Causation or Coincidence? Evaluating Large Language Models’ Skills in Inference from Correlation
Understanding why things happen, known as causal inference, is a key part of human intelligence. There are two main ways we gain this ability: one is through what we’ve learned from experience, like knowing that touching a hot stove causes burns based on common sense; the other is through pure causal reasoning, where we formally think through and argue about cause and effect using established procedures and rules from the field of causal inference.
Recent studies label Large Language Models (LLMs) as “causal parrots,” highlighting their tendency to echo training data. While many studies assess LLMs’ causal abilities by treating them as knowledge bases, the focus on empirical knowledge overlooks their potential for formal causal reasoning from correlational data. To evaluate Large Language Models’ (LLMs) pure causal reasoning abilities, researchers from Max Plank, ETH Zurich, University of Michigan, and Meta have introduced the CORR2CAUSE dataset. It is the first dataset specifically designed to assess when it is valid or invalid to infer causation from correlation.
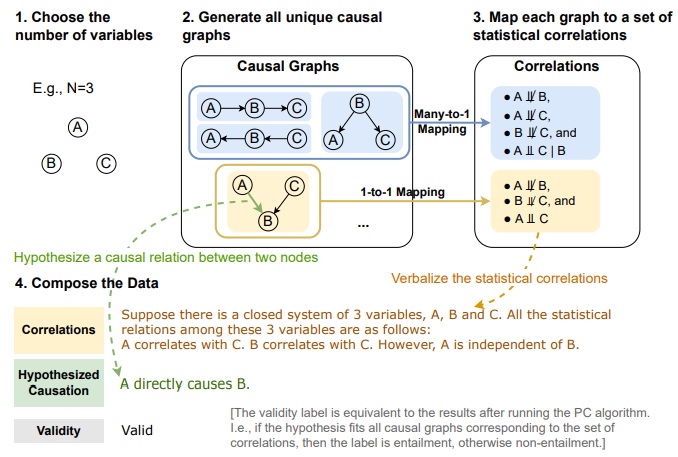
The above figure shows the pipeline of the data construction process. The dataset’s creation follows a systematic process grounded in the formal framework of causal discovery, incorporating rules to deduce causal relationships based on statistical correlations in observational data. Based on the CORR2CAUSE dataset containing 200,000 samples, the study addresses two primary research questions:
- How effectively do current Large Language Models (LLMs) perform on this task?
- Can existing LLMs be retrained or repurposed to develop robust causal inference skills for this task?
Through extensive experiments, the researchers empirically demonstrate that none of the seventeen investigated LLMs excel in this pure causal inference task. Additionally, they show that while LLMs can exhibit improved performance after fine-tuning, the acquired causal inference skills lack robustness. The key contributions of the study include proposing the novel CORR2CAUSE task to assess LLMs’ pure causal inference, creating a dataset of over 200,000 samples, evaluating the performance of seventeen LLMs (all performing poorly), and investigating the limitations of fine-tuning in achieving robust causal inference skills in out-of-distribution scenarios.
To prevent potential issues associated with Goodhart’s law, researchers suggest using this dataset to assess the pure causal inference skills of LLMs that have not been exposed to it. Acknowledging the current limitations in the reasoning abilities of LLMs and the challenge of distinguishing genuine reasoning from knowledge derived from training data, the authors further emphasise the importance of focusing on efforts within the community to accurately disentangle and measure both abilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..Don’t Forget to join our Telegram Channel
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.