Can We Transfer the Capabilities of LLMs like LLaMA from English to Non-English Languages? A Deep Dive into Multilingual Model Proficiency
Significant achievements have been made in LLMs, exemplified by ChatGPT, excelling in complex language processing tasks. But most mainstream LLMs like LLaMA are pre-trained on English-dominant corpus. Another example is LaMDA, proposed by Google, which is pre-trained on text containing over 90% English. This limits the performance of LLMs in other non-English languages, which is a matter of concern for non-English users.
Recent strides in LLMs like ChatGPT, PaLM, and LLaMA showcase advanced reasoning, planning, and experiential learning capabilities. While many LLMs comprehend diverse languages, imbalanced language resources pose challenges. BLOOM’s pretraining on 46 languages lacks diversity, and LLaMA faces difficulties with non-English languages. Investigations into vocabulary extension and transfer processes reveal efficient language transfer at minimal cost.
The researchers at the School of Computer Science, Fudan University, have focused on effectively transferring language generation capabilities and following instructions in non-English. To address this, they have analyzed the impact of key factors such as vocabulary extension, further pretraining, and instruction tuning on transfer. Evaluation involves four standardized benchmarks.
The research explores transferring language generation and instruction-following capabilities to non-English languages using LLaMA. Due to its rich linguistic resources, it employs Chinese as the starting point, extending findings to over ten low-resource languages. Models include LLaMA, LLaMA2, Chinese LLaMA, Chinese LLaMA2, and Open Chinese LLaMA, each with different pretraining scales. Evaluation involves benchmarks like LLM-Eval, C-Eval, MMLU, AGI-Eval, and GAOKAO-Bench. Response quality is assessed based on accuracy, fluency, informativeness, logical coherence, and harmlessness. The study achieves state-of-the-art performance with minimal pretraining data, providing insights for non-English LLM development.
The study investigates language transfer to non-English languages using LLaMA, focusing on vocabulary extension, training scale impact, and multilingual proficiency. Surprisingly, extending the vocabulary diminishes performance in Chinese. While increased pretraining scale initially improves response quality, it plateaus, emphasizing language generation over knowledge acquisition. English proficiency suffers with exclusive Chinese training. Evaluations across 13 low-resource languages show SFT data boost response quality, with Arabic, Indonesian, and Vietnamese excelling. Code-switching samples suggest LLaMA learns cross-lingual semantic alignment during pretraining, enhancing transferability. The study emphasizes nuanced approaches for effective non-English LLM development.
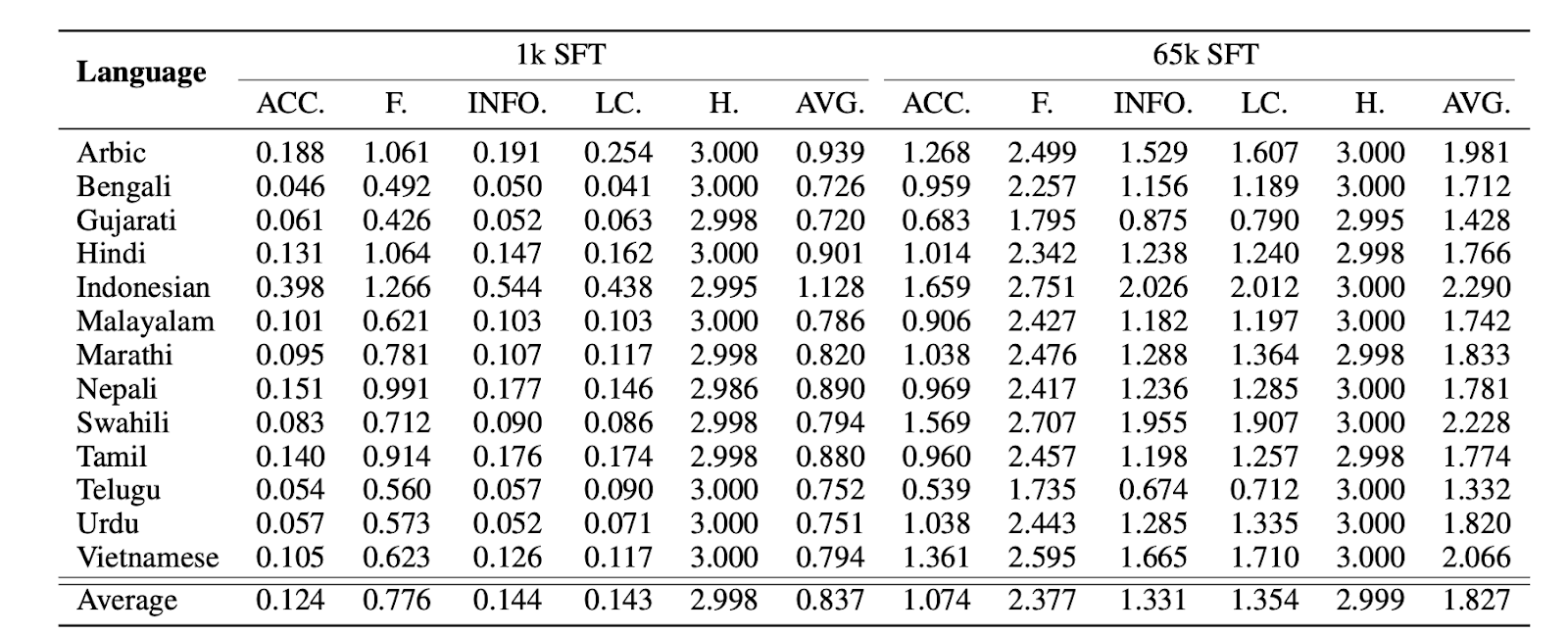
Table 1: Evaluation results of model response quality for 13 low-resource languages on the LLM-Eval. ACC., F., LC., H., INFO., and AVG. Respectively denote accuracy, fluency, logical coherence, harmlessness, informativeness, and average.
Researchers have focused on effectively transferring language generation capabilities and following instructions to a non-English language. Specifically, they have conducted a comprehensive empirical study to analyze the necessity of vocabulary extension and the required training scale for effective transfer. They found that vocabulary extension is unnecessary and that comparable transfer performance to state-of-the-art models can be achieved with less than 1% of the further pretraining data. Similar results are observed from the extension experiments on the 13 low-resource languages.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.