A New AI Research Introduces LoRAMoE: A Plugin Version of Mixture of Experts (Moe) for Maintaining World Knowledge in Language Model Alignment
Large Language Models (LLMs) have proven remarkably effective in numerous jobs. To fully realize the potential of the models, supervised fine-tuning (SFT) is necessary to match them with human instructions. A simple option when the variety of tasks increases or when improved performance on a particular activity is needed is to increase the amount of data, even if some works have shown that models can follow human instruction successfully with a little fine-tuning of data.
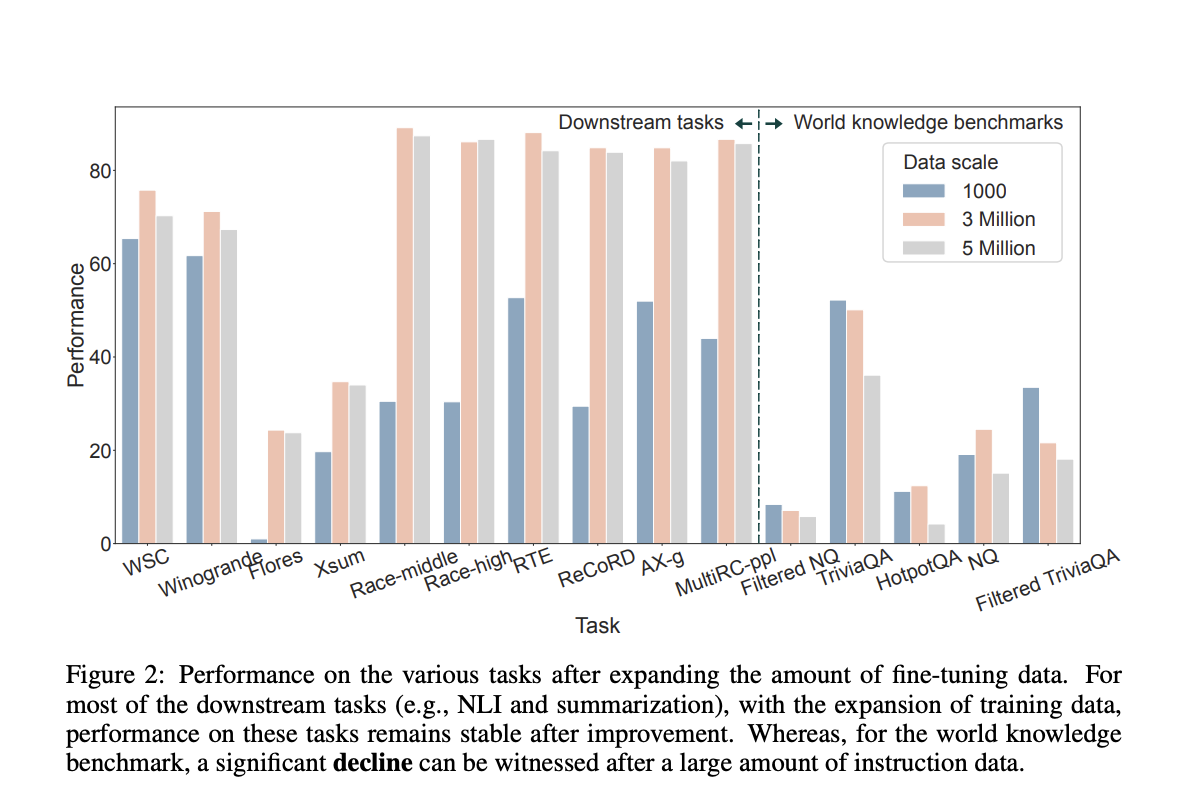
Several studies show that the significant growth of fine-tuning data presents new difficulties. In particular, researchers have found that performance significantly decreases with significant increases in fine-tuning data on the Natural Questions dataset from the Closed-Book Question Answering (CBQA) dataset. The collapse of previously learned and stored world knowledge in the pre-trained models could be linked to this notable performance loss. There are two phases involved in proving this proposition. Firstly, the CBQA dataset draws conclusions from the world information in the models. Second, large-scale fine-tuning can significantly alter the model’s parameters, erasing world information (i.e., knowledge forgetting), which is responsible for the notable decline in performance on the CBQA dataset. There is a conflict in vanilla-supervised fine-tuning between preserving LLM world information and enhancing performance on downstream tasks concurrently.
The best course of action is to designate a certain area of the model for storing global information, much like the human brain’s hippocampus, which is specialized for remembering. Nonetheless, direct and fine-tuning with a single plugin are comparable in form. An architecture known as a “Mixture of Experts” (MoE) includes several experts, and data with varying properties is sent to the appropriate experts for personalized processing. Using this concept, a group of researchers from Fudan University and Hikvision Inc. intend to offer numerous plugins as experts, enabling one portion to access the backup and another to carry out downstream operations.
Their new study presents LoRAMoE, which can improve the LLMs’ downstream task-solving capacities and mitigate the forgetting of world knowledge. A plugin version of MoE is called LoRAMoE. Introducing numerous parallel plugins that are specialists in every feed-forward layer and coupling them to routers modifies the model’s architecture. Next, they suggest creating separate groups of experts for each LoRAMoE layer using localized balancing constraints. To be more precise, one group works on downstream tasks, and the other is tasked with reducing knowledge forgetting by aligning human instructions with the world information included in the backbone model. Furthermore, the localized balancing constraint prohibits the routers from placing too much weight on only a few experts within the same expert group by balancing the relevance of all experts within the same expert group. It allows multiple professionals to work together, enhancing the capacity to complete jobs later.
The experiment results demonstrate that LoRAMoE can successfully prevent large-scale fine-tuning from upsetting the world information included in language models. Furthermore, by visualizing the expert weight for tasks, the team validated LoRAMoE’s efficacy on capacity localization at an interpretable level. The findings indicate that the router prioritizes the output of experts who specialize in completing world knowledge benchmarks. On the other hand, the router concentrates on specialists from a different group for other downstream duties. LoRAMoE successfully settles the dispute by encouraging expert cooperation. Furthermore, the experiment results indicate that the proposed strategy improves learning on various downstream tasks, suggesting the method’s potential for multi-task learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.