This AI Paper Introduces SuperContext: An SLM-LLM Interaction Framework Using Supervised Knowledge for Making LLMs Better in-Context Learners
Large language models(LLMs) undergo extensive training on diverse datasets, allowing them to mimic human-like text generation. However, LLMs need help maintaining accuracy and reliability, particularly when they encounter data or queries that deviate significantly from their training material.
Despite their impressive capabilities, LLMs face significant challenges, particularly in enhancing their reliability and accuracy in unfamiliar contexts. The crux of the issue lies in improving their performance in out-of-distribution (OOD) scenarios. Often, LLMs exhibit inconsistencies and inaccuracies, manifesting as hallucinations in outputs, which impede their applicability in diverse real-world situations.
Traditional methods primarily revolve around refining these models through extensive training on large datasets and prompt engineering. Yet, these techniques have their limitations. They must address the nuances of generalizability and factuality, especially when confronted with unfamiliar data. Furthermore, the dependency on vast data pools raises questions about the efficiency and practicality of these methods.
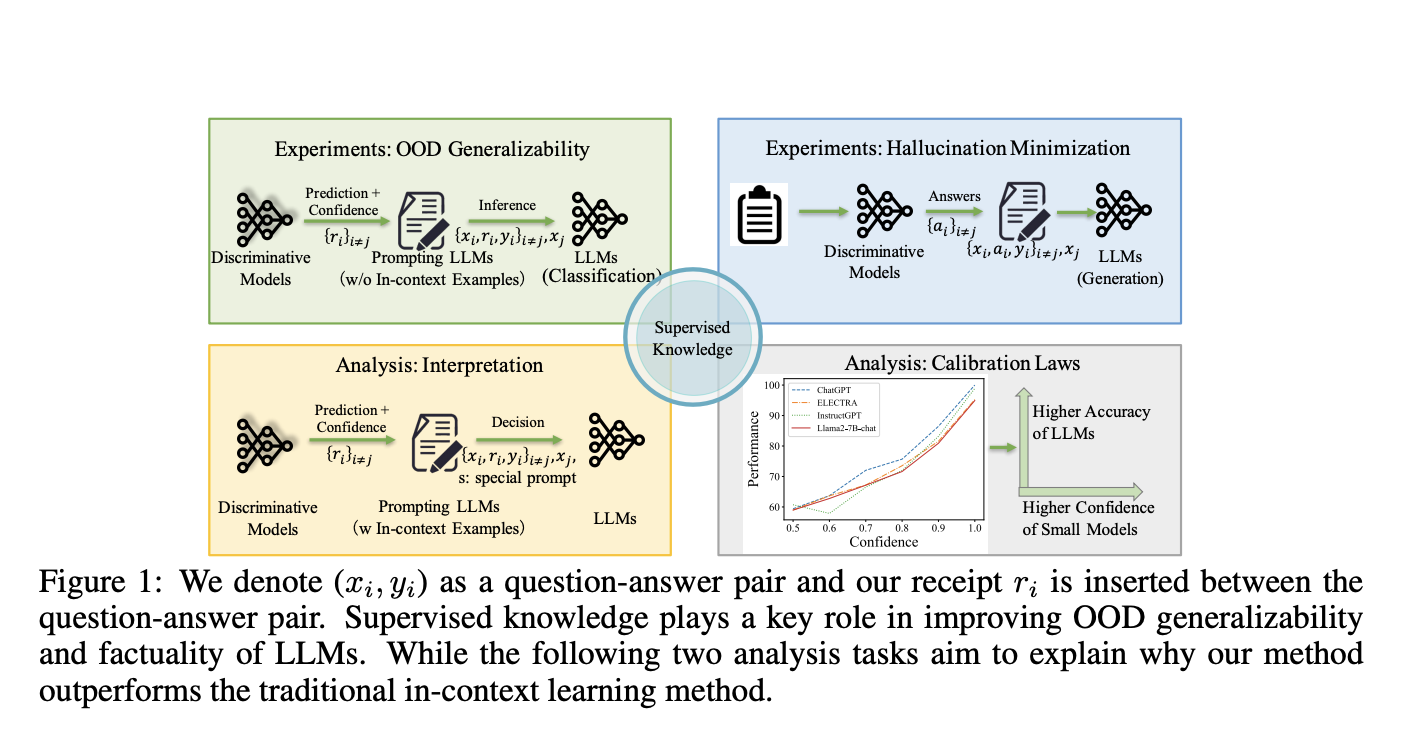
Addressing this gap, researchers from Westlake University, Peking University, and Microsoft introduced “SuperContext,” a novel methodology that synergizes the strengths of both large language models and smaller, task-specific supervised language models (SLMs). The essence of SuperContext lies in its innovative integration of the outputs from these discriminative models into the prompts used by LLMs. This approach enables a seamless melding of extensive pre-trained knowledge with specific task data, significantly enhancing the models’ reliability and adaptability across various contexts.

The SuperContext method works by incorporating predictions and confidence levels from SLMs into LLMs’ inference process. This integration provides a more robust framework, allowing LLMs to leverage the precise, task-focused insights from SLMs. Consequently, it addresses the issues of generalizability and factuality head-on. The methodology bridges LLMs’ vast, generalized learning and the nuanced, task-specific insights provided by SLMs, leading to a more balanced and effective model performance.

Empirical studies on SuperContext have yielded promising results. When pitted against traditional methods, SuperContext significantly elevates the performance of both SLMs and LLMs. This enhancement is particularly noticeable in terms of generalizability and factual accuracy. The technique has shown substantial performance improvements in diverse tasks, such as natural language understanding and question answering. In scenarios involving out-of-distribution data, SuperContext consistently outperforms its predecessors, showcasing its efficacy in real-world applications.
In conclusion, the SuperContext method marks a significant stride in natural language processing. By effectively amalgamating the capabilities of LLMs with the specific expertise of SLMs, it addresses the longstanding issues of generalizability and factual accuracy. This innovative approach enhances the performance of LLMs in varied scenarios. It opens new avenues for their application, making them more reliable and versatile tools in the ever-evolving landscape of artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.