MAGNeT: A Masked Generative Sequence AI Modeling Method that Operates Directly Over Several Streams of Audio Tokens and 7x Faster than the Autoregressive Baseline
In audio technology, researchers have made significant strides in developing models for audio generation. However, the challenge lies in creating models that can efficiently and accurately generate audio from various inputs, including textual descriptions. Earlier approaches have focused on autoregressive and diffusion-based models. While these approaches yield impressive results, they have drawbacks, such as high inference times and struggles with generating long-form sequences.
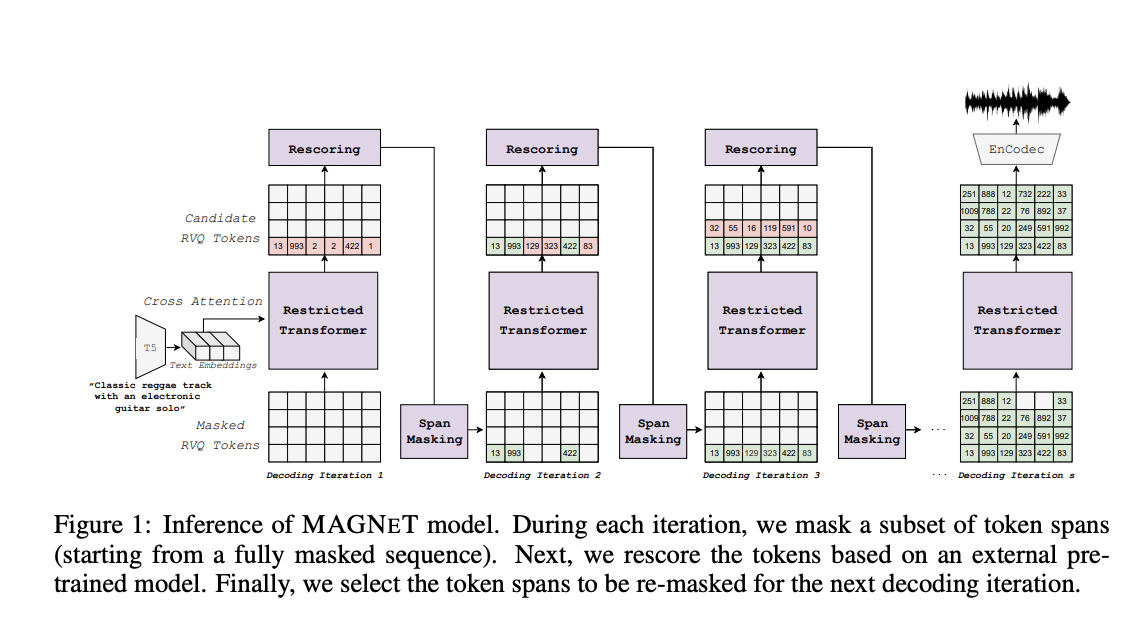
Researchers from FAIR Team Meta, Kyutai, and The Hebrew University of Jerusalem have developed MAGNET (Masked Audio Generation using Non-autoregressive Transformers) in response to these challenges. This novel approach operates on multiple streams of audio tokens using a single transformer model. Unlike previous methods, MAGNET is non-autoregressive, predicting spans of masked tokens obtained from a masking scheduler during training. It gradually constructs the output audio sequence during inference through several decoding steps. This approach significantly speeds up the generation process, making it more suitable for interactive applications such as music generation and editing.

MAGNET also introduces a unique rescoring method to enhance audio quality. This method leverages an external pre-trained model to rescore and rank predictions from MAGNET, which are then used in later decoding steps. A hybrid version of MAGNET, which combines autoregressive and non-autoregressive models to generate the first few seconds of audio in an autoregressive manner, has been explored. At the same time, the rest of the sequence is decoded in parallel.
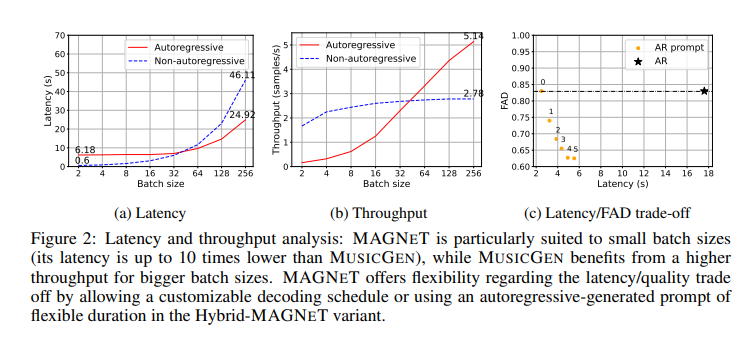
The efficiency of MAGNET has been demonstrated in the context of text-to-music and text-to-audio generation. Through extensive empirical evaluation, including both objective metrics and human studies, MAGNET has shown comparable performance to existing baselines while being significantly faster. This speed is particularly notable compared to autoregressive models, with MAGNET being seven times faster.
The research delves into the importance of each component of MAGNET, highlighting the trade-offs between autoregressive and non-autoregressive modeling in terms of latency, throughput, and generation quality. By conducting ablation studies and analysis, the research team has illuminated the significance of various aspects of MAGNET, contributing to a more profound understanding of audio generation technologies.
In conclusion, the development of MAGNET marks a substantial advancement in the realm of audio technology:
- Introduces a novel, efficient approach for audio generation, significantly reducing latency compared to traditional methods.
- Combines autoregressive and non-autoregressive elements to optimize generation quality and speed.
- Demonstrates the potential for real-time, high-quality audio generation from textual explanations, opening up new possibilities in interactive audio applications.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.