Microsoft Researchers Unveil CodeOcean and WaveCoder: Pioneering the Future of Instruction Tuning in Code Language Models
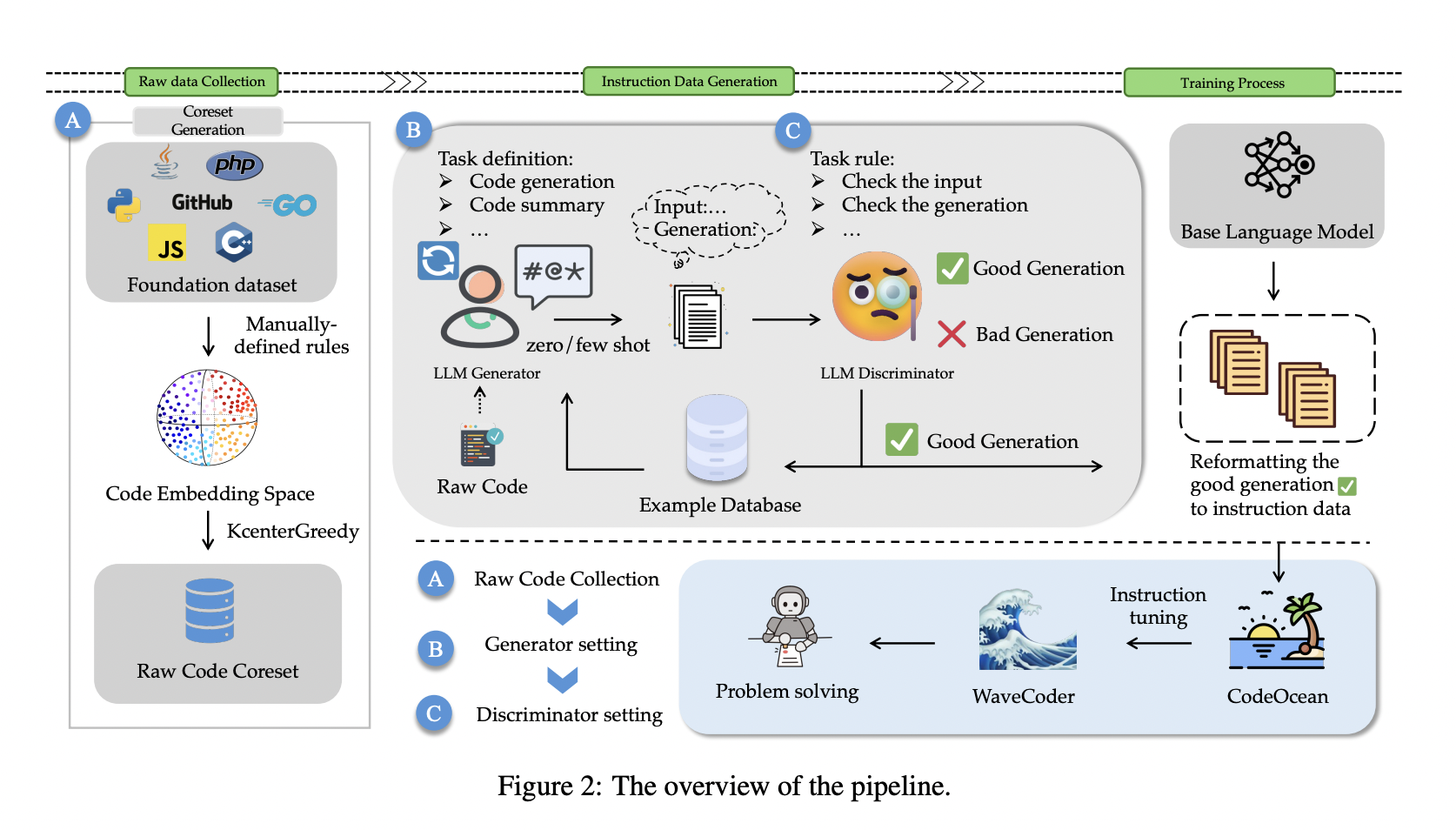
Researchers from Microsoft have introduced a novel approach to generate diverse, high-quality instruction data from open-source code, thereby improving the effectiveness of instruction tuning and the generalization ability of fine-tuned models. Thereby, it addresses the challenges in instruction data generation, such as duplicate data and insufficient control over data quality. The proposed method involves classifying instruction data into four universal code-related tasks and introduces a Language Model (LLM) based Generator-Discriminator data processing framework called CodeOcean.
The researchers present CodeOcean, a dataset comprising 20,000 instruction instances across four code-related tasks: Code Summarization, Code Generation, Code Translation, and Code Repair. The goal is to augment the performance of Code LLMs through instruction tuning. This research study also introduces WaveCoder, a fine-tuned Code LLM with Widespread And Versatile Enhanced instruction tuning. WaveCoder is designed to enhance instruction tuning for Code LLMs and exhibits superior generalization ability across different code-related tasks compared to other open-source models at the same fine-tuning scale.
It is built on recent advancements in Large Language Models (LLMs), emphasizing the significant potential of instruction tuning in improving model capabilities for a range of tasks. Instruction tuning has proven effective in enhancing the generalization abilities of LLMs across diverse tasks, as seen in studies such as FLAN, ExT5, and FLANT5. The research introduces the concept of alignment, wherein pre-trained models, having learned from self-supervised tasks, can comprehend text inputs. Instruction tuning provides instruction-level tasks, allowing pre-trained models to extract more information from instructions and enhance their interactive abilities with users.
Existing methods for generating instructional data, including self-instruct and evol-instruct, rely on the performance of teacher LLMs and may produce duplicate data. The proposed LLM Generator-Discriminator framework leverages source code, explicitly controlling data quality during the generation process. The method generates more realistic instruction data by taking raw code as input and selecting a core dataset while controlling data diversity through raw code distribution adjustments.
The study classifies instruction instances into four code-related tasks and refines the instruction data to create CodeOcean. The authors introduce WaveCoder models, fine-tuned with CodeOcean, and demonstrate superior generalization abilities compared to other open-source models. WaveCoder exhibits high efficiency in code generation tasks and provides significant contributions to instruction data generation and fine-tuning models for improved performance in code-related tasks.
WaveCoder models consistently outperform other models on various benchmarks, including HumanEval, MBPP, and HumanEvalPack. The research emphasizes the importance of data quality and diversity in the instruction-tuning process. WaveCoder’s performance is evaluated across code generation, repair, and summarization tasks, showcasing its effectiveness in diverse scenarios. A comparison with the CodeAlpaca dataset highlights CodeOcean’s superiority in refining instruction data and enhancing the instruction-following ability of base models.
In conclusion, the research introduces a multi-task instruction data approach, CodeOcean, and WaveCoder models to enhance the generalization ability of Code LLMs. The proposed LLM Generator-Discriminator framework proves effective in generating realistic, diverse instruction data, contributing to improved performance across various code-related tasks. Future work may explore the interplay among different tasks and larger datasets to further enhance mono-task performance and generalization abilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.