Alibaba Announces RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D
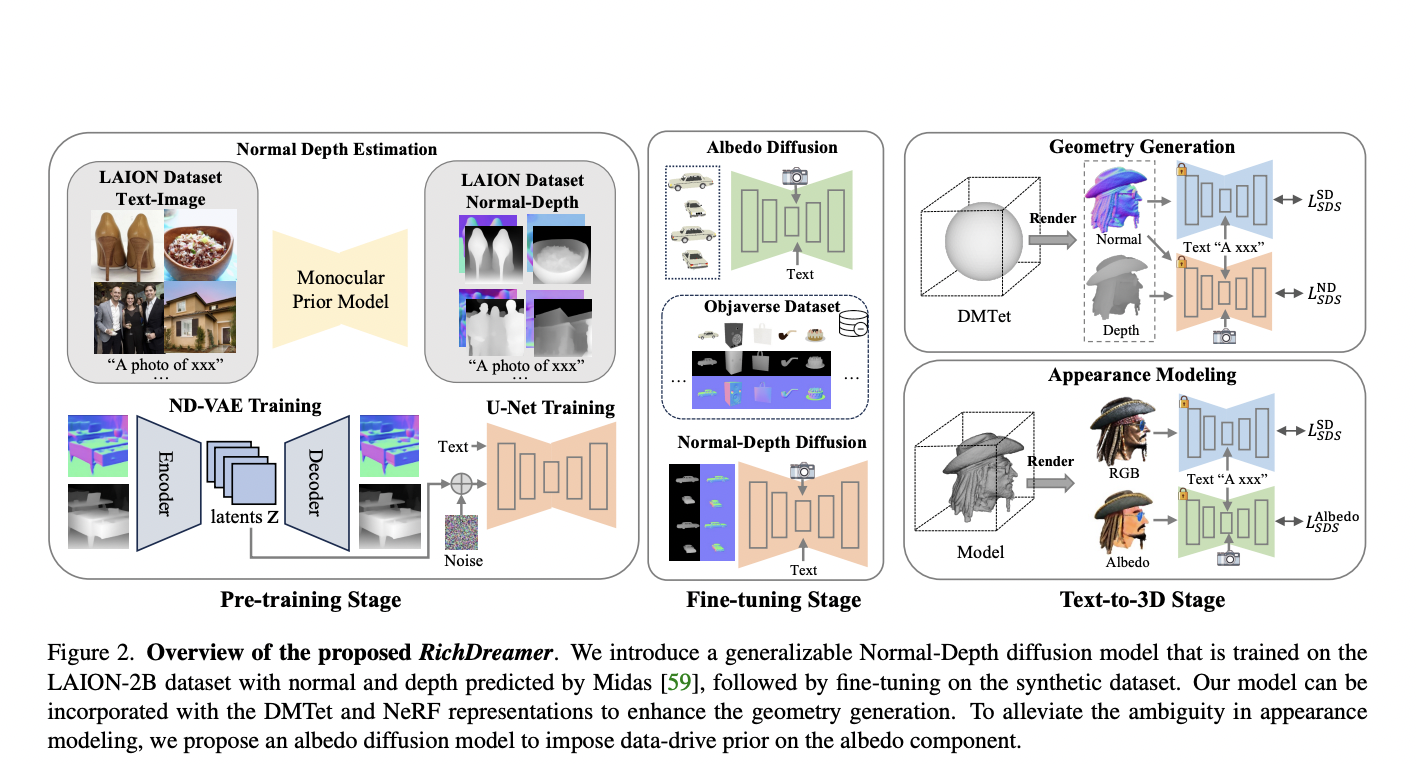
In the context of text-to-3D, the key challenge lies in lifting 2D diffusion to 3D generation. The existing methods face difficulties in creating geometry due to the absence of a geometric prior and the intricate interplay of materials and lighting in natural images. To tackle this, a team of researchers from Alibaba have proposed a Normal-Depth diffusion model named RichDreamer, designed to provide a robust geometric foundation for high-fidelity text-to-3D geometry generation.
Existing methods have shown promise by first creating the geometry through score-distillation sampling (SDS) applied to rendered surface normals, followed by appearance modeling. However, relying on a 2D RGB diffusion model to optimize surface normals is suboptimal due to the distribution discrepancy between natural images and normals maps, leading to instability in optimization. This model proposes to learn a generalizable Normal-Depth diffusion model for 3D generation.
The challenges of lifting from 2D to 3D become apparent, including multi-view constraints and the inherent coupling of surface geometry, texture, and lighting in natural images. The proposed Normal-Depth diffusion model aims to overcome these challenges by learning a joint distribution of normal and depth information, effectively describing scene geometry. The model is trained on the extensive LAION dataset, showcasing remarkable generalization abilities. The team fine-tunes the model on a synthetic dataset, demonstrating its capability to learn diverse distributions of normal and depth in real-world scenes.
To address mixed illumination effects in generated materials, an albedo diffusion model is introduced to impose data-driven constraints on the albedo component. This enhances the disentanglement of reflectance and illumination effects, contributing to more accurate and detailed results.
The geometry generation process involves score distillation sampling (SDS) and the integration of the proposed Normal-Depth diffusion model into the Fantasia3D pipeline. The team explores the use of the model for optimizing Neural Radiance Fields (NeRF) and demonstrates its effectiveness in enhancing geometric reconstructions.
The appearance modeling aspect involves a Physically-Based Rendering (PBR) Disney material model, and the researchers introduce an albedo diffusion model for improved material generation. The evaluation of the proposed method demonstrates superior performance in both geometry and textured model generation compared to state-of-the-art approaches.
In conclusion, the research team presents a pioneering approach to 3D generation through the introduction of a Normal-Depth diffusion model, addressing critical challenges in text-to-3D modeling. The method showcases significant improvements in geometry and appearance modeling, setting a new standard in the field. Future directions include extending the approach to text-to-scene generation and exploring additional aspects of appearance modeling.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.