Google AI Introduces GRANOLA QA: Revolutionizing Question Answering with Multi-Granularity Evaluation
Large Language Models (LLMs) have demonstrated exceptional capabilities in natural language processing and find their application in almost every field, with factual question-answering being one of the most common use cases. Unlike others, factual answers could be answered correctly at different levels of granularity. For example, “1961” and “August 4, 1961” are both correct responses to the question “When was Barack Obama born?”. Such versatility in providing answers poses challenges to accurately evaluating such answers and leads to disagreement between lexical matching and human assessment.
The standard question-answering (QA) evaluation settings do not consider this nature of factual answers and typically assess the predicted answer against a set of reference answers of the same granularity. Even in the case of different levels of granularity, there is no notion of which matching is better. This generally leads to an underestimation of the knowledge of LLMs, which is referred to as a knowledge evaluation gap. To address this issue, the authors of this research paper from Google have introduced GRANOLA QA, a multi-granularity QA evaluation setting that evaluates the answers not just on accuracy but also on informativeness.
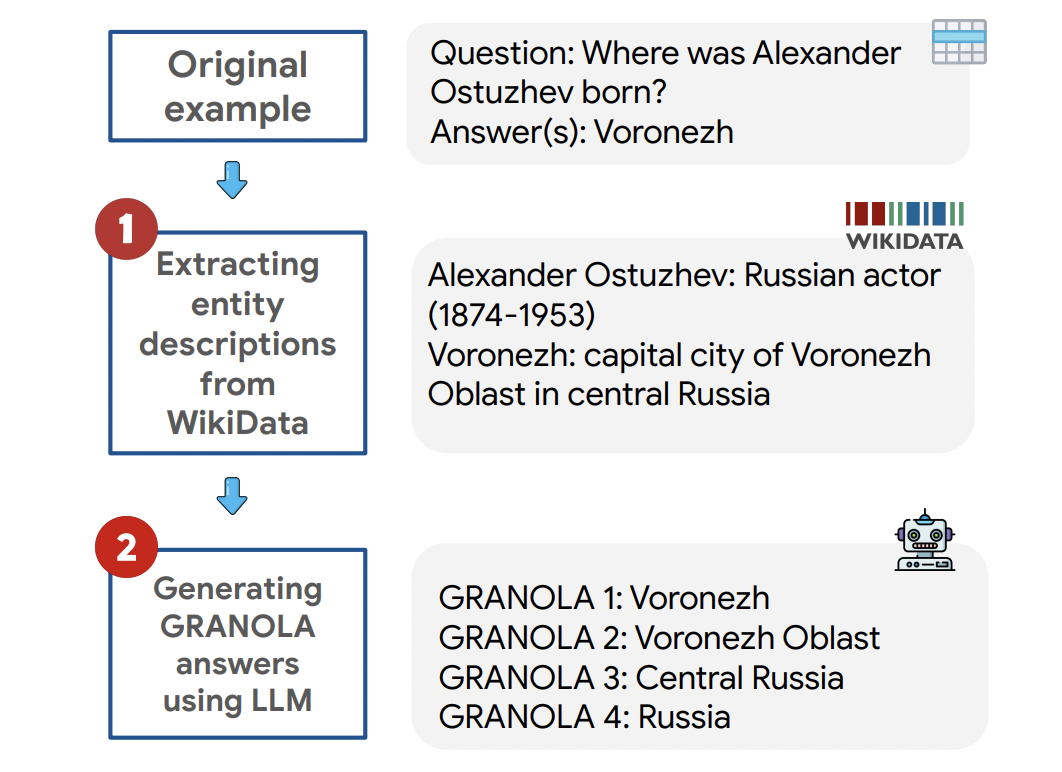
The accuracy is measured based on matching the answer with any of the GRANOLA answers and the informativeness by matching against fine-grained answers using an appropriate weighting scheme. The answer generation process of GRANOLA has two steps – first, a description of the answer entity along with any entity appearing in the question is obtained using an external knowledge graph (KG), and second, an LLM is zero-shot prompted to create an ordered list of answers of varying levels of granularity.
The researchers used the WikiData to verify the correctness of an answer. For informativeness, it is checked whether the response is a trivial answer to the question, i.e., it could be generated solely on the basis of the question template. Lastly, for granularity, the researchers assess whether the response is coarser than its preceding answers.
The researchers have also developed GRANOLA-EQ, which is a multi-granularity version of the ENTITYQUESTIONS dataset, and evaluated models using different decoding methods, including a proposed novel decoding strategy called DRAG that encourages LLMs to tailor the granularity level of their responses based on their uncertainty levels. The results show that LLMs tend to generate specific answers that are often incorrect. On the contrary, when DRAG was evaluated on multi-granularity answers, it demonstrated an increase in the average accuracy by 20 points, which further increased for rare entities.
The authors also highlighted some of the limitations of their work. Their approach for enhancing the QA benchmark with multi-granularity answers depends on extracting entities from the original QA pair and matching them to their knowledge graph entry. This process may be more involved in cases of less-structured datasets. Additionally, for an even better assessment, it is essential to distinguish between the correct answers based on true knowledge instead of mere educated guesses.
In conclusion, the authors of this paper highlighted that generating more detailed responses than what their knowledge supports is a major source of factual errors in LLMs. They have introduced GRANOLA QA, GRANOLA EQ, and DRAG, all geared towards aligning the granularity of the response of these models with its uncertainty level. The experiments showed that considering the granularity level during evaluation and during decoding leads to a significant increase in the model’s accuracy. Although there are a few limitations, their work serves as a good starting point for expanding future research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.