Meet ‘AboutMe’: A New Dataset And AI Framework that Uses Self-Descriptions in Webpages to Document the Effects of English Pretraining Data Filters
With the advancements in Natural Language Processing and Natural Language Generation, Large Language Models (LLMs) are being frequently used in real-world applications. With their ability to mimic human behavior, these models, with their general-purpose nature, have stepped into every field and domain.
Though these models have gained significant attention, these models represent a constrained and skewed collection of human viewpoints and knowledge. The pretraining data’s composition is the reason for this bias since it has a big impact on the model’s behavior.
Researchers have been putting in efforts to have an additional focus on understanding and documenting the transformations made to the data before pretraining. Pretraining data curation is a multi-step process with multiple decision points that are frequently based on subjective text quality judgments or performance against benchmarks.
In a recent study, a team of researchers from the Allen Institute for AI, the University of California, Berkeley, Emory University, Carnegie Mellon University, and the University of Washington introduced a new dataset and framework called AboutMe. The study highlights the numerous unquestioned assumptions that exist in data curation workflows. With AboutMe, the team has attempted to document the effects of data filtering on text rooted in social and geographic contexts.
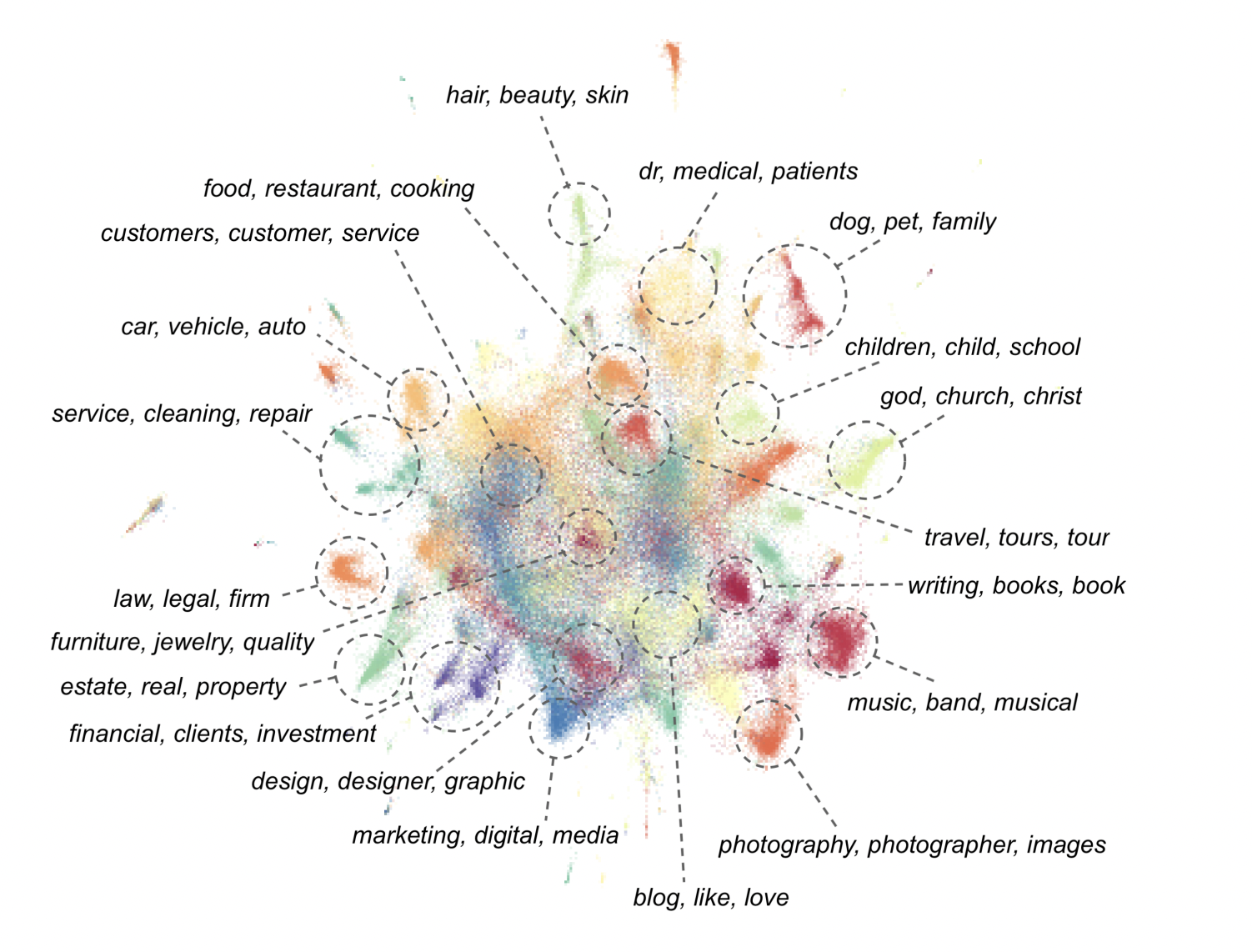
The lack of extensive, self-reported sociodemographic data associated with language data is one of the problems facing sociolinguistic analysis in Natural Language Processing. Text can be traced back to general sources such as Wikipedia, but at a more granular level, it’s frequently unknown who created the information. The team in this study has found websites, particularly ‘about me’ pages, by utilizing pre-existing patterns in web data. This allows an unprecedented understanding of whose language is represented in web-scraped text.
Using data from the ‘about me’ sections of websites, the team has performed sociolinguistic analyses to measure the topical interests, positioning individuals or organizations, self-identified social roles, and associated geographic locations of website authors. Ten quality and English ID filters from earlier research on LLM development have been used on these web pages to examine the effect of filtering on the kept or deleted pages.
The team has shared that their main goal was to find trends in website origin-related behavior both inside and between filters. The results have shown that implicit preferences for specific subject areas are displayed by model-based quality filters, which causes text related to various professions and vocations to be removed at varied rates. Furthermore, filtering techniques that presume pages are monolingual may unintentionally eliminate content from non-anglophone parts of the globe.
In conclusion, this research has highlighted the intricacies involved in data filtering during LLM development and its consequences for the portrayal of varied viewpoints in language models. The study’s main goal is to raise awareness of the intricate details that go into pretraining data curation procedures, particularly when considering social factors. The team has stressed on the need for more research on pretraining data curation procedures and their social implications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.