Meet MosaicBERT: A BERT-Style Encoder Architecture and Training Recipe that is Empirically Optimized for Fast Pretraining
BERT is a language model which was released by Google in 2018. It is based on the transformer architecture and is known for its significant improvement over previous state-of-the-art models. As such, it has been the powerhouse of numerous natural language processing (NLP) applications since its inception, and even in the age of large language models (LLMs), BERT-style encoder models are used in tasks like vector embeddings and retrieval augmented generation (RAG). However, in the past half a decade, many significant advancements have been made with other types of architectures and training configurations that have yet to be incorporated into BERT.
In this research paper, the authors have shown that speed optimizations can be incorporated into the BERT architecture and training recipe. For this, they have introduced an optimized framework called MosaicBERT that improves the pretraining speed and accuracy of the classic BERT architecture, which has historically been computationally expensive to train.
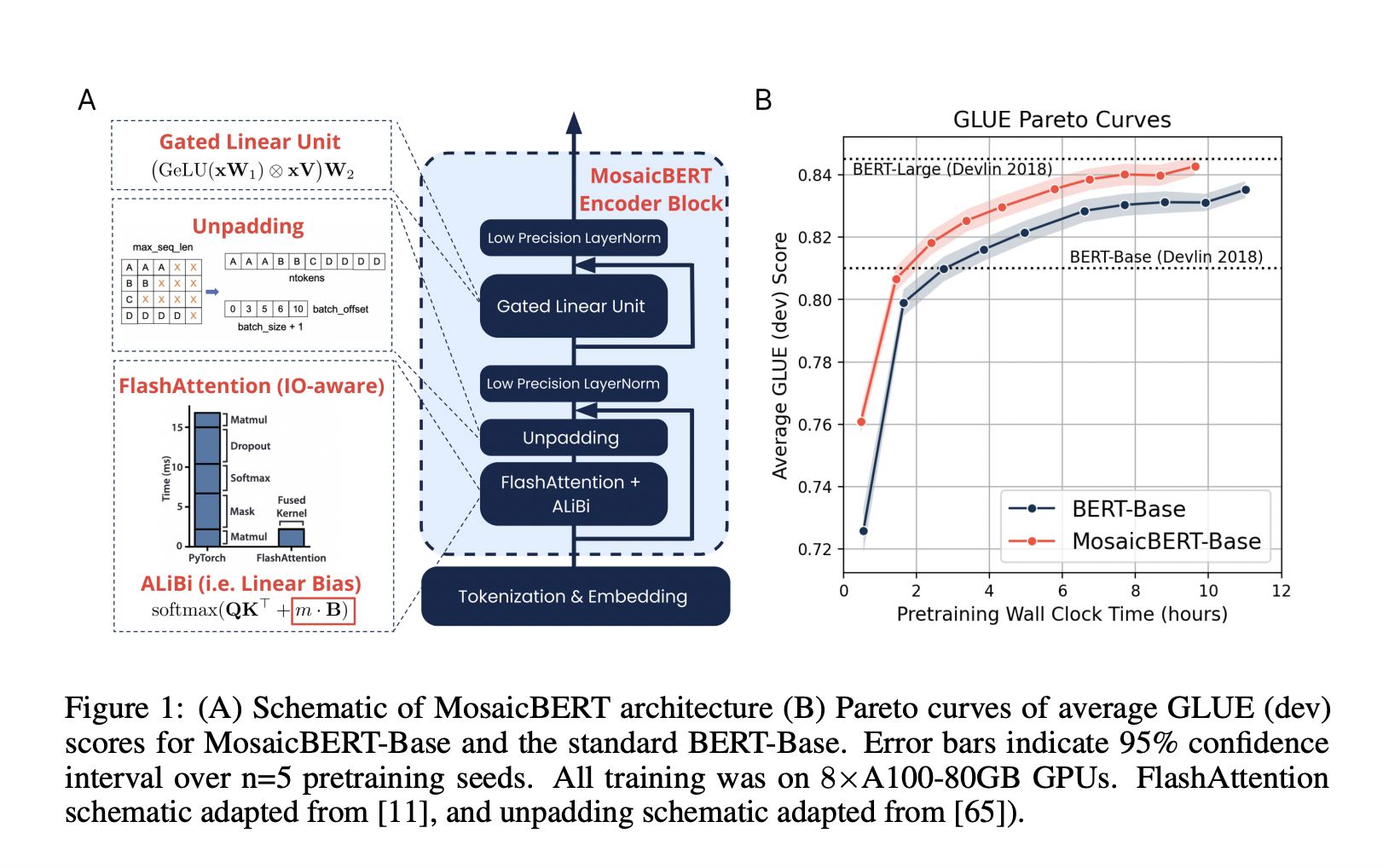
To build MosaicBERT, the researchers used different architectural choices such as FlashAttention, ALiBi, training with dynamic unpadding, low-precision LayerNorm, and Gated Linear Units.
- The flashAttention layer reduces the number of read/write operations between the GPU’s long-term and short-term memory.
- ALiBi encodes position information through the attention operation, eliminating the position embeddings and acting as an indirect speedup method.
- The researchers modified the LayerNorm modules to run in bfloat16 precision instead of float32, which reduces the amount of data that needs to be loaded from memory from 4 bytes per element to 2 bytes.
- Lastly, the Gated Linear Units improves the Pareto performance across all timescales.
The researchers pretrained BERT-Base and MosaicBERT-Base for 70,000 steps of batch size 4096 and then finetuned them on the GLUE benchmark suite. BERT-Base reached an average GLUE score of 83.2% in 11.5 hours, whereas MosaicBERT achieved the same accuracy in around 4.6 hours on the same hardware, highlighting the significant speedup. MosaicBERT also outperforms the BERT model in four out of eight GLUE tasks across the training duration.
The large variant of MosaicBERT also had a significant speedup over the BERT variant, achieving an average GLUE score of 83.2 in 15.85 hours compared to 23.35 hours taken by BERT-Large. Both the variants of MosaicBERT are Pareto Optimal relative to the corresponding BERT models. The results also show that the performance of BERT-Large surpasses the base model only after extensive training.
In conclusion, the authors of this research paper have improved the pretraining speed and accuracy of the BERT model using a combination of architectural choices such as FlashAttention, ALiBi, low-precision LayerNorm, and Gated Linear Units. Both the model variants had a significant speedup compared to their BERT counterparts by achieving the same GLUE score in less time on the same hardware. The authors hope their work will help researchers pre-train BERT models faster and cheaper, ultimately enabling them to build better models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.