Can Language Feedback Revolutionize AI Training? This Paper Introduces Contrastive Unlikelihood Training (CUT) Framework for Enhanced LLM Alignment
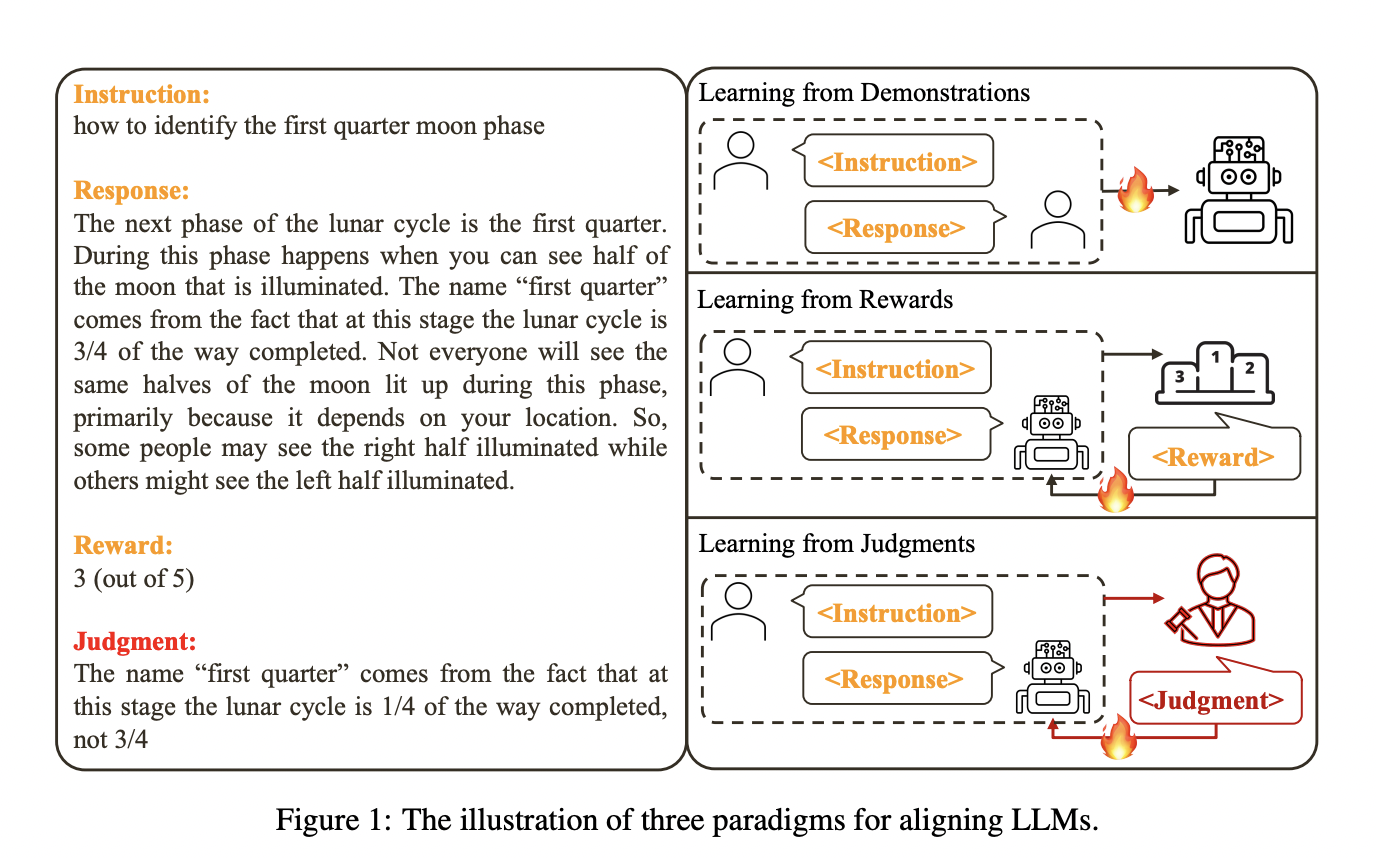
Language models, particularly large ones, have become ubiquitous in AI applications, raising the need for models that align with human values and intentions. Traditionally, alignment has been approached through methods like learning from demonstrations, where human responses guide model fine-tuning, and learning from feedback, using scalar rewards to indicate the desirability of model outputs. However, these approaches have limitations in terms of scalability and efficiency, particularly as the complexity of tasks scales up.
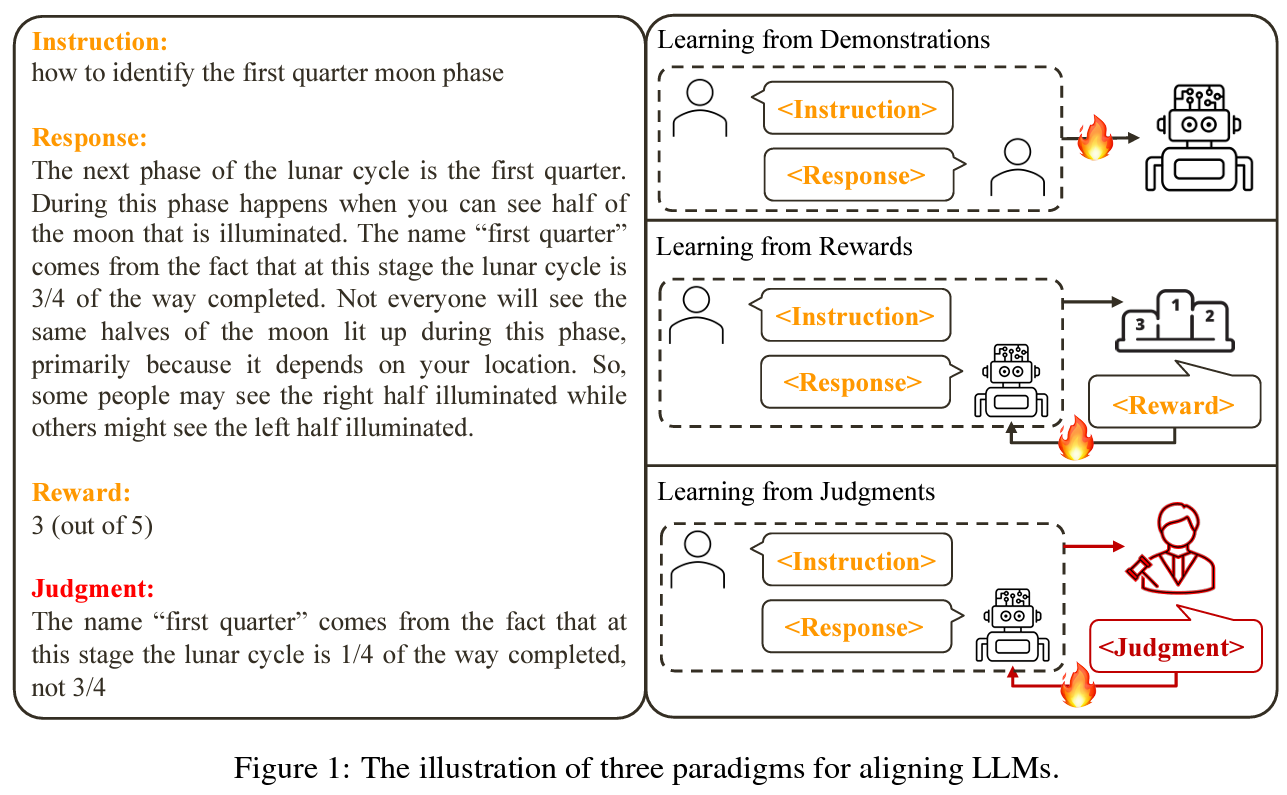
A team of researchers from Tencent AI Lab and The Chinese University of Hong Kong introduced Contrastive Unlikelihood Training (CUT) to address this challenge. This novel AI method contrasts responses generated under varying conditions, identifying and differentiating appropriate and inappropriate content. CUT combines Maximum Likelihood Estimation (MLE) for proper responses and Unlikelihood Training (UT) for inappropriate ones. This dual approach enables fine-tuning LLMs more effectively, offering a nuanced strategy that moves beyond the binary nature of previous techniques.
The CUT method operates by contrasting responses to authentic and fabricated judgments. It enables the model to distinguish between suitable and unsuitable responses more effectively. This contrast-based approach allows for a deeper understanding and rectification of errors, marking a significant advancement over traditional methods, which often struggled with nuanced judgment and correction.
In implementing CUT, researchers conducted experiments in two settings: offline alignment using pre-existing model-agnostic judgment data and online alignment, where the model learns from judgments on its own generated responses. The model was trained on various tasks for offline alignment, including general instruction following and specific NLP tasks like summarization. The performance of CUT in these scenarios was compared against baseline models and other alignment methods.
The results of implementing CUT were remarkable. In the offline setting, CUT significantly improved performance across various benchmarks. For instance, when trained with a modest amount of judgment data, the LLM fine-tuned using CUT surpassed the performance of larger models like DaVinci003 in certain evaluations. This achievement was particularly noteworthy considering the model’s size and the limited training data.
In the online alignment setting, CUT demonstrated its continuous improvement and refinement capability. The model iteratively learned from judgments on its responses, resulting in steady performance enhancements. This iterative learning process, akin to human learning, highlighted the potential of model-specific judgments for effective alignment.
These experiments underscored the effectiveness of CUT in transforming LLMs into specialist and generalist models capable of handling a variety of tasks with enhanced precision and ethical alignment. The success of CUT in these varied scenarios indicates its versatility and robustness as an alignment strategy.
In conclusion, the introduction of CUT represents a significant leap forward in AI. By effectively aligning LLMs with human judgments, CUT paves the way for developing more sophisticated, ethical, and reliable AI systems. The success of this method emphasizes the potential of nuanced, judgment-based alignment in shaping the future of AI, making it a promising avenue for future research and development in AI ethics and performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.