Parameter-Efficient Sparsity Crafting (PESC): A Novel AI Approach to Transition Dense Models to Sparse Models Using a Mixture-of-Experts (Moe) Architecture
The emergence of large language models (LLMs) like GPT, Claude, Gemini, LLaMA, Mistral, etc., has greatly accelerated recent advances in natural language processing (NLP). Instruction tweaking is a well-known approach to training LLMs. This method allows LLMs to improve their pre-trained representations to follow human instructions using large-scale, well-formatted instruction data. However, these tasks are complex in and of themselves, making fine-tuning the model difficult. For general tasks, larger models may not be able to maximize losses from competing activities, leading to poor performance.
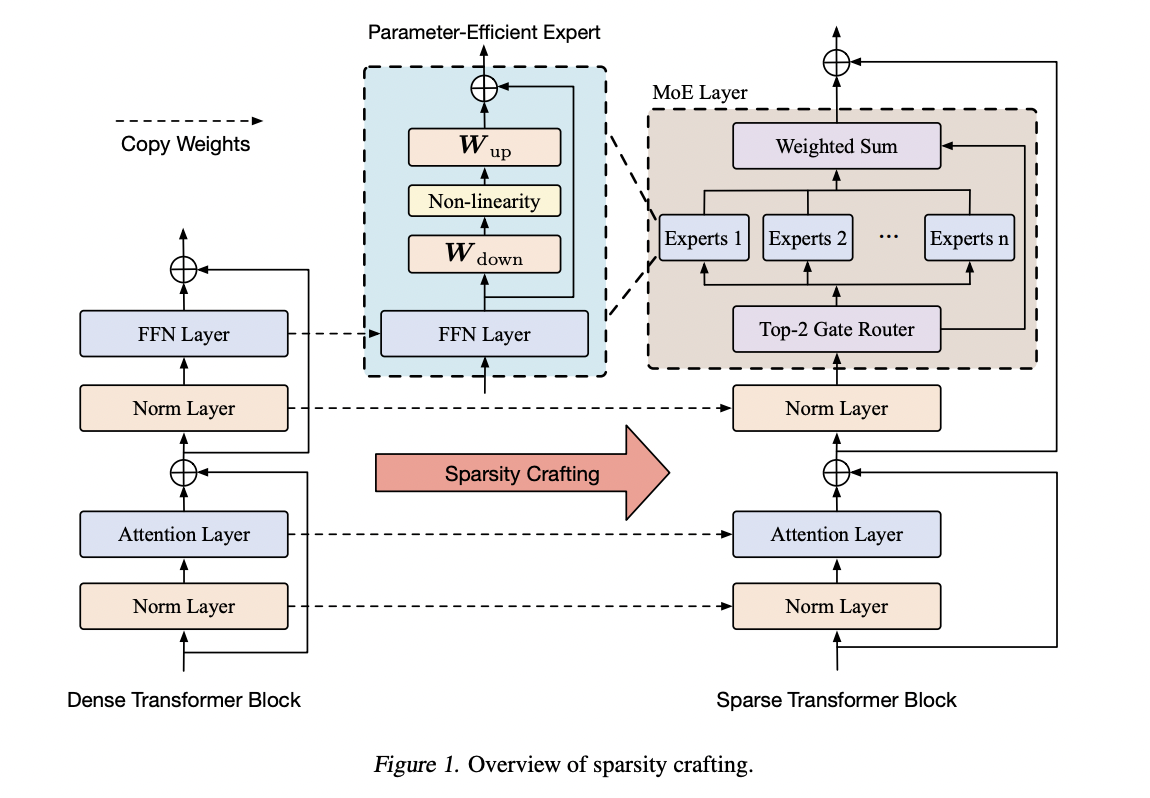
Increasing the model’s capacity can enhance instruction tuning’s efficacy for general tasks. Most LLMs, however, are dense pre-trained models built using transformer architecture, severely restricting scalability when tweaking the instructions. Instruction tweaking offers the chance to obtain outstanding performance on general tasks by turning dense models into MoE models. The MoE models’ expert layers are initially set up as duplicates of the original feedforward neural network (FFN) layers to make this change. Training such massive models is hindered by computational costs and GPU memory constraints caused by the need to update the expert weights in the MoE layer due to the large parameter scale of existing LLMs.
New research by the Shanghai Artificial Intelligence Laboratory and The Chinese University of Hong Kong presents Parameter-Efficient Sparsity Crafting (PESC), a method for transforming dense models into sparse ones using the MoE blueprint. By integrating adapters into sparse models’ MoE layers, PESC makes it possible to differentiate experts without changing their weights individually. This method drastically cuts down on GPU memory needs and computational expenses. Because adapters are integrated, the model capacity can be expanded with minimal increase in parameters.
To differentiate across experts without changing the weights of each expert in the MoE layers, PESC inserts adapters into the MoE layers of sparse models. The researchers also update other sparse model weights using the QLoRA methodology, a popular PEFT method.
The researchers simultaneously trained the sparse model with MoE layers on various skills, including coding, mathematics, and other general talents from many areas, to illustrate the model’s learning capabilities. For instruction tuning, this training integrated three separate datasets from different domains: SlimORCA, Magicoder, and MetaMathQA datasets. The final dataset included 520k instructions after filtering and sampling.
Furthermore, they have utilized the PESC method to create Camelidae sparse models. Camelidae-8Ï34B outperforms GPT-3.5 in general and reaches SOTA performance on all open-source sparse models.
Check out the Paper and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.