Self-Attention Guidance: Improving Sample Quality of Diffusion Models

Denoising Diffusion Models are generative AI frameworks that synthesize images from noise through an iterative denoising process. They are celebrated for their exceptional image generation capabilities and diversity, largely attributed to text- or class-conditional guidance methods, including classifier guidance and classifier-free guidance. These models have been notably successful in creating diverse, high-quality images. Recent studies have shown that guidance techniques like class captions and labels play a crucial role in enhancing the quality of images these models generate.
However, diffusion models and guidance methods face limitations under certain external conditions. The Classifier-Free Guidance (CFG) method, which uses label dropping, adds complexity to the training process, while the Classifier Guidance (CG) method necessitates additional classifier training. Both methods are somewhat constrained by their reliance on hard-earned external conditions, limiting their potential and confining them to conditional settings.
To address these limitations, developers have formulated a more general approach to diffusion guidance, known as Self-Attention Guidance (SAG). This method leverages information from intermediate samples of diffusion models to generate images. We will explore SAG in this article, discussing its workings, methodology, and results compared to current state-of-the-art frameworks and pipelines.
Denoising Diffusion Models (DDMs) have gained popularity for their ability to create images from noise via an iterative denoising process. The image synthesis prowess of these models is largely due to the employed diffusion guidance methods. Despite their strengths, diffusion models and guidance-based methods face challenges like added complexity and increased computational costs.
To overcome the current limitations, developers have introduced the Self-Attention Guidance method, a more general formulation of diffusion guidance that does not rely on the external information from diffusion guidance, thus facilitating a condition-free and flexible approach to guide diffusion frameworks. The approach opted by Self-Attention Guidance ultimately helps in enhancing the applicability of the traditional diffusion-guidance methods to cases with or without external requirements.
Self-Attention Guidance is based on the simple principle of generalized formulation, and the assumption that internal information contained within intermediate samples can serve as guidance as well. On the basis of this principle, the SAG method first introduces Blur Guidance, a simple and straightforward solution to improve sample quality. Blur guidance aims to exploit the benign properties of Gaussian blur to remove fine-scale details naturally by guiding intermediate samples using the eliminated information as a result of Gaussian blur. Although the Blur guidance method does boost the sample quality with a moderate guidance scale, it fails to replicate the results on a large guidance scale as it often introduces structural ambiguity in entire regions. As a result, the Blur guidance method finds it difficult to align the original input with the prediction of the degraded input. To enhance the stability and effectiveness of the Blur guidance method on a larger guidance scale, the Self-Attention Guidance attempts to exploit the self-attention mechanism of the diffusion models as modern diffusion models already contain a self-attention mechanism within their architecture.
With the assumption that self-attention is essential to capture salient information at its core, the Self-Attention Guidance method uses self-attention maps of the diffusion models to adversarially blur the regions containing salient information, and in the process, guides the diffusion models with required residual information. The method then leverages the attention maps during diffusion models’ reverse process, to boost the quality of the images and uses self-conditioning to reduce the artifacts without requiring additional training or external information.

To sum it up, the Self-Attention Guidance method
- Is a novel approach that uses internal self-attention maps of diffusion frameworks to improve the generated sample image quality without requiring any additional training or relying on external conditions.
- The SAG method attempts to generalize conditional guidance methods into a condition-free method that can be integrated with any diffusion model without requiring additional resources or external conditions, thus enhancing the applicability of guidance-based frameworks.
- The SAG method also attempts to demonstrate its orthogonal abilities to existing conditional methods and frameworks, thus facilitating a boost in performance by facilitating flexible integration with other methods and models.
Moving along, the Self-Attention Guidance method learns from the findings of related frameworks including Denoising Diffusion Models, Sampling Guidance, Generative AI Self-Attention methods, and Diffusion Models’ Internal Representations. However, at its core, the Self-Attention Guidance method implements the learnings from DDPM or Denoising Diffusion Probabilistic Models, Classifier Guidance, Classifier-free Guidance, and Self-Attention in Diffusion frameworks. We will be talking about them in-depth in the upcoming section.
Self-Attention Guidance : Preliminaries, Methodology, and Architecture
Denoising Diffusion Probabilistic Model or DDPM
DDPM or Denoising Diffusion Probabilistic Model is a model that uses an iterative denoising process to recover an image from white noise. Traditionally, a DDPM model receives an input image and a variance schedule at a time step to obtain the image using a forward process known as the Markovian process.
Classifier and Classifier-Free Guidance with GAN Implementation
GAN or Generative Adversarial Networks possess unique trading diversity for fidelity, and to bring this ability of GAN frameworks to diffusion models, the Self-Attention Guidance framework proposes to use a classifier guidance method that uses an additional classifier. Conversely, a classifier-free guidance method can also be implemented without the use of an additional classifier to achieve the same results. Although the method delivers the desired results, it is still not computationally viable as it requires additional labels, and also confines the framework to conditional diffusion models that require additional conditions like a text or a class along with additional training details that adds to the complexity of the model.
Generalizing Diffusion Guidance
Although Classifier and Classifier-free Guidance methods deliver the desired results and help with conditional generation in diffusion models, they are dependent on additional inputs. For any given timestep, the input for a diffusion model comprises a generalized condition and a perturbed sample without the generalized condition. Furthermore, the generalized condition encompasses internal information within the perturbed sample or an external condition, or even both. The resultant guidance is formulated with the utilization of an imaginary regressor with the assumption that it can predict the generalized condition.
Improving Image Quality using Self-Attention Maps
The Generalized Diffusion Guidance implies that it is feasible to provide guidance to the reverse process of diffusion models by extracting salient information in the generalized condition contained in the perturbed sample. Building on the same, the Self-Attention Guidance method captures the salient information for reverse processes effectively while limiting the risks that arise as a result of out-of-distribution issues in pre-trained diffusion models.
Blur Guidance
Blur guidance in Self-Attention Guidance is based on Gaussian Blur, a linear filtering method in which the input signal is convolved with a Gaussian filter to generate an output. With an increase in the standard deviation, Gaussian Blur reduces the fine-scale details within the input signals, and results in locally indistinguishable input signals by smoothing them towards the constant. Furthermore, experiments have indicated an information imbalance between the input signal, and the Gaussian blur output signal where the output signal contains more fine-scale information.
On the basis of this learning, the Self-Attention Guidance framework introduces Blur guidance, a technique that intentionally excludes the information from intermediate reconstructions during the diffusion process, and instead, uses this information to guide its predictions towards increasing the relevancy of images to the input information. Blur guidance essentially causes the original prediction to deviate more from the blurred input prediction. Furthermore, the benign property in Gaussian blur prevents the output signals from deviating significantly from the original signal with a moderate deviation. In simple words, blurring occurs in the images naturally that makes the Gaussian blur a more suitable method to be applied to pre-trained diffusion models.
In the Self-Attention Guidance pipeline, the input signal is first blurred using a Gaussian filter, and it is then diffused with additional noise to produce the output signal. By doing this, the SAG pipeline mitigates the side effect of the resultant blur that reduces Gaussian noise, and makes the guidance rely on content rather than being dependent on random noise. Although blur guidance delivers satisfactory results on frameworks with moderate guidance scale, it fails to replicate the results on existing models with a large guidance scale as it gets prone to produce noisy results as demonstrated in the following image.

These results might be a result of the structural ambiguity introduced in the framework by global blur that makes it difficult for the SAG pipeline to align the predictions of the original input with the degraded input, resulting in noisy outputs.
Self-Attention Mechanism
As mentioned earlier, diffusion models usually have an in-build self-attention component, and it is one of the more essential components in a diffusion model framework. The Self-Attention mechanism is implemented at the core of the diffusion models, and it allows the model to pay attention to the salient parts of the input during the generative process as demonstrated in the following image with high-frequency masks in the top row, and self-attention masks in the bottom row of the finally generated images.

The proposed Self-Attention Guidance method builds on the same principle, and leverages the capabilities of self-attention maps in diffusion models. Overall, the Self-Attention Guidance method blurs the self-attended patches in the input signal or in simple words, conceals the information of patches that is attended to by the diffusion models. Furthermore, the output signals in Self-Attention Guidance contain intact regions of the input signals meaning that it does not result in structural ambiguity of the inputs, and solves the problem of global blur. The pipeline then obtains the aggregated self-attention maps by conducting GAP or Global Average Pooling to aggregate self-attention maps to the dimension, and up-sampling the nearest-neighbor to match the resolution of the input signal.
Self-Attention Guidance : Experiments and Results
To evaluate its performance, the Self-Attention Guidance pipeline is sampled using 8 Nvidia GeForce RTX 3090 GPUs, and is built upon pre-trained IDDPM, ADM, and Stable Diffusion frameworks.
Unconditional Generation with Self-Attention Guidance
To measure the effectiveness of the SAG pipeline on unconditional models and demonstrate the condition-free property not possessed by Classifier Guidance, and Classifier Free Guidance approach, the SAG pipeline is run on unconditionally pre-trained frameworks on 50 thousand samples.

As it can be observed, the implementation of the SAG pipeline improves the FID, sFID, and IS metrics of unconditional input while lowering the recall value at the same time. Furthermore, the qualitative improvements as a result of implementing the SAG pipeline is evident in the following images where the images on the top are results from ADM and Stable Diffusion frameworks whereas the images at the bottom are results from the ADM and Stable Diffusion frameworks with the SAG pipeline.


Conditional Generation with SAG
The integration of SAG pipeline in existing frameworks delivers exceptional results in unconditional generation, and the SAG pipeline is capable of condition-agnosticity that allows the SAG pipeline to be implemented for conditional generation as well.
Stable Diffusion with Self-Attention Guidance
Even though the original Stable Diffusion framework generates high quality images, integrating the Stable Diffusion framework with the Self-Attention Guidance pipeline can enhance the results drastically. To evaluate its effect, developers use empty prompts for Stable Diffusion with random seed for each image pair, and use human evaluation on 500 pairs of images with and without Self-Attention Guidance. The results are demonstrated in the following image.

Furthermore, the implementation of SAG can enhance the capabilities of the Stable Diffusion framework as fusing Classifier-Free Guidance with Self-Attention Guidance can broaden the range of Stable Diffusion models to text-to-image synthesis. Furthermore, the generated images from the Stable Diffusion model with Self-Attention Guidance are of higher quality with lesser artifacts thanks to the self-conditioning effect of the SAG pipeline as demonstrated in the following image.

Current Limitations
Although the implementation of the Self-Attention Guidance pipeline can substantially improve the quality of the generated images, it does have some limitations.
One of the major limitations is the orthogonality with Classifier-Guidance and Classifier-Free Guidance. As it can be observed in the following image, the implementation of SAG does improve the FID score and prediction score that means that the SAG pipeline contains an orthogonal component that can be used with traditional guidance methods simultaneously.

However, it still requires diffusion models to be trained in a specific manner that adds to the complexity as well as computational costs.
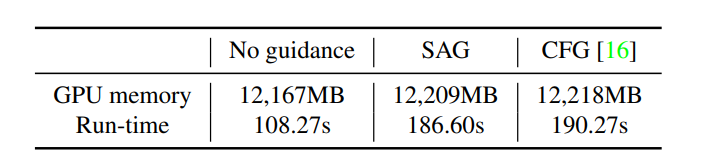
Furthermore, the implementation of Self-Attention Guidance does not increase the memory or time consumption, an indication that the overhead resulting from the operations like masking & blurring in SAG is negligible. However, it still adds to the computational costs as it includes an additional step when compared to no guidance approaches.
Final Thoughts
In this article, we have talked about Self-Attention Guidance, a novel and general formulation of guidance method that makes use of internal information available within the diffusion models for generating high-quality images. Self-Attention Guidance is based on the simple principle of generalized formulation, and the assumption that internal information contained within intermediate samples can serve as guidance as well. The Self-Attention Guidance pipeline is a condition-free and training-free approach that can be implemented across various diffusion models, and uses self-conditioning to reduce the artifacts in the generated images, and boosts the overall quality.
Credit: Source link
Comments are closed.