Do Language Models Know When They Are Hallucinating? This AI Research from Microsoft and Columbia University Explores Detecting Hallucinations with the Creation of Probes
Large Language Models (LLMs), the latest innovation of Artificial Intelligence (AI), use deep learning techniques to produce human-like text and perform various Natural Language Processing (NLP) and Natural Language Generation (NLG) tasks. Trained on large amounts of textual data, these models perform various tasks, including generating meaningful responses to questions, text summarization, translations, text-to-text transformation, and code completion.
In recent research, a team of researchers has studied hallucination detection in grounded generation tasks with a special emphasis on language models, especially the decoder-only transformer models. Hallucination detection aims to ascertain whether the generated text is true to the input prompt or contains false information.
In recent research, a team of researchers from Microsoft and Columbia University has addressed the construction of probes for the model to anticipate a transformer language model’s hallucinatory behavior during in-context creation tasks. The main focus has been on using the model’s internal representations for the detection and a dataset with annotations for both synthetic and biological hallucinations.
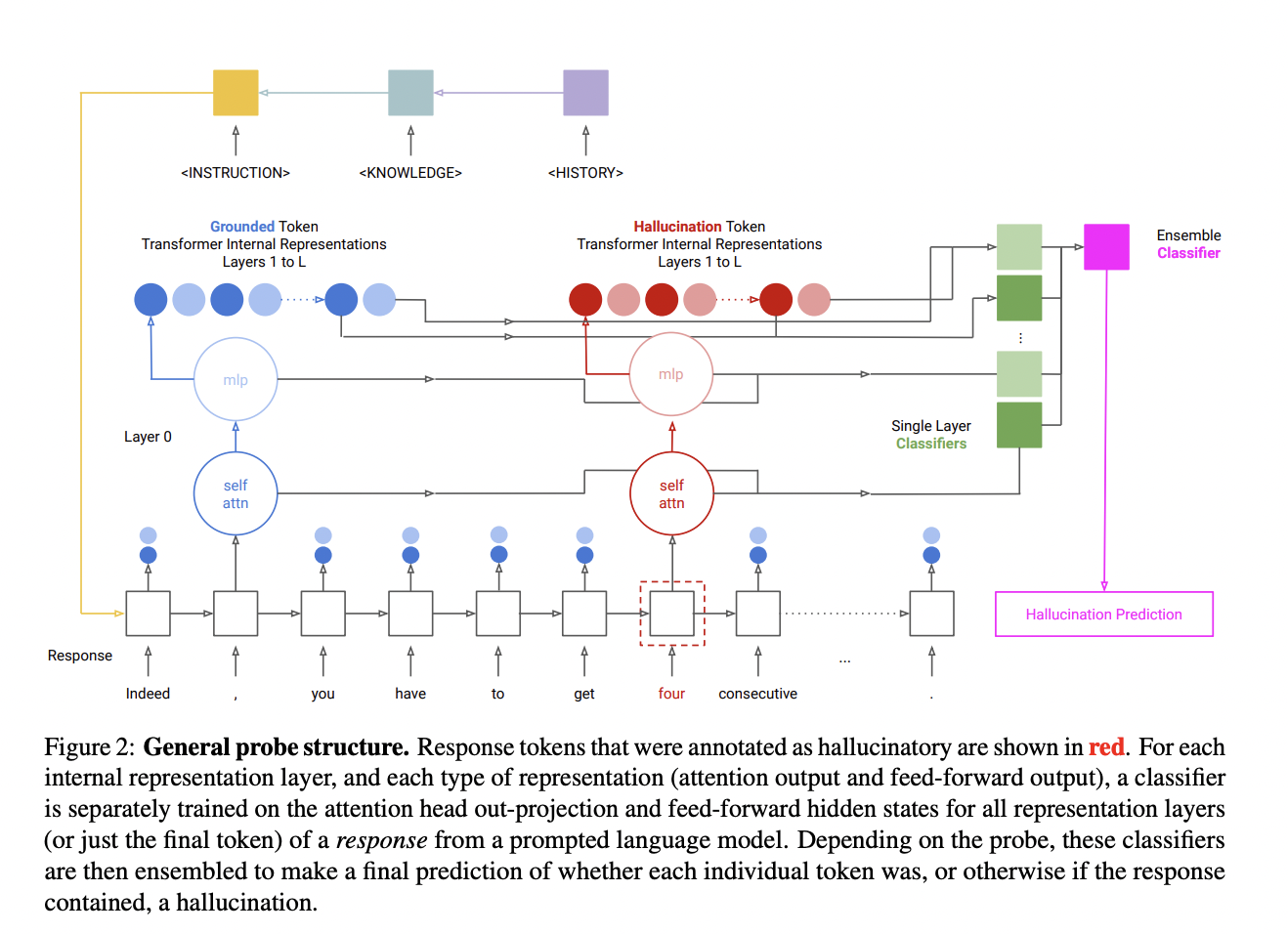
Probes are basically the instruments or systems trained on the language model’s internal operations. Their job is to predict when the model might provide delusional material when doing tasks involving the development of contextually appropriate content. For training and assessing these probes, it is imperative to provide a span-annotated dataset containing examples of synthetic hallucinations, purposely induced disparities in reference inputs, and organic hallucinations derived from the model’s own outputs.
The research has shown that probes designed to identify force-decoded states of artificial hallucinations are not very effective at identifying biological hallucinations. This shows that when trained on modified or synthetic instances, the probes may not generalize well to real-world, naturally occurring hallucinations. The team has shared that the distribution properties and task-specific information impact the hallucination data in the model’s hidden states.
The team has analyzed the intricacy of intrinsic and extrinsic hallucination saliency across various tasks, hidden state kinds, and layers. The transformer’s internal representations emphasize extrinsic hallucinations- i.e., those connected to the outside world more. Two methods have been used to gather hallucinations which include using sampling replies produced by an LLM conditioned on inputs and introducing inconsistencies into reference inputs or outputs by editing.
The outputs of the second technique have been reported to elicit a higher rate of hallucination annotations by human annotators; however, synthetic examples are considered less valuable because they do not match the test distribution.
The team has summarized their primary contributions as follows.
- A dataset with more than 15,000 utterances has been produced that have been tagged for hallucinations in both natural and artificial output texts. The dataset covers three grounded generation tasks.
- Three probe architectures have been presented for the efficient detection of hallucinations, which demonstrate improvements in efficiency and accuracy for detecting hallucinations over several current baselines.
- The study has explored the elements that affect the accuracy of the probe, such as the nature of the hallucinations, i.e., intrinsic vs. extrinsic, the size of the model, and the particular encoding components that are being probed.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.