This AI Paper from Meta Introduces Hyper-VolTran: A Novel Neural Network for Transformative 3D Reconstruction and Rendering
In the swiftly evolving domain of computer vision, the breakthrough in transforming a single image into a 3D object structure is a beacon of innovation. This technology, pivotal in applications like novel view synthesis and robotic vision, grapples with a significant challenge: reconstructing 3D objects from limited perspectives, particularly from a single viewpoint. The task is inherently complex due to the need for more information about unseen aspects of the object.
Historically, neural 3D reconstruction methods relied on multiple images, requiring consistent views, appearances, and accurate camera parameters. Despite their efficacy, these methods are constrained by their need for extensive data and specific camera positioning, making them less adaptable to varied real-world scenarios where such detailed input may not be accessible.
Advancements in generative models, especially diffusion models, have shown promise in mitigating these challenges by acting as a strong base for unseen perspectives, aiding the 3D reconstruction process. However, these methods still necessitate per-scene optimization, which is time-intensive and limits practical utility.
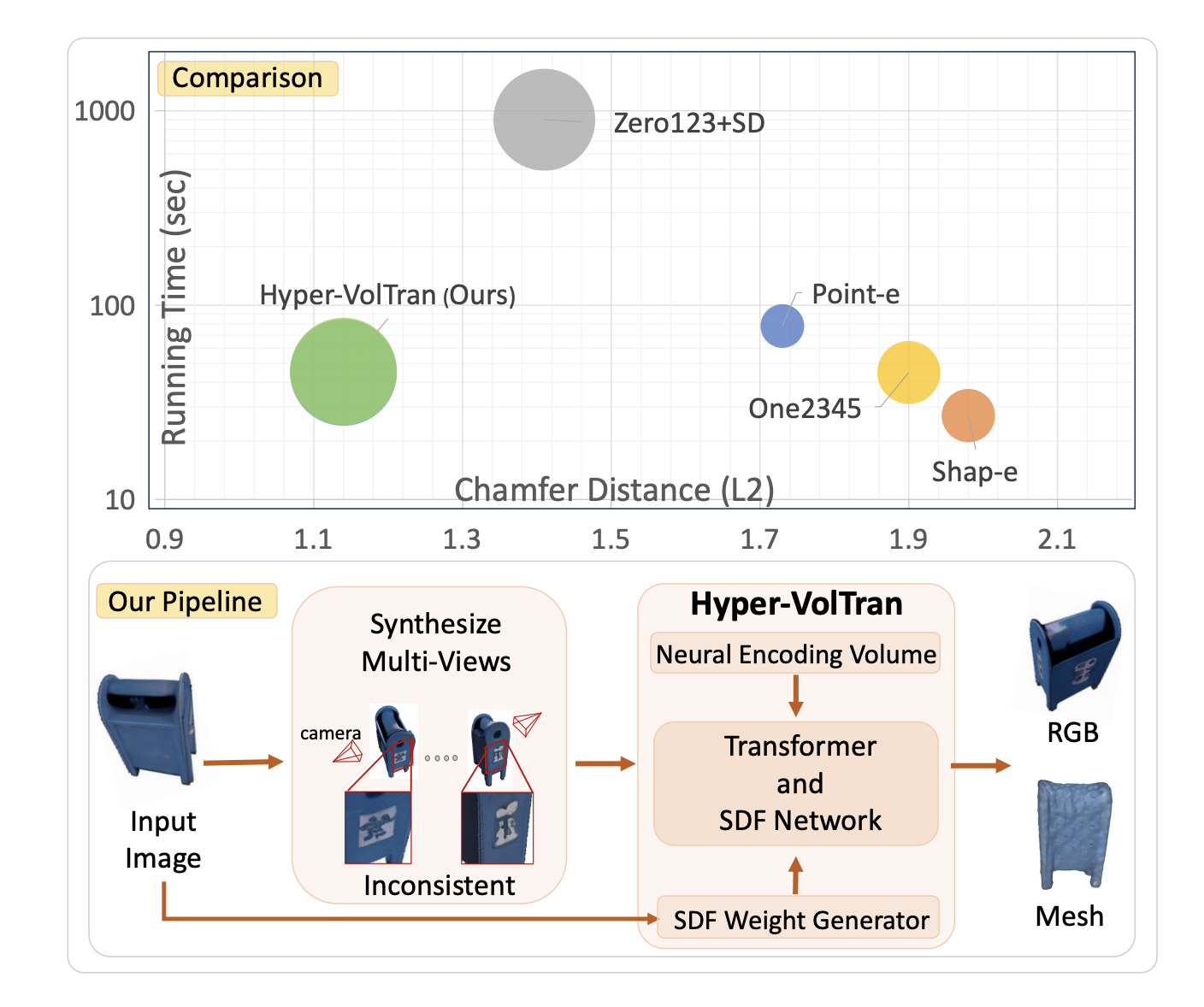
To address these limitations, a method known as Hyper-VolTran has been introduced by researchers from Meta AI. This approach integrates the strengths of HyperNetworks with a Volume Transformer (VolTran) module, significantly diminishing the need for per-scene optimization and enabling more rapid and efficient 3D reconstruction. The process begins by generating multi-view images from a single input, which are then used to construct neural encoding volumes. These volumes assist in accurately modeling the 3D geometry of the object.
HyperNetworks dynamically assigns weights to the Signed Distance Function (SDF) network, enhancing adaptability to new scenes. The SDF network is crucial for accurately representing 3D surfaces. The Volume Transformer module aggregates image features from multiple viewpoints, improving consistency and quality in the 3D reconstruction.
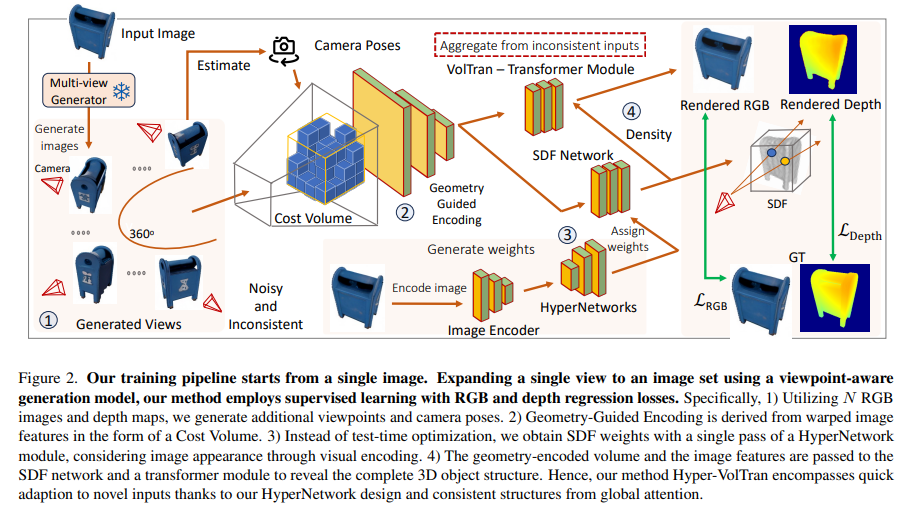
Hyper-VolTran excels in generalizing to unseen objects, delivering consistent and rapid results. This method marks a significant advance in neural 3D reconstruction, offering a practical and efficient solution for creating 3D models from single images. It opens new avenues in various applications, making it a valuable tool for future innovations in computer vision and related fields.
In conclusion, the key takeaways of Hyper-VolTran include:
- Innovative HyperNetworks and Volume Transformer module combination for efficient 3D reconstruction from single images.
- The need for per-scene optimization significantly reduces, leading to faster and more practical applications.
- Successful generalization to new objects, showcasing versatility and adaptability.
- Enhanced quality and consistency in 3D models facilitated by aggregating features from synthesized multi-view images.
- Potential for broad application in various fields, paving the way for further advancements in computer vision technology.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.