This AI Paper from Harvard and Meta Unveils the Challenges and Innovations in Developing Multi-Modal Text-to-Image and Text-to-Video Generative AI Models
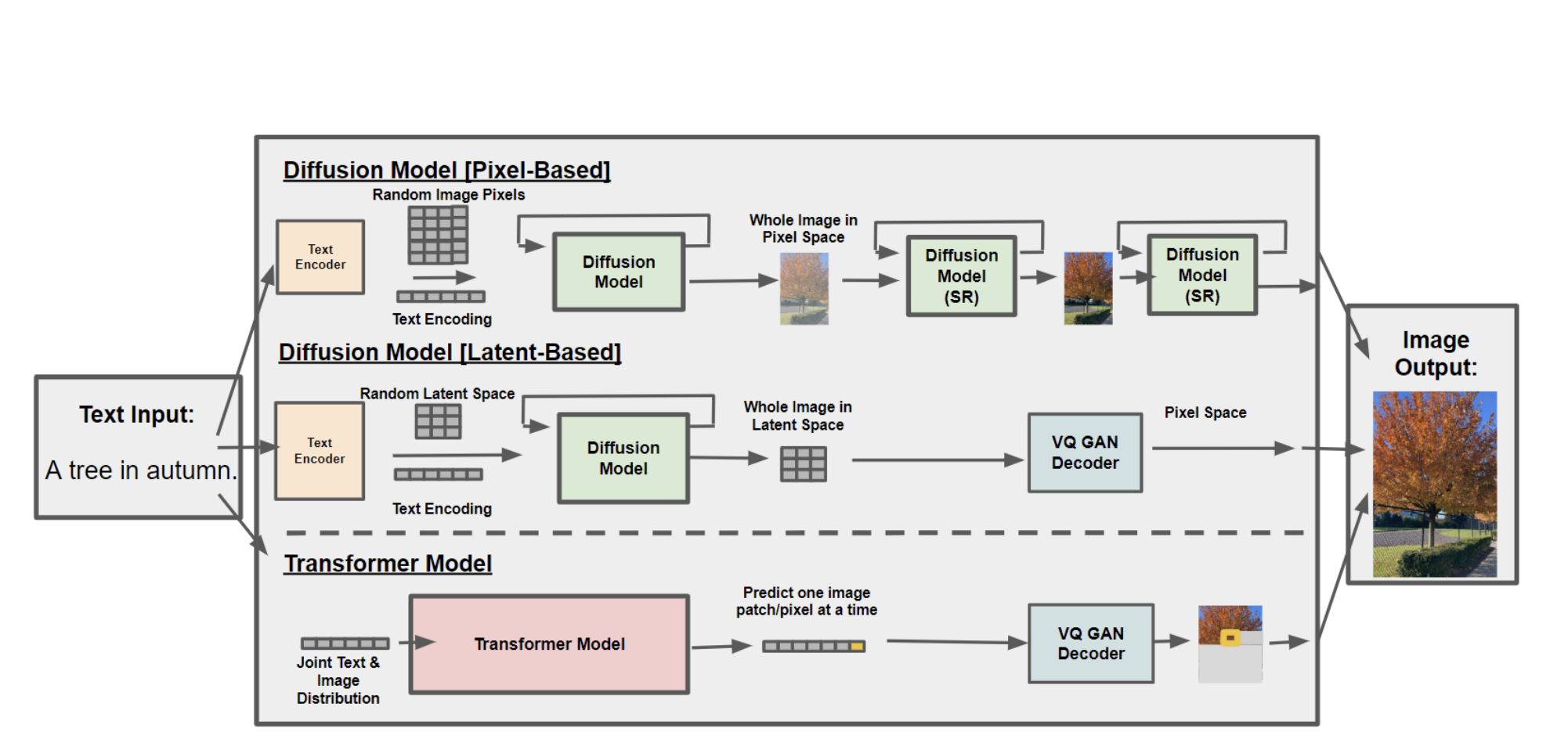
The emergence of Large Language Models (LLMs) has inspired various uses, including the development of chatbots like ChatGPT, email assistants, and coding tools. Substantial work has been directed towards enhancing the efficiency of these models for large-scale deployment. This has facilitated ChatGPT to cater to more than 100 million active users weekly. However, it must note that text generation represents only a fraction of these model’s possibilities.
The unique characteristics of Text-To-Image (TTI) and Text-To-Video (TTV) models imply that these evolving tasks experience different advantages. Consequently, a thorough examination is necessary to pinpoint areas for optimizing TTI/TTV operations. Despite notable algorithmic advancements in image and video generation models in recent years, there has been a comparatively limited effort in optimizing the deployment of these models from a systems standpoint.
Researchers at Harvard University and Meta adopt a quantitative approach to delineate the current landscape of Text-To-Image (TTI) and Text-To-Video (TTV) models by examining various design dimensions, including latency and computational intensity. To achieve this, they create a suite comprising eight representative tasks for text-to-image and video generation, contrasting these with widely utilized language models like LLaMA.
They find notable distinctions, showcasing that new system performance limitations emerge even with state-of-the-art performance optimizations like Flash Attention. For instance, Convolution accounts for up to 44% of execution time in Diffusion-based TTI models, while linear layers consume as much as 49% of execution time in Transformer-based TTI models.
Additionally, they find that the bottleneck related to Temporal Attention increases exponentially with increased frames. This observation underscores the need for future system optimizations to address this challenge. They develop an analytical framework to model the changing memory and FLOP requirements throughout the forward pass of a Diffusion model.
Large Language Models (LLMs) are defined by a sequence that denotes the extent of information the model can consider, indicating the number of words it can take into account while predicting the subsequent word. Nevertheless, in state-of-the-art Text-To-Image (TTI) and Text-To-Video (TTV) models, the sequence length is directly influenced by the size of the image being processed.
They conducted a case study on the Stable Diffusion model to more concretely understand the impact of scaling image size and demonstrate the sequence length distribution for Stable Diffusion inference. They find that after techniques such as Flash Attention are applied, Convolution has a larger scaling dependence with image size than Attention.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.