JPMorgan AI Research Introduces DocLLM: A Lightweight Extension to Traditional Large Language Models Tailored for Generative Reasoning Over Documents with Rich Layouts
Enterprise documents like contracts, reports, invoices, and receipts come with intricate layouts. These documents may be automatically interpreted and analyzed, which is useful and can result in the creation of AI-driven solutions. However, there are a number of challenges, as these documents can have rich semantics that lie at the intersection of textual and spatial modalities. The complex layouts of the documents provide crucial visual clues that are necessary for their efficient interpretation.
While Document AI (DocAI) has made significant strides in areas such as question answering, categorization, and extraction, real-world applications continue to face persistent hurdles related to accuracy, reliability, contextual understanding, and generalization to new domains.
To address these issues, a team of researchers from JPMorgan AI Research has introduced DocLLM, a lightweight version of conventional Large Language Models (LLMs) that takes into account both textual semantics and spatial layout and has been specifically created for reasoning over visual documents.
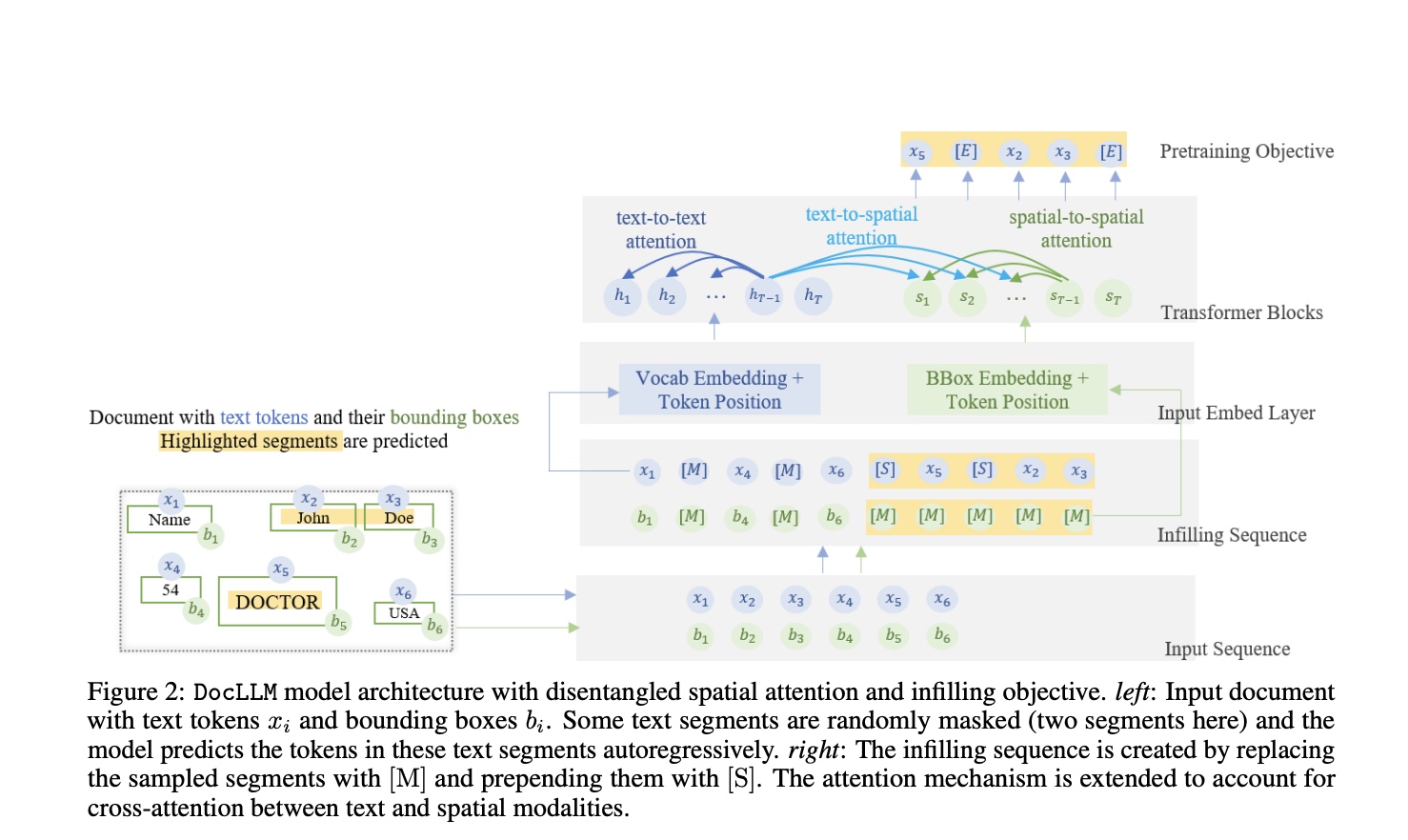
DocLLM is inherently multi-modal since it represents both text semantics and spatial layouts. In contrast to traditional methods, it has been developed in a way that it uses bounding box coordinates acquired using optical character recognition (OCR) to add spatial layout information, hence removing the requirement for a sophisticated visual encoder. This design decision decreases processing times, barely slightly increases model size, and maintains the causal decoder architecture.
The team has shared that for several document intelligence tasks, including form comprehension, table alignment, and visual question responding, just having a spatial layout structure is adequate. By separating spatial information from textual information, the method has extended typical transformers’ self-attention mechanism to capture cross-modal interactions.
Visual documents frequently have fragmented text sections, erratic layouts, and varied information. To address this, the study has suggested changing the pre-training target during the self-supervised pre-training phase. It has recommended infilling to accommodate various text arrangements and cohesive text blocks. With this adjustment, the model can more effectively handle mixed data types, complex layouts, contextual completions, and misaligned text.
DocLLM’s pre-trained knowledge has been fine-tuned on instruction data from many datasets to suit different document intelligence jobs. These tasks include document categorization, visual question answering, natural language inference, and key information extraction.
Both single- and multi-page documents have been covered by the instruction-tuning data, and layout cues like field separators, titles, and captions can be included to make it easier for readers to understand the papers’ logical structure. For the Llama2-7B model, the changes made by DocLLM have yielded notable performance gains, ranging from 15% to 61%, in four of the five previously unpublished datasets.
The team has summarized their primary contributions as follows.
- A typical LLM with a lightweight extension designed especially for visual document interpretation has been introduced,
- The study aims to provide a unique attention mechanism that can distinguish between textual and spatial information, enabling the efficient capture of cross-modal alignment between layout and text.
- A pre-training goal has been outlined to address the difficulties caused by asymmetrical layouts in visual documents.
- A specialized instruction-tuning dataset has been designed for visual document intelligence tasks that should be curated to fine-tune the model effectively.
- In-depth trials have been performed, which yielded important insights into how the suggested model behaves and functions while managing visual documents.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.