Meet Lightning Attention-2: The Groundbreaking Linear Attention Mechanism for Constant Speed and Fixed Memory Use
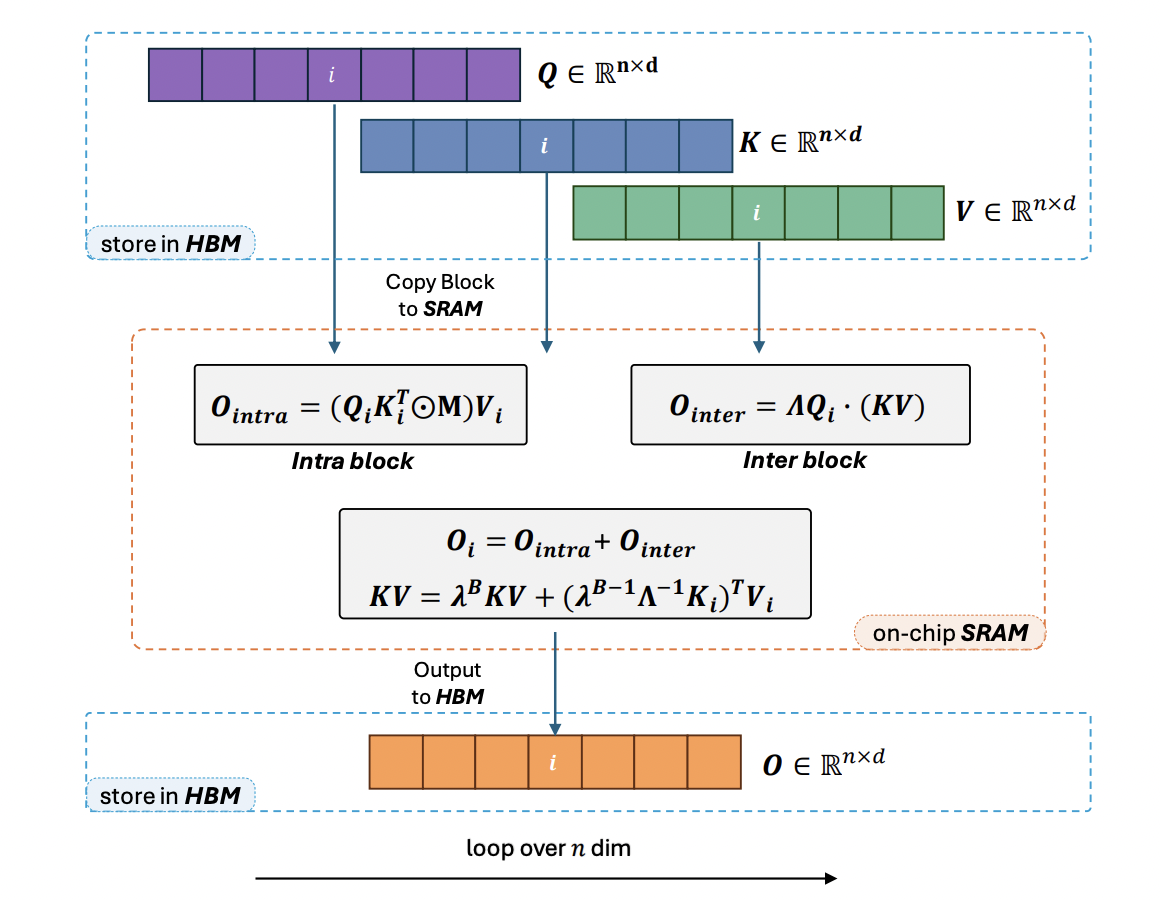
In sequence processing, one of the biggest challenges lies in optimizing attention mechanisms for computational efficiency. Linear attention has proven to be an efficient attention mechanism with its ability to process tokens in linear computational complexities. It has recently emerged as a promising alternative to conventional softmax attention. This theoretical advantage allows it to handle sequences of unlimited length while maintaining a constant training speed and fixed memory consumption. A crucial roadblock arises due to cumulative summation (cumsum), hindering current Linear Attention algorithms from demonstrating their promised efficiency in a casual setting.
The existing research involves leveraging the “kernel trick” to speed up attention matrix computation, emphasizing the product of keys and values before the n×n matrix multiplication. Lightning Attention-1 employs the FlashAttention-1/2 approach to address slow computation in Linear Attention by segmenting inputs and computing attention output concerning blocks. Significant approaches include 1 + elu activation, cosine function approximation, and sampling strategies to emulate softmax operation. IO-aware Attention focuses on system-level optimizations to efficiently implement the standard attention operator on GPU platforms. Some works attempt to directly increase context window sizes, such as Position Interpolation (PI) and StreamingLLM, to extend sequence length in LLMs.
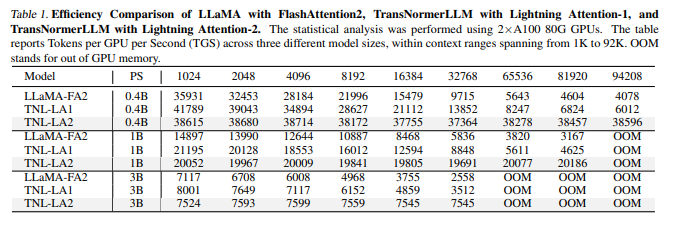
A team of researchers has introduced Lightning Attention-2, an efficient linear attention mechanism for handling unlimited-length sequences without compromising speed. It uses tiling to divide computation into intra-block and inter-block components, optimizing linear attention’s computational characteristics. The research addresses the limitations of current linear attention algorithms, particularly the challenges associated with cumulative summation, and provides a breakthrough for large language models that require processing long sequences.
Various experiments conducted on different model sizes and sequence lengths validate the performance and computational advantages of Lightning Attention-2. Implementing Lightning Attention-2 in Triton makes it IO-aware and hardware-friendly, enhancing its efficiency. The algorithm exhibits consistent training and inference speeds across varied sequence lengths. It even surpasses other attention mechanisms in speed and accuracy, addressing the challenges of cumulative summation and offering a breakthrough for large language models processing long sequences.
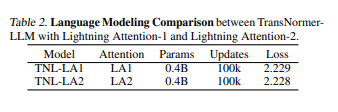
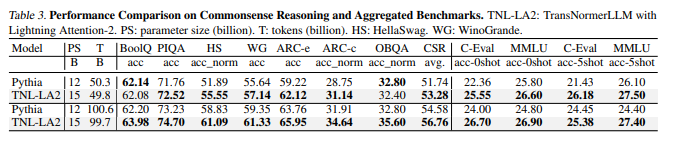
Conclusively, the research introduces Lightning Attention-2, an implementation of linear attention that overcomes computational challenges in the causal setting. Utilizing “divide and conquer” and tiling techniques, this approach impressively tackles the current limitations of linear attention algorithms, especially cumsum challenges. Demonstrating unwavering training speeds and even surpassing existing attention mechanisms, Lightning Attention-2 holds immense potential for advancing large language models, especially those managing extended sequences. Future endeavors involve incorporating sequence parallelism to train exceptionally long sequences, overcoming prevailing hardware constraints.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.