Can a Single Model Revolutionize Music Understanding and Generation? This Paper Introduces the Groundbreaking MU-LLaMA and M2UGen Models
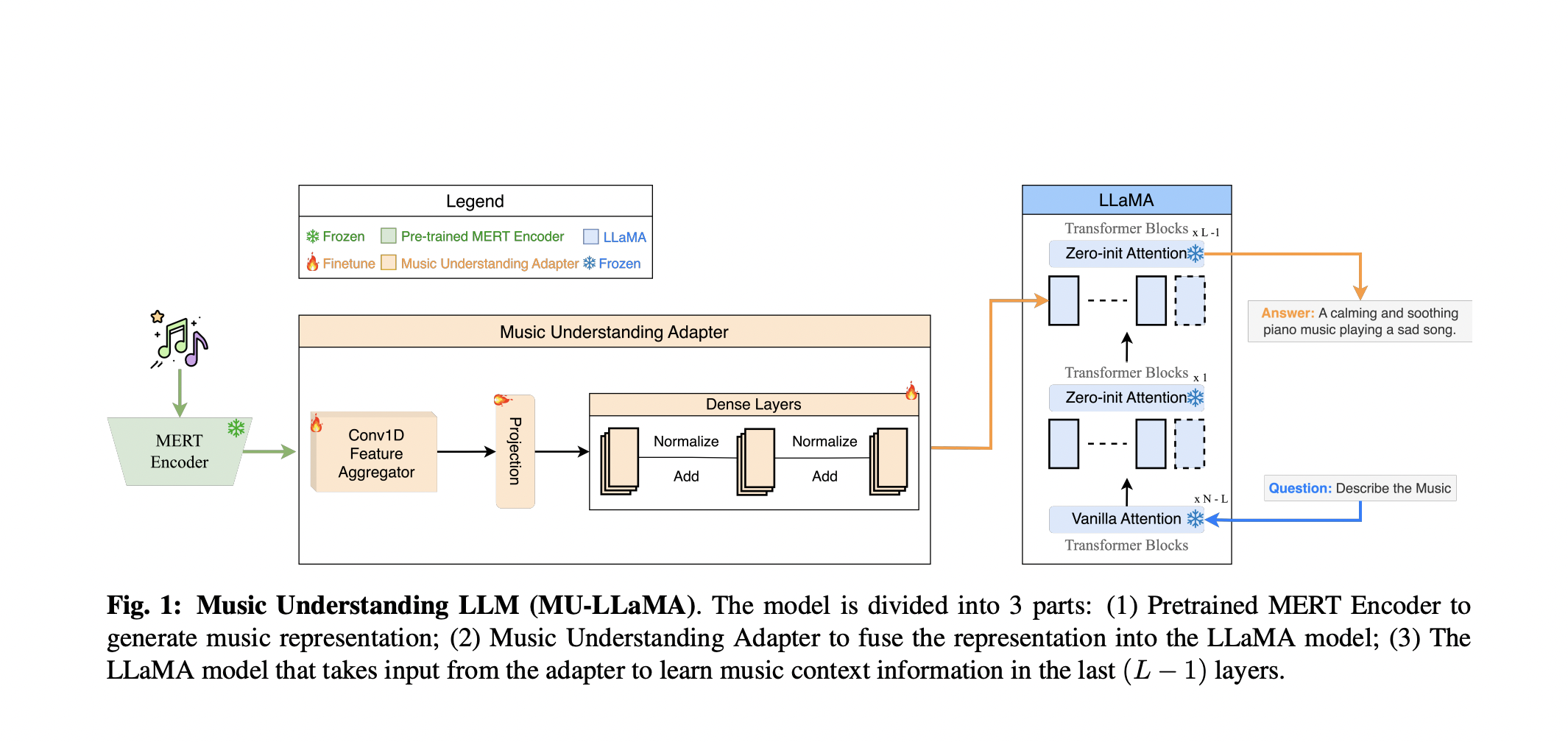
The necessity for large-scale music datasets with natural language captions is a difficulty for text-to-music production, which this research addresses. Although closed-source captioned datasets are available, their scarcity prevents text-to-music creation research from progressing. To tackle this, the researchers suggest the Music Understanding LLaMA (MU-LLaMA) model, intended for captioning and music question answering. It does this by using an approach to create many music question-answer pairings from audio captioning datasets that are already available.
Text-to-music creation techniques now in use have limits, and datasets are frequently closed-source because of license constraints. Building on Meta’s LLaMA model and utilizing the Music Understanding Encoder-Decoder architecture, a research team from ARC Lab, Tencent PCG and National University of Singapore present MU-LLaMA. In particular, the study describes how the MERT model is used as the music encoder, enabling the model to comprehend music and respond to queries. By automatically creating subtitles for a large number of music files from public resources, this novel method seeks to close the gap.
The methodology of MU-LLaMA is based on a well-designed architecture, which begins with a frozen MERT encoder that produces embeddings of musical features. After that, these embeddings are processed by a thick neural network with three sub-blocks and a 1D convolutional layer. The linear layer, SiLU activation function, and normalization components are all included in each sub-block and are connected via skip connections. The last (L-1) layers of the LLaMA model use the resulting embedding, which supplies crucial music context information for the question-answering procedure. The music understanding adapter is tweaked during training, but the MERT encoder and LLaMA’s Transformer layers are frozen. With this method, MU-LLaMA can produce captions and respond to queries based on the context of music.

BLEU, METEOR, ROUGE-L, and BERT-Score are the main text generation measures used to assess MU-LLaMA’s performance. Two primary subtasks are used to test the model: music question answering and music captioning. Comparisons are made with existing large language model (LLM) based models for addressing music questions, specifically the LTU model and the LLaMA Adapter with ImageBind encoder. In every metric, MU-LLaMA performs better than comparable models, demonstrating its ability to respond accurately and contextually to questions about music. MU-LLaMA has competition from Whisper Audio Captioning (WAC), MusCaps, LTU, and LP-MusicCaps in music captioning. The outcomes highlight MU-LLaMA’s capacity to produce high-quality captions for music files by demonstrating its superiority in BLEU, METEOR, and ROUGE-L criteria.
In conclusion, MU-LLaMA shows promise to address text-to-music generating issues while demonstrating improvements in music question responding and captioning. The suggested process for producing numerous music question-answer pairs from existing datasets contributes substantially to the subject. The fact that MU-LLaMA performs better than existing models indicates that it has the potential to change the text-to-music generating environment by providing a reliable and adaptable method.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.