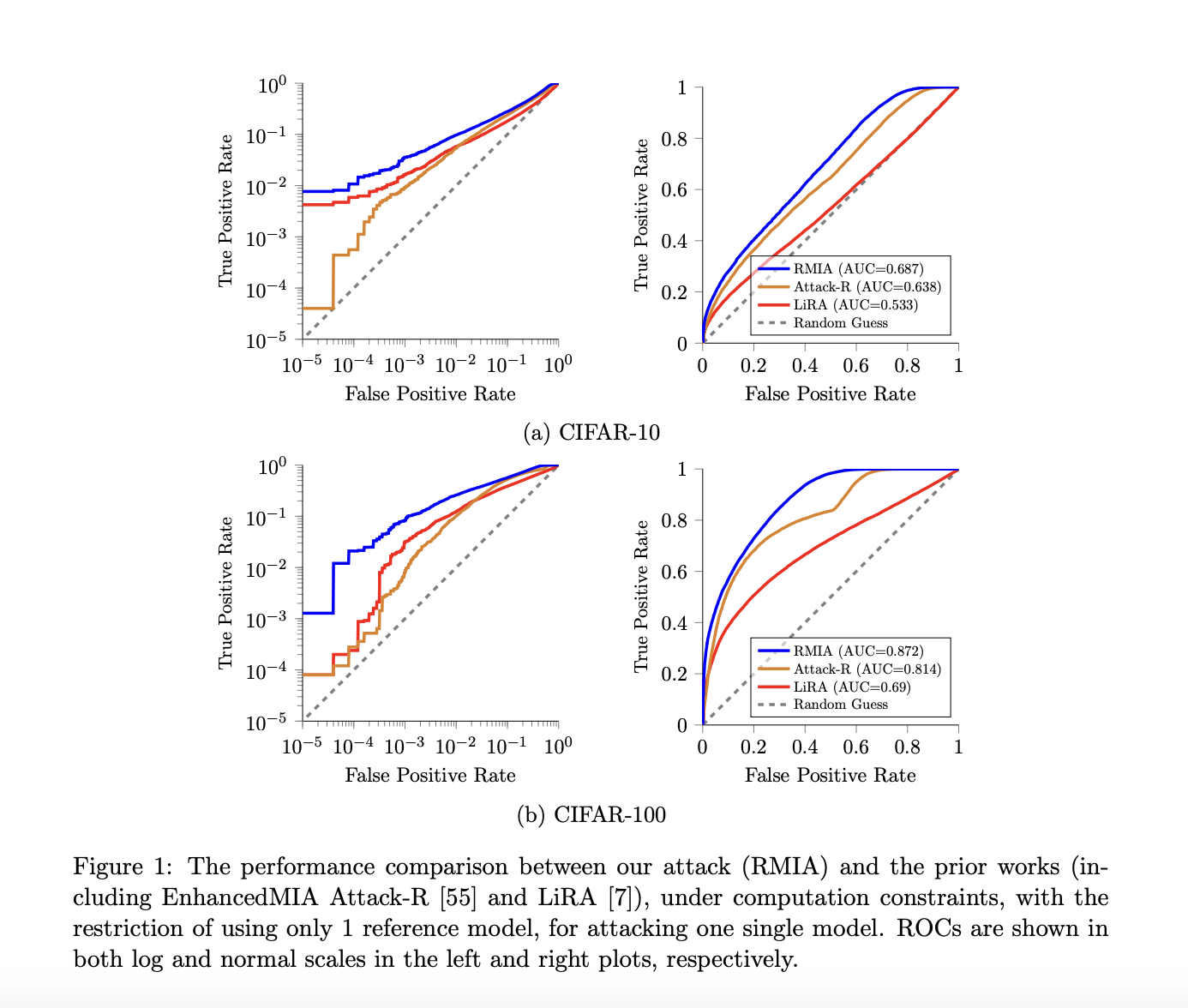
The authors compared RMIA against other membership inference attacks using datasets like CIFAR-10, CIFAR-100, CINIC-10, and Purchase-100. RMIA consistently outperformed other attacks, especially with a limited number of reference models or in offline scenarios. Even with few models, RMIA showed close results to scenarios with more models. With abundant reference models, RMIA maintained a slight edge in AUC and notably higher TPR at zero FPR compared to LiRA. Its performance improved with more queries, showcasing its effectiveness in various scenarios and datasets.
To conclude, the article presents RMIA, a Relative Membership Inference Attack method, demonstrating its superiority over existing attacks in identifying membership within machine learning models. RMIA excels in scenarios with limited reference models, showcasing robust performance across various datasets and model architectures. In addition, This efficiency makes RMIA a practical and viable choice for privacy risk analysis, especially in scenarios where resource constraints are a concern. Its flexibility, scalability, and the balanced trade-off between accuracy and false positives position RMIA as a reliable and adaptable method for membership inference attacks, offering promising applications in privacy risk analysis tasks for machine learning models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.