Meta AI Introduces CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
There has been a significant surge in the integration of language models (LMs) into mainstream applications within the fields of software engineering and programming. Large Language Models LLMs, including recent models such as Code Llama, GPT-3.5, and GPT-4 (OpenAI, 2023), have demonstrated notable effectiveness in various code-related tasks.
These tasks span code completion, program repair, debugging, test case generation, and code optimization. Code language models are commonly evaluated using benchmarks like HumanEval and MBPP, testing their ability to generate code snippets from natural language. While these benchmarks cover basic code generation tasks, there is a lack of benchmarks assessing other crucial dimensions, such as code understanding and execution.
Motivated by this objective, this paper by Meta AI introduces a novel benchmark named CRUXEval (Code Reasoning, Understanding, and eXecution Evaluation), featuring two tasks: – (1) CRUXEval-O for gauging code execution outcomes and (2) CRUXEval-I for evaluating code reasoning and understanding.

As shown above, CRUXEval focuses on assessing code language models’ competence in understanding the execution behavior of simple Python programs. While these models are not intended to replace interpreters for complex problems, CRUXEval ensures simplicity (maximum 13 lines, no complex arithmetic), making them solvable by a university-level CS graduate without excessive memory requirements.
At a broad level, the construction of their benchmark involves several key steps.
- Initially, they employ Code Llama 34B to generate an extensive set of functions and corresponding inputs. The resulting outputs are derived by executing these functions on the provided inputs.
- They filter the set, focusing on short problems with minimal computation and memory requirements—issues that proficient human programmers should be capable of solving within a minute without additional memory.
- Finally, they randomly select 800 samples that pass the filtering criteria, ensuring the benchmark is sufficiently compact for easy execution while being large enough to detect performance variations across various models. This methodology is chosen because, although creating examples where robust models like GPT-4 completely fail is challenging manually, there is observed frequent failure on random yet reasonable programs by these powerful models.
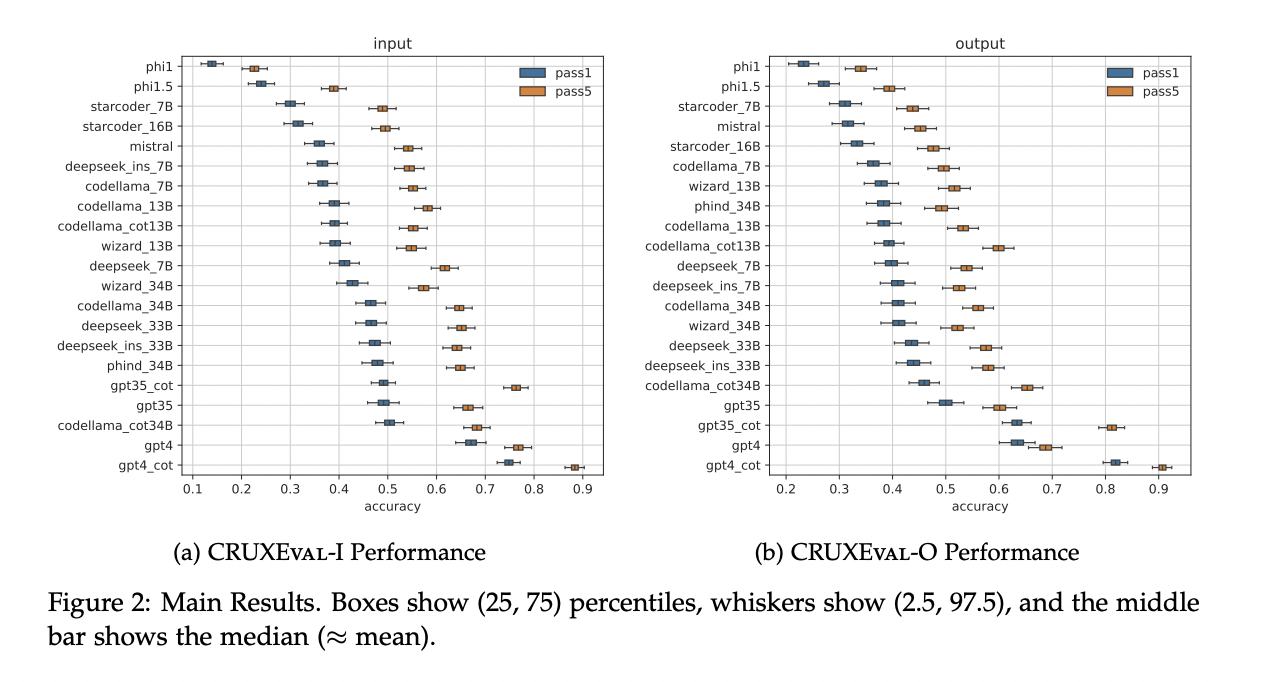
Researchers observed a selection of models on CRUXEval like StarCoder, WizardCoder, Code Llama, etc. The findings observed that the best setup, GPT-4 with chain of thought (CoT), achieves a pass@1 of 75% and 81% on input and output prediction, respectively. In contrast, Code Llama 34B achieves a pass@1 of 50% and 46% on input and output prediction, highlighting the gap between open and closed source models. After fine-tuning on samples very similar to those in our benchmark, Code Llama 34B could match the performance of GPT-4 on both input and output prediction.
The fact that models like Phi, WizardCoder, and Phind outperformed Code Llama in HumanEval but not in CRUXEval underscores the need for a deeper investigation into the effectiveness of fine-tuning with data from more powerful models. Furthermore, the question of whether fine-tuning on execution information can enhance code generation abilities remains an intriguing aspect. As a prospect for future research, this benchmark provides a solid starting point for exploring the code reasoning capabilities of language models!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.