Researchers from Microsoft and NU Singapore Introduce Cosmo: A Fully Open-Source Pre-Training AI Framework Meticulously Crafted for Image and Video Processing

Multimodal learning involves creating systems capable of interpreting and processing diverse data inputs like visual and textual information. Integrating different data types in AI presents unique challenges and opens doors to a more nuanced understanding and processing of complex data.
One significant challenge in this field is effectively integrating and correlating different forms of data, such as text and images or videos. The goal is to create sophisticated AI systems to interpret these diverse data types concurrently and draw meaningful insights. This challenge is central to advancing AI’s capability to understand and interact with the world in a more human-like manner.
Recent developments have centered around leveraging LLMs for their proficiency in processing extensive textual inputs. These models are instrumental in handling complex, multimodal data. However, they often face limitations in tasks requiring precise alignment of textual and visual elements. Addressing this gap, researchers from the National University of Singapore and Microsoft Azure AI have introduced the COSMO framework (COntrastive Streamlined MultimOdal Model), representing a significant leap in multimodal data processing.
The COSMO framework is innovative in its approach to handling multimodal data. It strategically divides a language model into specialized segments dedicated to processing unimodal text and adept multimodal data. This partitioning is crucial in enhancing the model’s efficiency and effectiveness in dealing with diverse data types. COSMO also introduces a contrastive loss to the language model loss in existing models. This integration is key to refining the model’s ability to align different forms of data, especially in tasks involving textual and visual data.
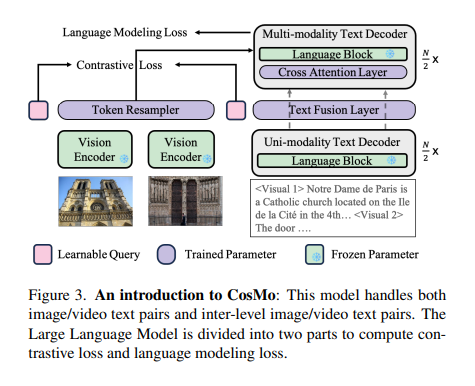
An integral part of COSMO’s methodology is its use of the Howto-Interlink7M dataset. This dataset is a pioneering resource in the field, offering detailed annotations of video-text data. It addresses a critical gap in the availability of high-quality, long-text video datasets. This dataset’s rich and comprehensive nature is vital in enhancing the model’s performance in image-text tasks.
COSMO’s performance is a testament to its innovative design and methodology. It showcases significant improvements over existing models, particularly in tasks that necessitate textual and visual data alignment. In a specific 4-shot Flickr captioning task, COSMO’s performance substantially improved, jumping from 57.2% to 65.1%. This improvement underscores the model’s enhanced capability in understanding and processing multimodal data.
To summarize, the key highlights of this research include:
- The introduction of COSMO, a framework for streamlined multimodal data processing.
- Strategic partitioning of a language model into segments for unimodal text and multimodal data processing.
- Integration of contrastive loss with language model loss, enhancing data alignment capabilities.
- The development and utilization of the Howto-Interlink7M dataset is a significant addition to long-text, multimodal datasets.
- Notable performance improvements in aligning textual and visual data demonstrate COSMO’s advanced multimodal learning capabilities.
Check out the Paper, Github and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.