Meet DeepSeek LLMs: A Series of Open-Source AI Models Trained from Scratch on a Vast Dataset of 2 Trillion Tokens in both English and Chinese
With the quick advancements in Artificial Intelligence, Large Language Models (LLMs) are improving daily with every new research. These models perform self-supervised pre-training on large datasets, making them capable of performing exceptionally well in various tasks, including question answering, content generation, text summarization, code completion, etc.
The development of open-source Large Language Models is taking place at a fast pace. However, the currently existing studies on scaling laws have generated inconclusive findings, creating uncertainty around the efficient scaling of LLMs. To address this challenge, a team of researchers from DeepSeek AI has released a study about scaling laws in detail and providing information about the scaling dynamics of large-scale models, especially in the popular open-source 7B and 67B configurations.
The team has introduced the DeepSeek LLM project, which is a long-term focused initiative to advance open-source language models guided by the established scaling rules. To support the pre-training stage, the team has assembled a large dataset of 2 trillion tokens, which is being constantly added to meet changing needs. Direct Preference Optimization (DPO) and Supervised Fine-Tuning (SFT) have been used for DeepSeek LLM Base models, which has led to the creation of sophisticated DeepSeek Chat models.
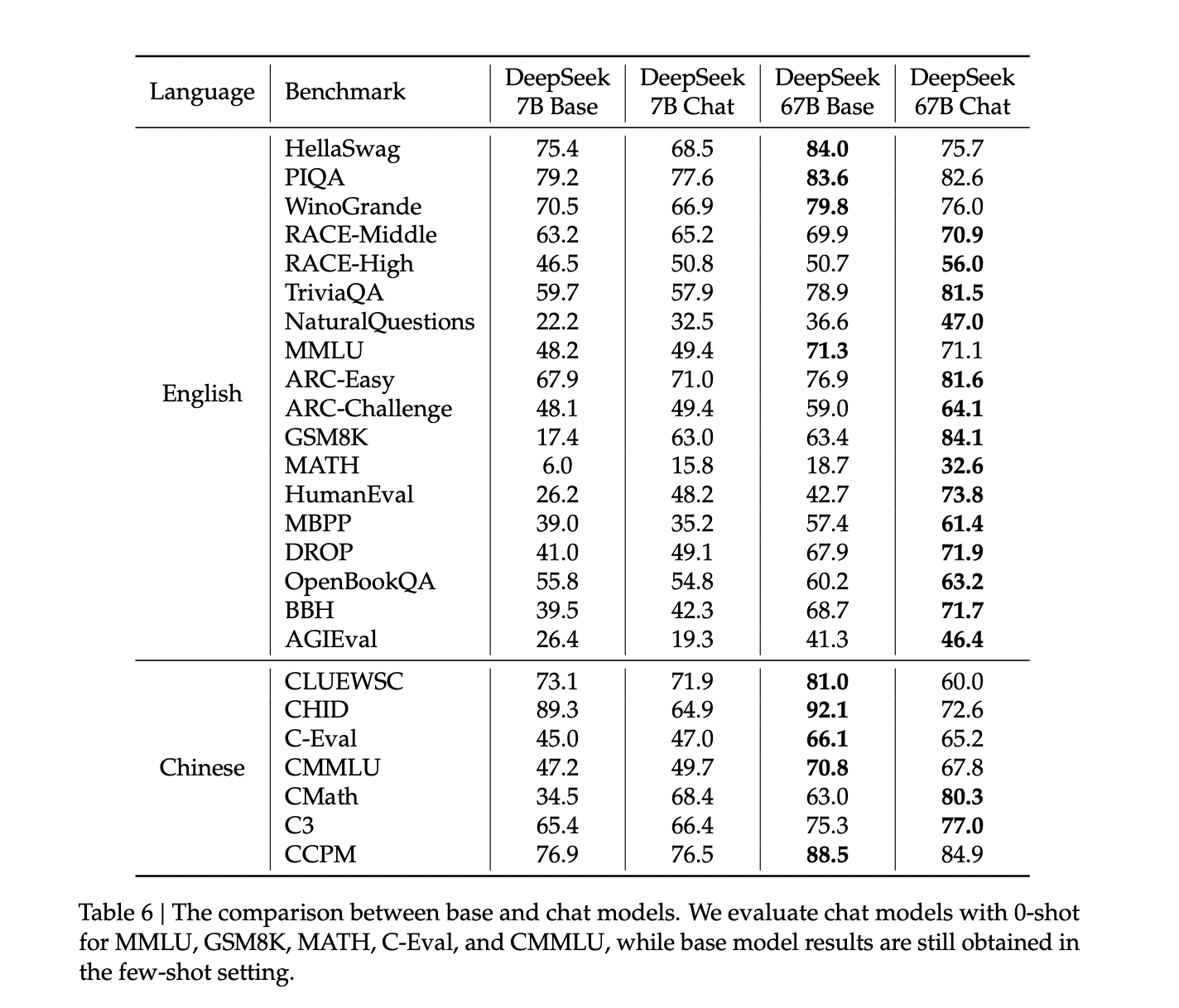
DeepSeek LLM is basically a sophisticated language model with 67 billion parameters, which has been trained from the beginning using a sizable dataset of two trillion tokens in both Chinese and English. Upon evaluation, the team has shared that DeepSeek LLM 67B is a lot effective. DeepSeek LLM 67B Base has scored better than Llama2 70B Base in tasks like math, reasoning, coding, and Chinese understanding.
DeepSeek LLM 67B Chat has performed exceptionally well in math (GSM8K 0-shot: 84.1, Math 0-shot: 32.6) and coding (HumanEval Pass@1: 73.78). Its remarkable score of 65 on the Hungarian National High School Exam has demonstrated the model’s great generalization abilities and its capacity to extend its performance across many tasks and contexts. Compared to GPT-3.5, DeepSeek LLM 67B Chat has performed better in open-ended assessments.
The team has summarized their primary contributions as follows.
- Scaling Hyperparameters – Empirical scaling rules that provide a methodical way to find the ideal values for hyperparameters during training have been developed.
- Model Scale Representation – For a more accurate representation of the model scale, non-embedding FLOPs or tokens have been introduced in place of model parameters. This increases the generalization loss forecasts for large-scale models and improves the accuracy of the ideal model or data scaling-up allocation approach.
- Impact of Data Quality – The best model or data scaling-up allocation approach has been heavily influenced by the caliber of the pre-training data. Improved data quality makes it necessary to devote a larger computing budget to model scaling, underscoring the significance of data quality in model building.
In conclusion, this study provides insight into the complexities of scaling laws in the context of Large Language Models. This effort thus pushes forward the development of open-source language models by resolving challenges raised by the findings in earlier research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.