Meet MobileVLM: A Competent Multimodal Vision Language Model (MMVLM) Targeted to Run on Mobile Devices
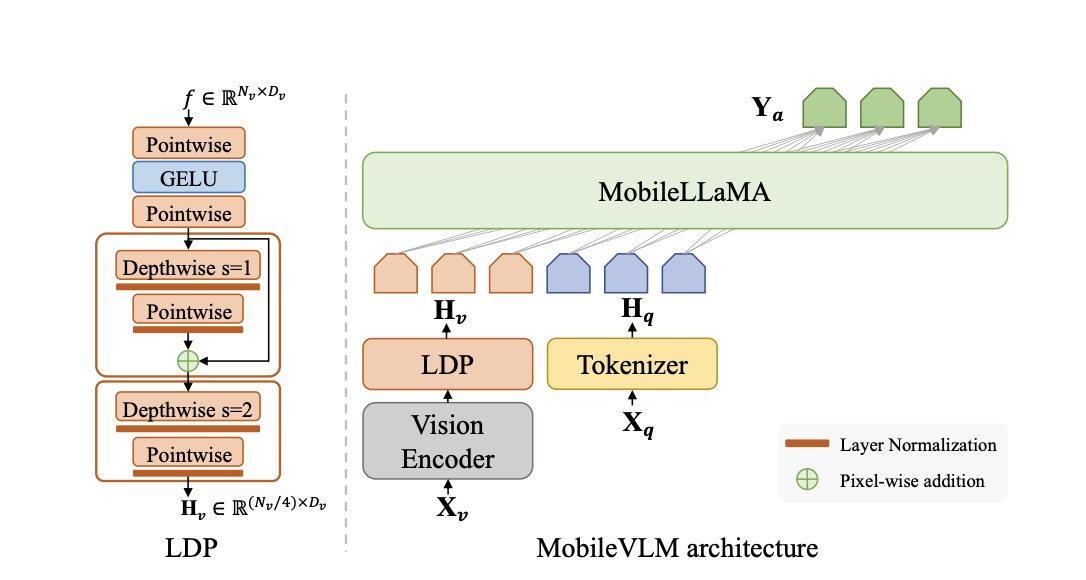
A promising new development in artificial intelligence called MobileVLM, designed to maximize the potential of mobile devices, has emerged. This cutting-edge multimodal vision language model (MMVLM) represents a major advancement in incorporating AI into common technology since it is built to function effectively in mobile situations.
Researchers from Meituan Inc., Zhejiang University, and Dalian University of Technology spearheaded the creation of MobileVLM to address the difficulties in integrating LLMs with vision models for tasks like visual question answering and image captioning, particularly in situations with limited resources. The traditional method of using large datasets created a barrier that hindered the development of text-to-video generating models. By employing regulated and open-source datasets, MobileVLM gets around this and makes it possible to construct high-performance models without being limited by large amounts of data.
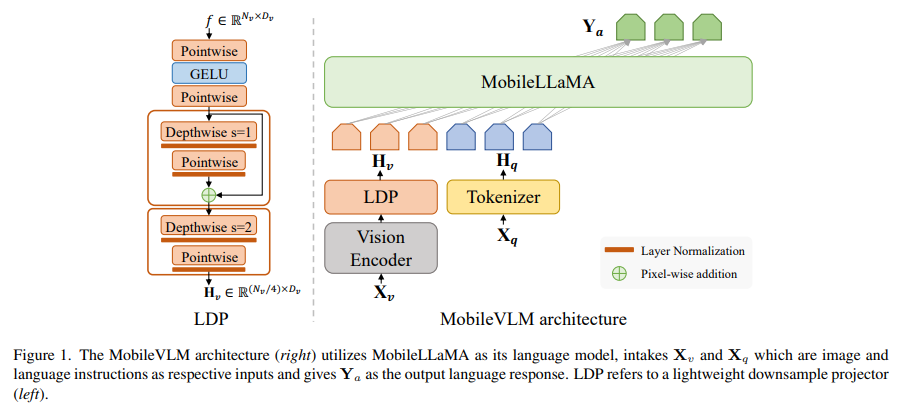
The architecture of MobileVLM is a fusion of innovative design and practical application. It comprises a visual encoder, a language model tailored for edge devices, and an efficient projector. This projector is crucial in aligning graphic and text features and is designed to minimize computational costs while maintaining spatial information. The model significantly reduces the number of visual tokens, enhancing the inference speed without compromising output quality.
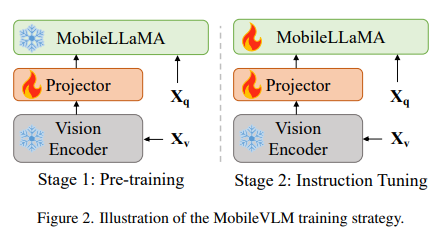
The training process of MobileVLM involves three key stages. Initially, language model foundation models are pre-trained on a text-only dataset. This is followed by supervised fine-tuning using multi-turn dialogues between humans and ChatGPT. The final stage involves training vision large models with multimodal datasets. This comprehensive training strategy ensures that MobileVLM is efficient and robust in its performance.
The performance of MobileVLM on language understanding and common sense reasoning benchmarks is noteworthy. It competes favorably with existing models, demonstrating its efficacy in language processing and reasoning tasks. MobileVLM’s performance on various vision language model benchmarks underscores its potential. Despite its reduced parameters and reliance on limited training data, it achieves results comparable to larger, more resource-intensive models.
In conclusion, MobileVLM stands out for several reasons:
- It efficiently bridges the gap between large language and vision models, enabling advanced multimodal interactions on mobile devices.
- The innovative architecture, comprising an efficient projector and tailored language model, optimizes performance and speed.
- MobileVLM’s training process, involving pre-training, fine-tuning, and using multimodal datasets, contributes to its robustness and adaptability.
- It demonstrates competitive performance on various benchmarks, indicating its potential in real-world applications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.