Instacart Introduces Griffin 2.0: It’s Next-Gen Machine Learning Platform with Advanced Features
Instacart has recently introduced Griffin 2.0, a machine learning (ML) platform, to streamline the development and deployment of ML applications. It is an updated form of the first-generation Griffin platform. First-generation Griffin was also very efficient and had tripled the number of ML applications within a year. But it had certain limitations, too. It faced challenges with complex tooling, fragmented user experience, lack of standardization, and scalability issues.
Consequently, Instacart researchers have tried to address these limitations and developed Griffin 2.0 to solve these problems. They have also included certain new features in Griffin 2.0. Also, Griffin’s 2.0 has a service-oriented architecture instead of using Git-based tools and a command-line interface (CLI) like in the first edition. The researchers said that this architecture change and an intuitive web user interface allow Machine learning engineers (MLEs) to have a seamless experience. Integrating the Griffin SDK with additional tools, including BentoLM and Instacart’s cloud-based development environment for machine learning notebooks, is also possible.

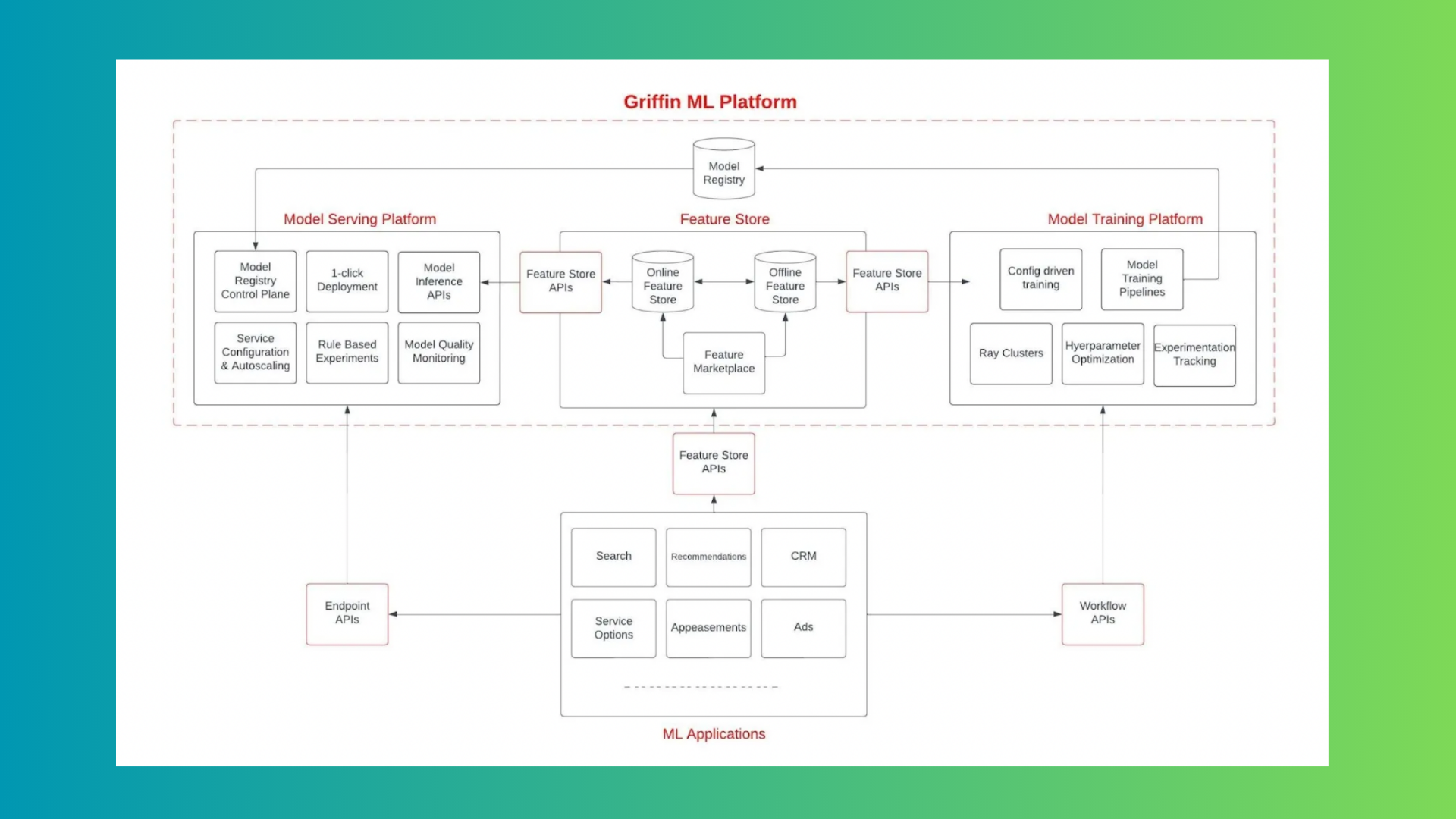
The researchers have used three major subsystems in Griffin 2.0’s backend. These subsystems are the Model Training Platform (MLTP), Model Service Platform (MLSP), and Feature Store. Model Training Platform (MLTP) is used to leverage Ray and provides a horizontally scalable computing environment. It can also unify various training backend platforms on Kubernetes and provides configuration-based runtimes for certain frameworks like Tensorflow and LightGBM. Meanwhile, the Model Service Platform (MLSP) can streamline and automate model artifact storage, deployments, and provisioning of inference services. MLSP also allows fine-tuning service resources and scalability configurations and ensures quick and low-maintenance availability of ML models at scale. Feature Store supports feature computation, ingestion, discoverability, and shareability; the Feature Store introduces a UI-based workflow for configuring new feature sources and fine-tuning feature computation.
Furthermore, Griffin 2.0 uses a centralized feature and metadata management system. It has distributed computation capabilities and standardized serving mechanisms. These features make it ideal for advanced applications like Large Language Model (LLM) training, fine-tuning, and serving in the future. Also, the user-friendly UI-based workflow significantly streamlines the creation of new feature sources and computation. At the same time, data validation enhances the quality of generated features by catching errors early in the process.
The researchers emphasize that while this updated Griffin has made significant progress, they want to improve the working of this platform further. The ongoing efforts to improve Griffin’s workings include gathering feedback, making enhancements, and fostering adoption to realize the vision outlined in this evolution of the Griffin platform.
In conclusion, Griffin 2.0 can significantly progress in Instacart’s ML research as it solves the first version’s problems and has certain new features to help in more tasks. Further, the changes in its UI and a friendlier web interface make it simpler for the users. Also, Instacart’s commitment to a better user experience, scalability, and new capabilities, such as Griffin 2.0, can reshape this domain.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.