How to Choose the Right Vision Model for Your Specific Needs: Beyond ImageNet Accuracy – A Comparative Analysis of Convolutional Neural Networks and Vision Transformer Architectures
There has been a dramatic increase in the complexity of the computer vision model landscape. Many models are now at your fingertips, from the first ConvNets to the latest Vision Transformers. Just as supervised learning on ImageNet gave way to self-supervised learning and image-text pair training, such as CLIP, so did training paradigms.
Compared to ResNets, CLIP’s visual encoder is far more resilient and transferable, even though it has comparable ImageNet accuracy. Because of this, studies have begun to investigate and expand upon CLIP’s distinct advantages, which were not apparent when using the ImageNet metric alone. This proves that looking at several attributes could lead to discovering practical models.
In addition to basic research, an in-depth knowledge of the behaviors of vision models is required due to their increasing incorporation into production systems. Traditional metrics fall short when it comes to real-world vision problems, such as different camera postures, lighting conditions, or occlusions.
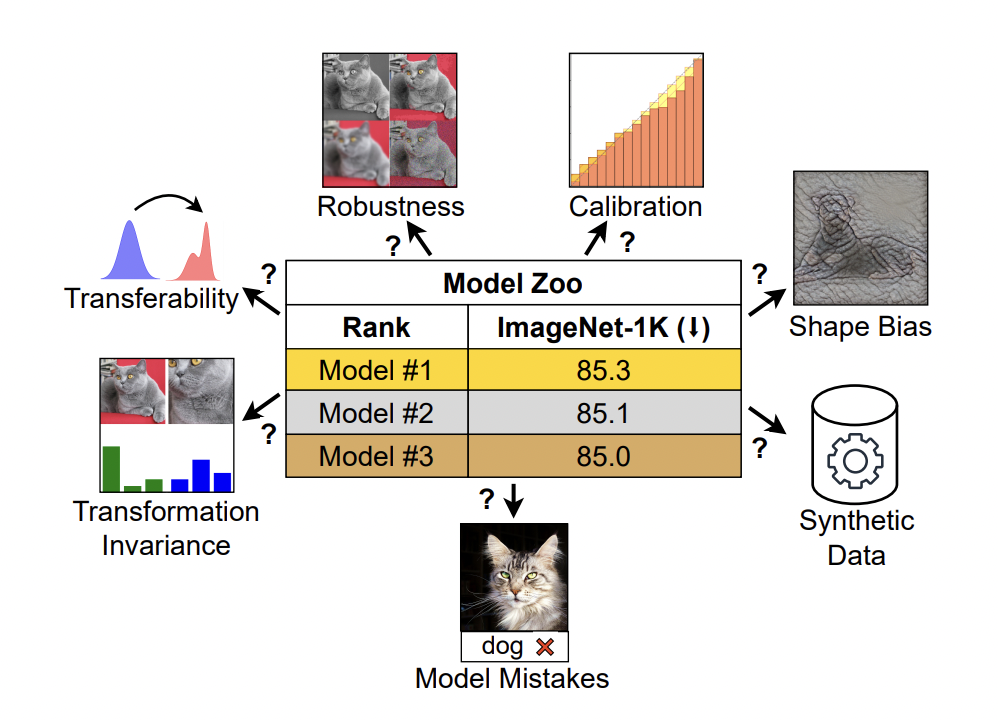
To fill this gap, a new study by MBZUAI and Meta AI Research investigates model characteristics beyond ImageNet correctness. The researchers examine four top models in computer vision: ConvNeXt, which stands for ConvNet, and Vision Transformer (ViT), all trained using supervised and CLIP methods. All of the chosen models are comparable in parameter counts and ImageNet-1K accuracy across all training paradigms, guaranteeing an objective comparison. Types of prediction errors, generalizability, calibration, invariances of the learned representations, and many more model properties are explored in this work.
The team’s primary goal was to shed light on the model’s intrinsic qualities that do not require further training or fine-tuning so that practitioners can make informed decisions when working with pre-trained models. They find that various topologies and training paradigms exhibit significantly varied model behaviors. When compared to their ImageNet performance, CLIP models, for instance, produce fewer classification errors. On the other hand, when it comes to ImageNet robustness benchmarks, supervised models tend to perform better and have better calibration. Compared to ViT, ConvNeXt is more texture-biased, although it excels on synthetic data.
Additionally, the researchers discovered that supervised ConvNeXt outperforms CLIP models regarding transferability and performs quite well on numerous benchmarks. These results show that different models show their strengths differently and that a single statistic cannot adequately measure these differences. The findings highlight the importance of developing new, independent benchmarks and more comprehensive evaluation metrics for precise, context-specific model selection.
When the desired task distribution is similar to ImageNet, the team chooses supervised ConvNeXt because it outperforms numerous benchmarks. They recommend the use of CLIP models in the event of a significant domain transition.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.