Unmasking the Web’s Tower of Babel: How Machine Translation Floods Low-Resource Languages with Low-Quality Content
Much of the modern Artificial Intelligence (AI) models are powered by enormous training data, ranging from billions to even trillions of tokens, which is only possible with web-scraped data. This web content is translated into numerous languages, and the quality of these multi-way translations suggests they were primarily created using Machine Translation (MT). This research paper studies the impact low-cost MT has on the web and on large multi-lingual language models (LLMs).
Prior works have identified MT in the web corpora, but only a few have used multi-way parallelism in their study, and the authors of this research paper have used the same in their work. The researchers created translation tuples of two or more sentences in different languages, each corresponding to translations of one another, and denoted this dataset as Multi-Way ccMatrix (MWccMatrix).
The process involves iterating through all pairs of sentences in ccMatrix (created by embedding web-scraped sentences into multi-lingual space), prioritizing them based on the LASER margin score, and adding new pairs to the MWccMatrix dataset. The researchers use a method that deduplicates the corpus, i.e., it adds each distinct sentence only once. They avoid repeating sentences in the dataset but allow near-duplicates, i.e., multiple sentences of the same language differing mainly in punctuation or capitalization.
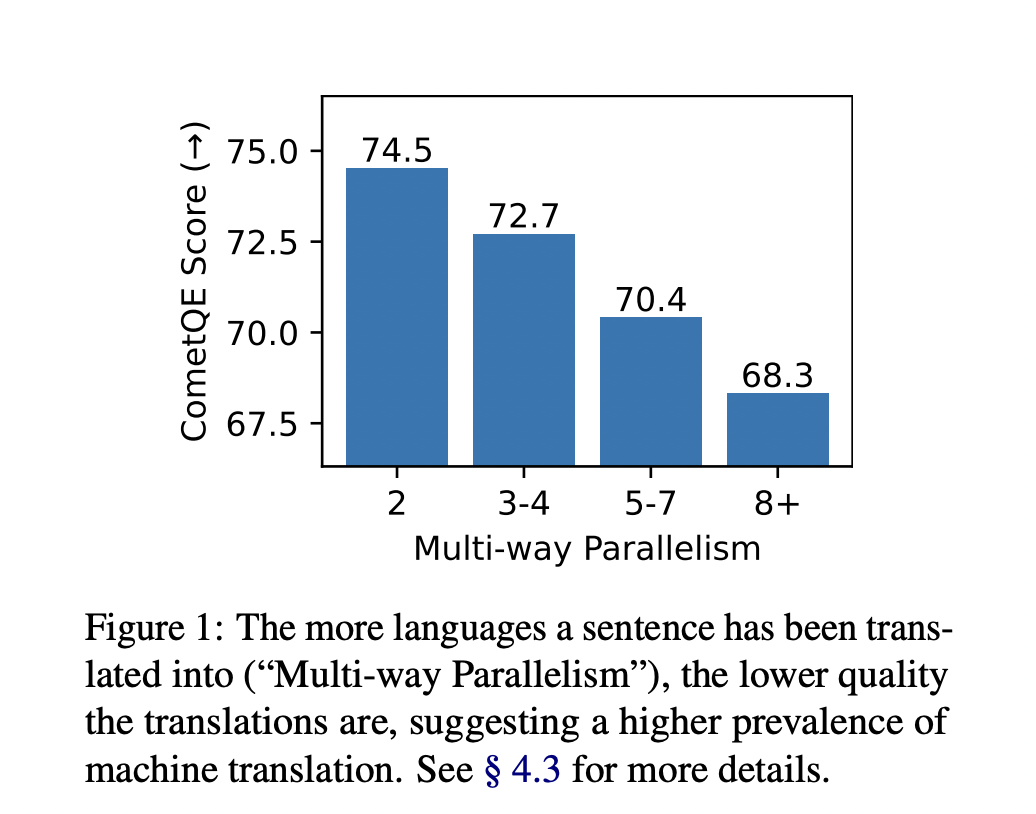
Their analysis suggests that much of the web is MT. They compared the total number of unique sentences in the MWccMatrix to that in the Common Crawl dataset. They found that languages like English and French have a high percentage of unique sentences with at least one translation (9.4% and 17.5% respectively). They also found that translations on the web are highly multi-way parallel, with the low-resource languages having an average parallelism of 8.6. Additionally, these multi-way translations have a significantly lower quality as compared to 2-way parallel translations.
Furthermore, the findings show that multi-way parallel data generally consists of shorter, more predictable sentences and has a different topic distribution. The data is more likely to be from the conversation and opinion topic. This particularly affects the fluency and accuracy of multi-lingual LLMs and leads to more hallucinations and bias. The researchers suggest that the selection bias is because of the low-quality content that is likely produced to generate ad revenue. Data is translated into many lower-resource languages to target the audience for the same reason, which affects its quality.
In conclusion, the researchers also pointed out some methods to tackle the problem of MT output in training data. They suggest that MT detection, along with filtering bitext, should also be used in filtering text in lower resource languages. This would help detect low-quality data, especially in lower resource languages, prevent hallucinations and bias, and eventually lead to a better performance of multi-lingual LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.