This Paper Explores Deep Learning Strategies for Running Advanced MoE Language Models on Consumer-Level Hardware

With the widespread adoption of Large Language Models (LLMs), the quest for efficient ways to run these models on consumer hardware has gained prominence. One promising strategy involves using sparse mixture-of-experts (MoE) architectures, where only selected model layers are active for a given input. This characteristic allows MoE-based language models to generate tokens faster than their denser counterparts. However, the drawback is an increased model size due to the presence of multiple “experts,” making the latest MoE language models challenging to execute without high-end GPUs.
To address this challenge, the authors of this paper delve into the problem of running large MoE language models on consumer hardware. They build upon parameter offloading algorithms and introduce a novel strategy that capitalizes on the inherent properties of MoE LLMs.
The paper explores two main avenues for running these models on more affordable hardware setups: compressing model parameters or offloading them to a less expensive storage medium, such as RAM or SSD. It’s important to note that the proposed optimization primarily targets inference rather than training.
Before delving into the specific strategies, let’s grasp the concepts of parameter offloading and the mixture of experts. Parameter offloading involves moving model parameters to a cheaper memory, such as system RAM or SSD, and loading them just in time when needed for computation. This approach is particularly effective for deep learning models that follow a fixed layer order, enabling pre-dispatch of the next layer’s parameters in the background.
The MoE model builds on an older concept of training ensembles of specialized models (“experts”) with a gating function to select the appropriate expert for a given task. The study uses popular open-access MoE models, Mixtral-8x7B due to their ability to fit non-experts into a fraction of available GPU memory.
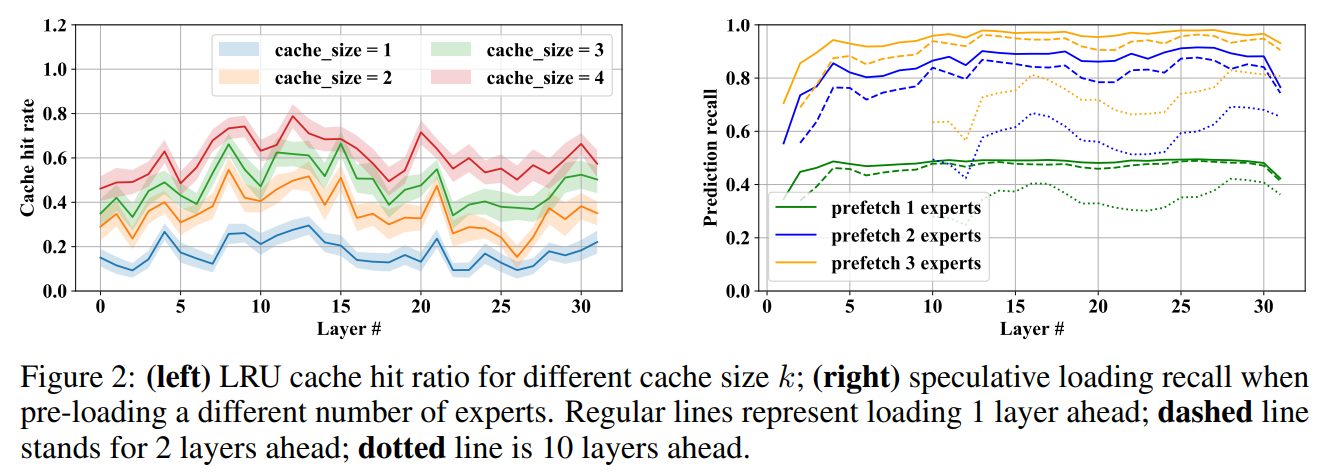
The generative inference workload involves two phases: encoding the input prompt and generating tokens conditioned on that prompt. Notably, MoE models exhibit a pattern (shown in Figure 1) where individual experts are assigned to distinct sub-tasks. To leverage this pattern, the authors introduce the concept of Expert Locality and LRU Caching. By keeping active experts in GPU memory as a “cache” for future tokens, they observe a significant speedup in inference for modern MoE models.
The paper introduces Speculative Expert Loading to address the challenge of expert loading time. Unlike dense models, MoE offloading cannot effectively overlap expert loading with computation. The authors propose guessing the likely next experts based on the gating function of the previous layer’s hidden states to overcome this limitation. This speculative loading approach proves effective in speeding up the next layer’s inference.
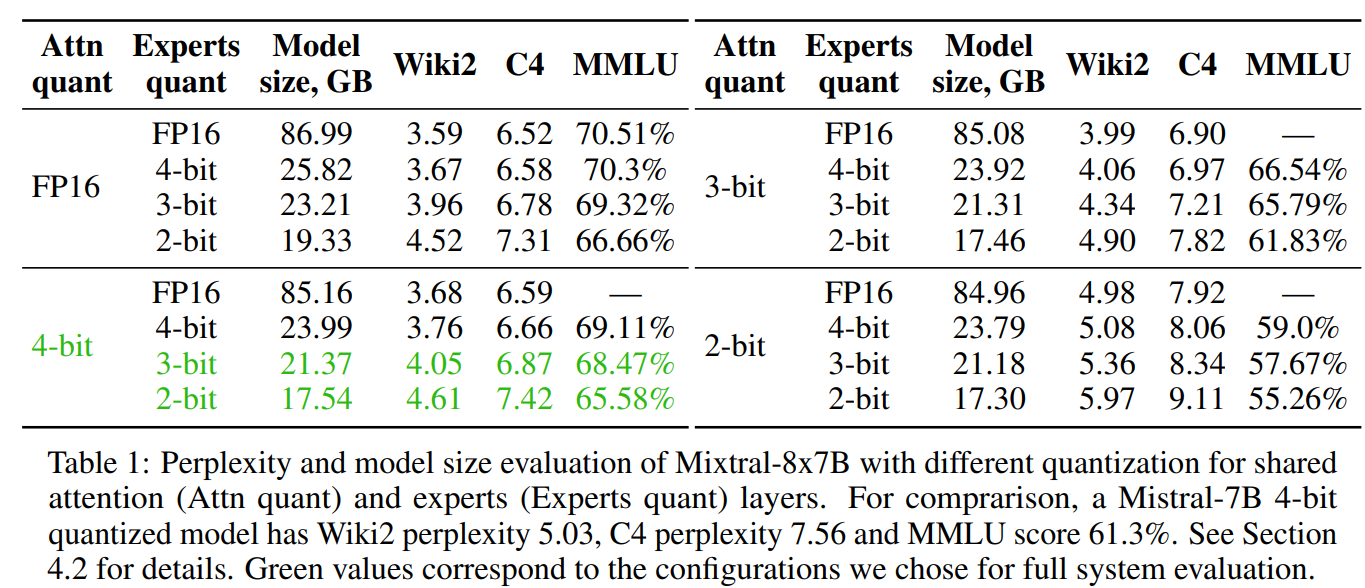
Additionally, the authors explore MoE Quantization, observing that compressed models take less time to load onto the GPU. They use Half Quadratic Quantization (HQQ) for its data-free quantization capabilities, achieving better quality-size trade-offs when quantizing experts to a lower bitwidth.
The paper concludes with an evaluation of the proposed strategies using Mixtral-8x7B and Mixtral-8x7B-Instruct models. Results are provided for expert recall (shown in Figure 2), model compression algorithms (shown in Table 1), and inference latency in various hardware setups (shown in Table 2). The findings indicate a significant increase in generation speed on consumer-grade hardware, making large MoE models more accessible for research and development.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.