DeepSeek-AI Proposes DeepSeekMoE: An Innovative Mixture-of-Experts (MoE) Language Model Architecture Specifically Designed Towards Ultimate Expert Specialization
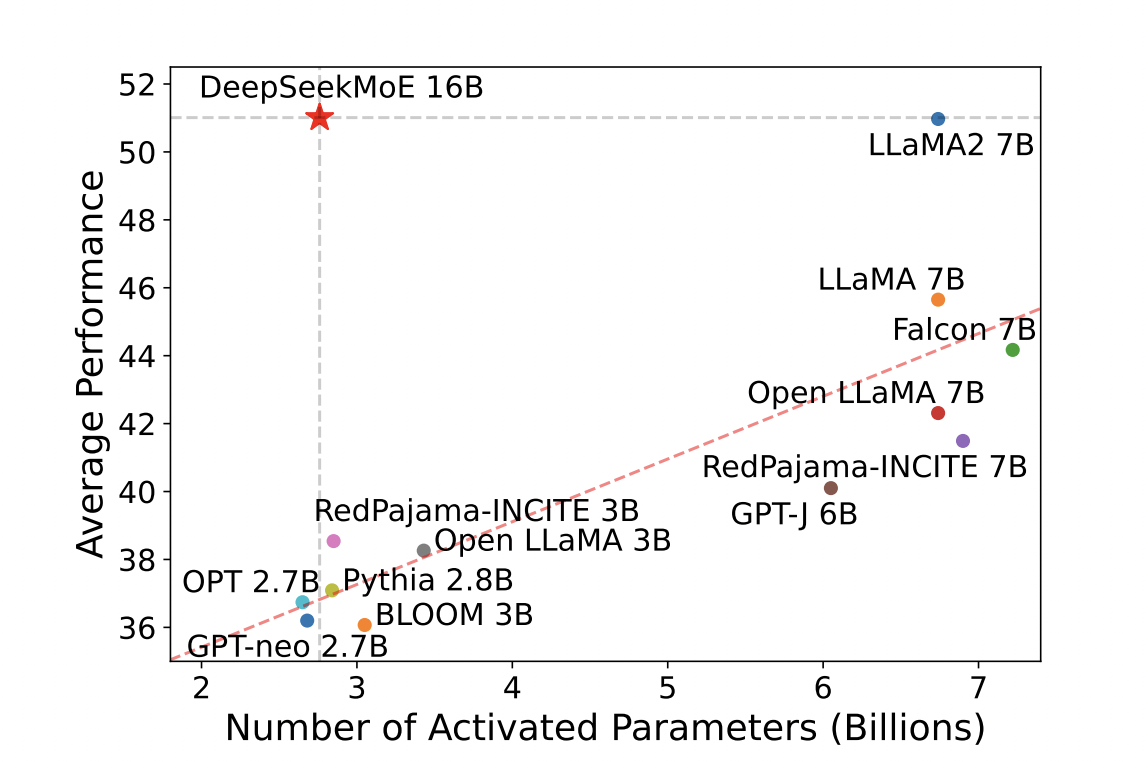
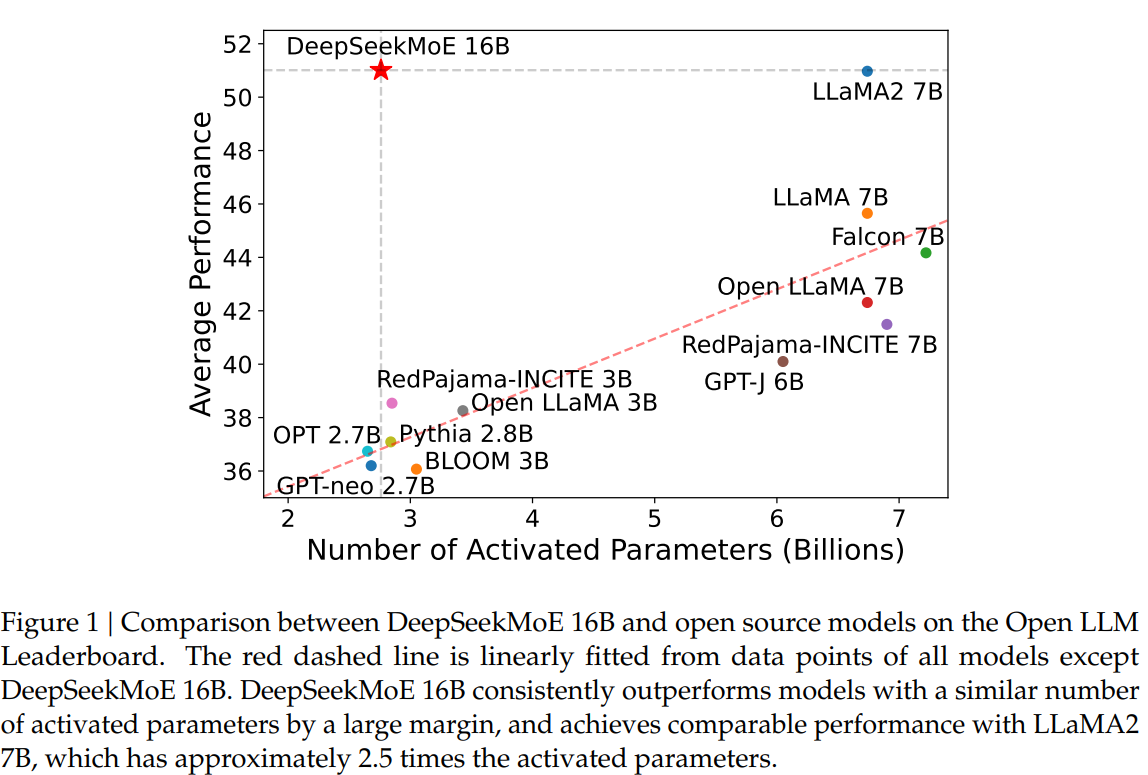
The landscape of language models is evolving rapidly, driven by the empirical success of scaling models with increased parameters and computational budgets. In this era of large language models, Mixture-of-Experts (MoE) architecture emerges as a key player, offering a solution to manage computational costs while scaling model parameters. However, challenges persist in ensuring expert specialization in conventional MoE architectures like GShard, which activate the top-𝐾 out of 𝑁 experts. Recent applications of MoE architectures in Transformers have showcased successful attempts at scaling language models to substantial sizes, accompanied by remarkable performance, underscoring the vast potential of MoE language models.
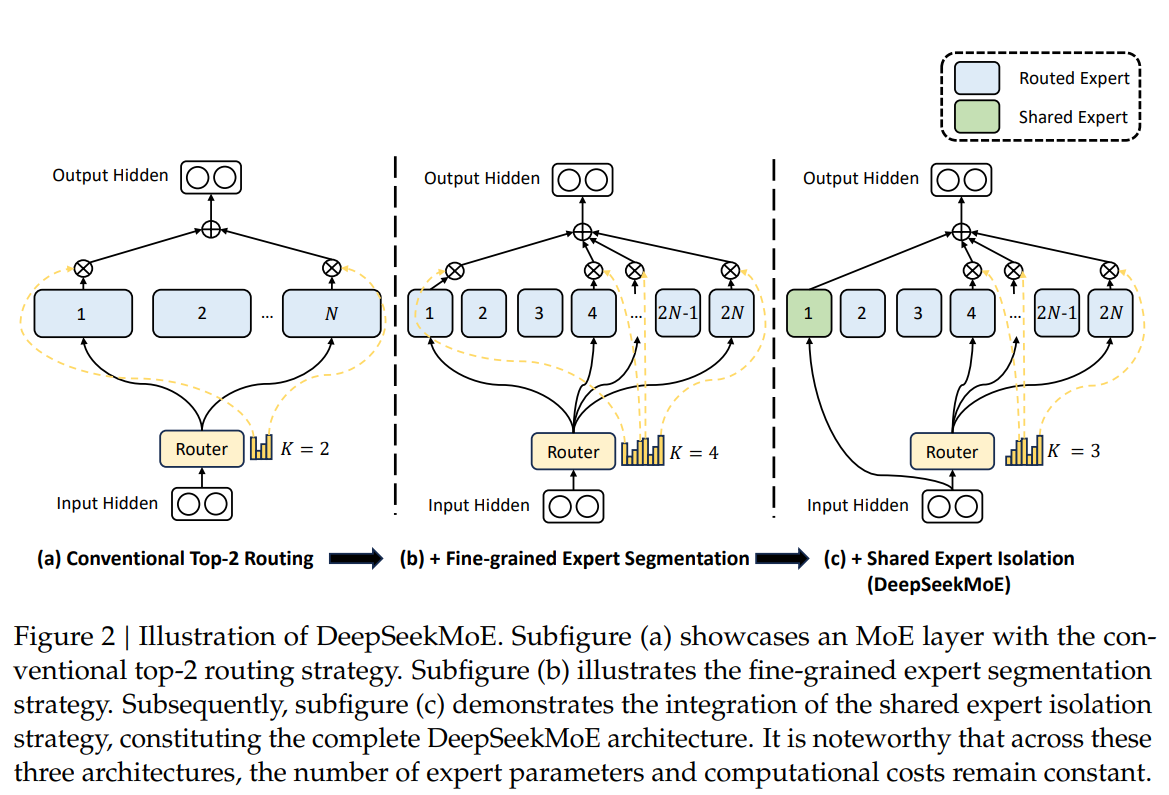
The conventional MoE architecture replaces Feed-Forward Networks (FFNs) in a Transformer with MoE layers, where each layer comprises multiple experts structurally identical to a standard FFN. Each token is assigned to one or two experts, leading to two primary challenges: Knowledge Hybridity and Knowledge Redundancy. These issues arise due to the limited number of experts, causing tokens assigned to a specific expert to cover diverse knowledge and, in turn, compromising the model’s ability to utilize this information simultaneously.
In response to these challenges, a team of researchers from DeepSeek-AI proposed DeepSeekMoE—an innovative MoE architecture designed to achieve ultimate expert specialization. As illustrated in Figure 2, this architecture employs two principal strategies: Fine-Grained Expert Segmentation and Shared Expert Isolation.
Fine-grained expert Segmentation addresses the limitation of a fixed number of experts by splitting the FFN intermediate hidden dimension. This strategy allows for a finer segmentation of experts, activating more fine-grained experts while maintaining a constant number of parameters and computational costs. The result is a flexible and adaptable combination of activated experts, enabling precise knowledge acquisition and higher levels of specialization. The fine-grained expert segmentation substantially enhances the combinatorial flexibility of activated experts, potentially leading to more accurate and targeted knowledge acquisition.
Shared Expert Isolation complements fine-grained segmentation by isolating specific experts as shared experts, always activated regardless of the routing module. These shared experts aim to capture and consolidate common knowledge across various contexts, mitigating redundancy among other routed experts. This isolation enhances parameter efficiency, ensuring each routed expert retains specialization by focusing on distinctive aspects. Notably, this shared expert isolation strategy draws inspiration from Rajbhandari et al. (2022) but is approached from an algorithmic standpoint.
The paper delves into the issue of load imbalance that automatically learned routing strategies may encounter, leading to the risks of routing collapse and computation bottlenecks. The authors introduce expert- and device-level balance loss to mitigate these risks, emphasizing the importance of balanced computation across devices.
The training data, sourced from a large-scale multilingual corpus by DeepSeek-AI, focuses primarily on English and Chinese but includes other languages. For validation experiments, a subset containing 100B tokens is sampled from the corpus to train their models.
Evaluation spans various benchmarks encompassing language modeling, language understanding, reasoning, reading comprehension, code generation, and closed-book question answering. DeepSeekMoE is rigorously compared against baselines, including Hash Layer, Switch Transformer, and GShard, consistently demonstrating superiority within the MoE architecture landscape.
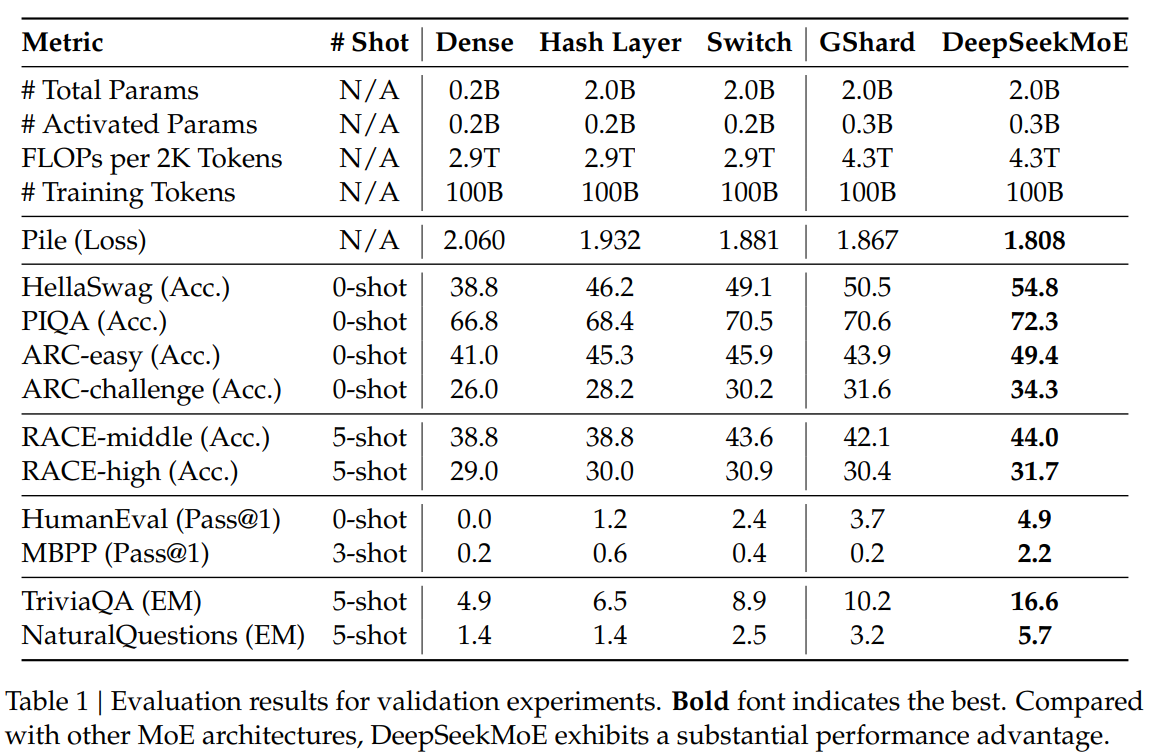
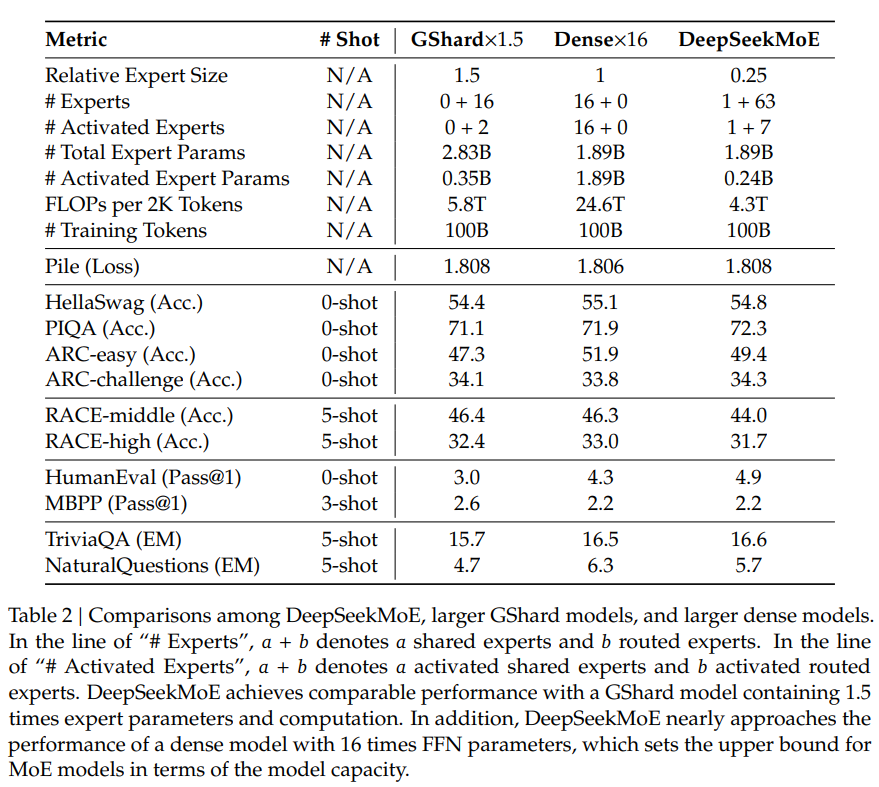
The evaluation results, detailed in Table 1 and Table 2, highlight the strengths of DeepSeekMoE over other models. Noteworthy observations include the significant performance advantages of DeepSeekMoE over GShard, especially when considering sparse architectures and comparable total parameters. The paper also presents comparisons with larger GShard models and denser models, showcasing the scalability and efficiency of DeepSeekMoE.
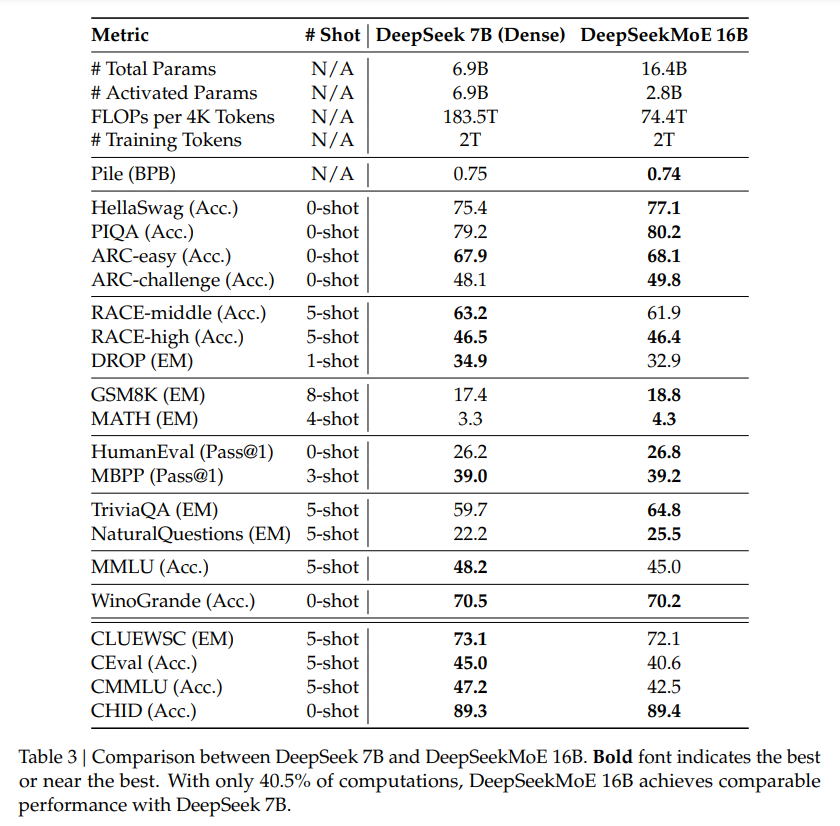
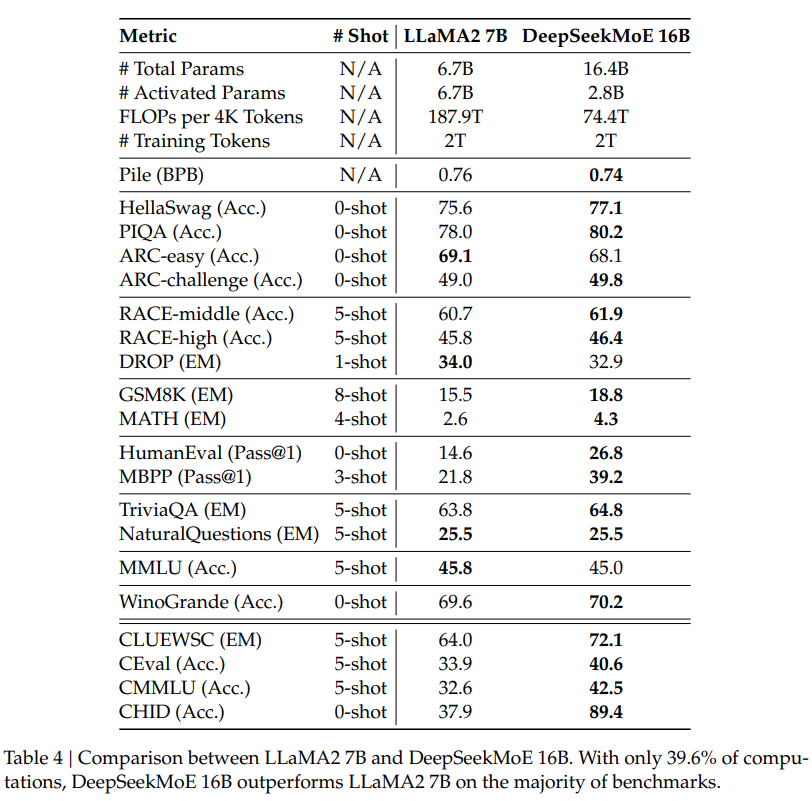
Previous research on MoE models has often suggested limited gains from fine-tuning. However, the authors cite findings by Shen et al. (2023) indicating that MoE models, specifically DeepSeekMoE 16B, can benefit from supervised fine-tuning. The experimental results demonstrate the adaptability and comparable performance of DeepSeekMoE Chat 16B in alignment tasks.
Buoyed by the success of DeepSeekMoE 16B, the authors embark on a preliminary exploration to scale up DeepSeekMoE to 145B. In this initial study, DeepSeekMoE 145B, trained on 245B tokens, demonstrates consistent advantages over GShard and promises to match or exceed the performance of DeepSeek 67B (Dense). The authors plan to make the final version of DeepSeekMoE 145B publicly available.
In conclusion, the paper introduces DeepSeekMoE as a groundbreaking MoE language model architecture, emphasizing ultimate expert specialization. Through innovative strategies, including fine-grained expert segmentation and shared expert isolation, DeepSeekMoE achieves significantly higher expert specialization and performance compared to existing MoE architectures. The scalability of DeepSeekMoE is demonstrated through experiments, and the authors provide a glimpse into its potential at an unprecedented scale of 145B parameters. With the release of the DeepSeekMoE 16B model checkpoint to the public (GitHub), the authors aim to contribute valuable insights to both academia and industry, propelling the advancement of large-scale language models.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.