Can Your Chatbot Become Sherlock Holmes? This Paper Explores the Detective Skills of Large Language Models in Information Extraction
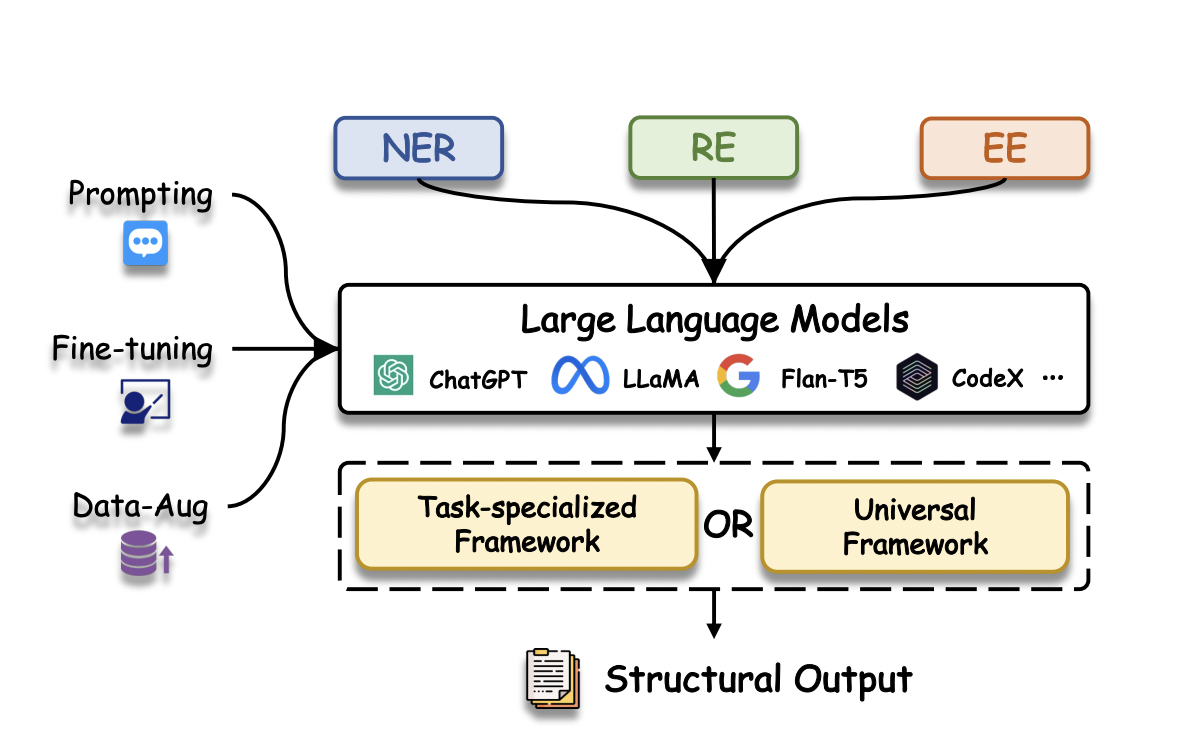
One of the most important areas of NLP is information extraction (IE), which takes unstructured text and turns it into structured knowledge. Many subsequent activities rely on IE as a prerequisite, including building knowledge graphs, knowledge reasoning, and answering questions. Named Entity Recognition, Relation Extraction, and Event Extraction are the three main components of an IE job. At the same time, Llama and other large language models have emerged and are revolutionizing NLP with their exceptional text understanding, generation, and generalization capabilities.
So, instead of extracting structural information from plain text, generative IE approaches that use LLMs to create structural information has recently become very popular. With their ability to handle schemas with millions of entities efficiently and without any performance loss, these methods outperform discriminating methods in real-world applications.
A new study by the University of Science and Technology of China & State Key Laboratory of Cognitive Intelligence, City University of Hong Kong, and Jarvis Research Center explores LLMs for generative IE. To accomplish this, they classify current representative methods primarily using two taxonomies:
- Taxonomy of learning paradigms, which classifies different novel approaches that use LLMs for generative IE
- Taxonomy of numerous IE subtasks, which tries to classify the different types of information that can be extracted individually or uniformly using LLMs.
In addition, they present research that ranks LLMs for IE based on how well they perform in particular areas. In addition, they offer an incisive analysis of the constraints and future possibilities of applying LLMs for generative IE and evaluate the performance of numerous representative approaches across different scenarios to better understand their potential and limitations. As mentioned by researchers, this survey on generative IE with LLMs is the first of its kind.
The paper suggests four NER reasoning strategies that mimic ChatGPT’s capabilities on zero-shot NER and considers the superior reasoning capabilities of LLMs. Some research on LLMs for RE has shown that few-shot prompting with GPT-3 gets performance close to SOTA and that GPT-3-generated chain-of-thought explanations can improve Flan-T5. Unfortunately, ChatGPT is still not very good at EE tasks because they require complicated instructions and are not resilient. Similarly, other researchers assess various IE subtasks concurrently to conduct a more thorough evaluation of LLMs. While ChatGPT does quite well in the OpenIE environment, it typically underperforms BERT-based models in the normal IE environment, according to the researchers. In addition, a soft-matching approach reveals that “unannotated spans” are the most common kind of error, drawing attention to any problems with the quality of the data annotation and allowing for a more accurate assessment.
Generative IE approaches and benchmarks from the past tend to be domain or task-specialized, which makes them less applicable in real-world scenarios. There have been several new proposals for unified techniques that use LLMs. However, these methods still have significant constraints, such as extended context input and structured output that aren’t aligned. Hence, the researchers suggest that it is necessary to delve further into the in-context learning of LLMs, especially about enhancing the example selection process and creating universal IE frameworks that can adapt flexibly to various domains and activities. They believe that future studies should focus on creating strong cross-domain learning methods, such as domain adaptation and multi-task learning, to make the most of domains that are rich in resources. It is also important to investigate effective data annotation systems that use LLMs.
Improving the prompt to help the model understand and reason better (e.g., Chain-of-Thought) is another consideration; this can be achieved by pushing LLMs to draw logical conclusions or generate explainable output. Interactive prompt design (like multi-turn QA) is another avenue that academics might investigate; in this setup, LLMs automatically refine or offer feedback on the extracted data in an iterative fashion.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.