This AI Paper from Germany Proposes ValUES: An Artificial Intelligence Framework for Systematic Validation of Uncertainty Estimation in Semantic Segmentation
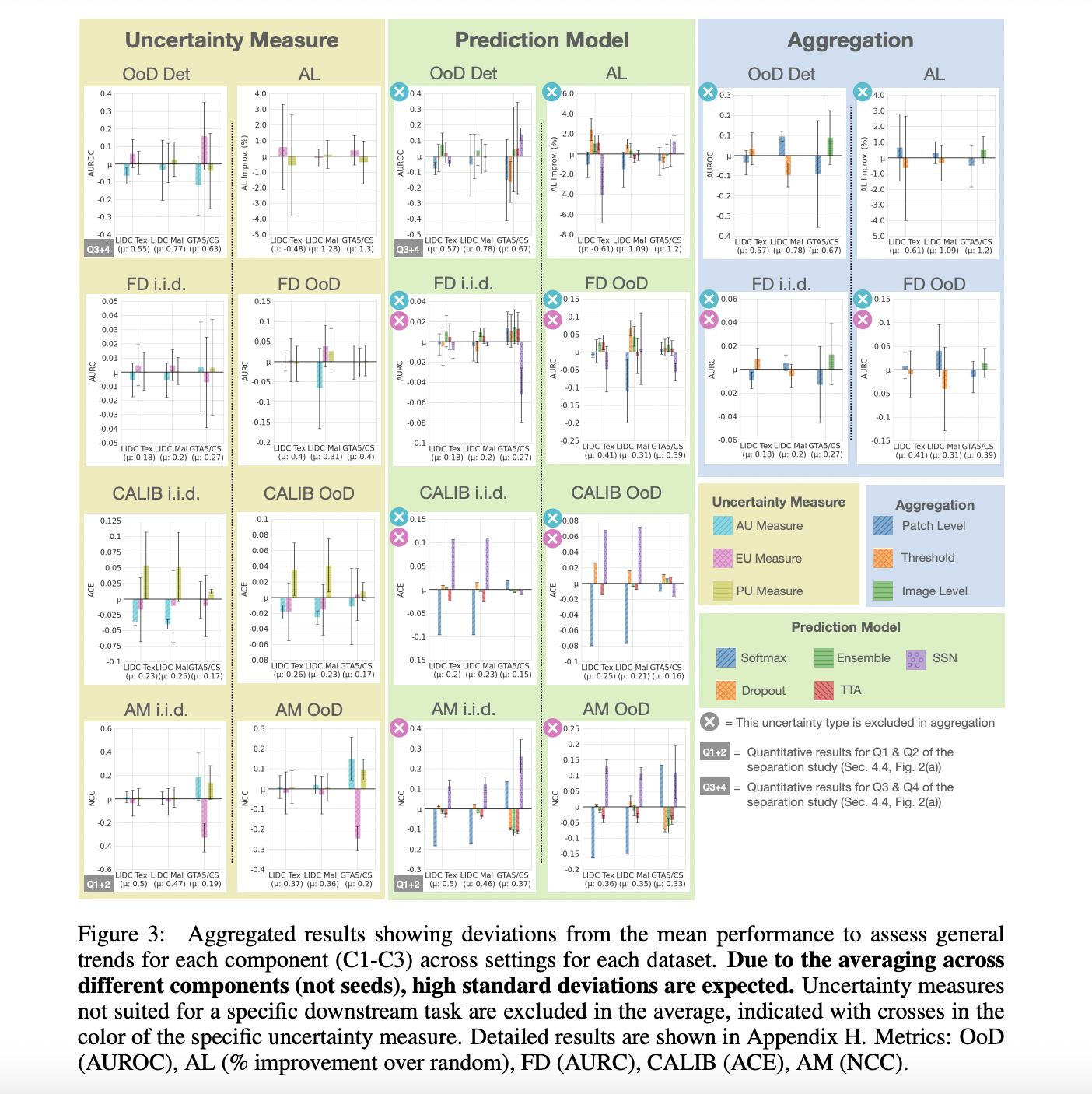
In the constantly evolving field of machine learning, particularly in semantic segmentation, the accurate estimation and validation of uncertainty have become increasingly vital. Despite numerous studies claiming advances in uncertainty methods, there remains a disconnection between theoretical development and practical application. Fundamental questions linger, such as whether it is feasible to separate data-related (aleatoric) and model-related (epistemic) uncertainty in real-world scenarios and identify the critical components of an uncertainty method for practical performance.
The study’s primary focus is on the challenge of effectively utilizing uncertainty methods in segmentation. This challenge arises from ambiguities around the separation of aleatoric and epistemic uncertainty. While theoretical studies often claim specific types of uncertainty captured by certain methods, these claims lack rigorous empirical validation. This gap between theory and practice often needs to be clarified and consistent in the field.
The German Cancer Research Center researchers have developed a comprehensive ValUES framework to address these gaps. ValUES aims to provide a controlled environment for studying data ambiguities and distribution shifts, facilitate systematic ablations of relevant method components, and create test beds for predominant uncertainty applications such as Out-of-Distribution (OoD) detection, active learning, failure detection, calibration, and ambiguity modeling. This framework is designed to overcome the pitfalls in current validation practices of uncertainty methods for semantic segmentation.

The empirical study using ValUES demonstrated several critical findings. It was observed that the separation of uncertainty types is possible in simulated environments but only sometimes translates seamlessly to real-world data. The study also revealed that the aggregation of scores is a crucial but often overlooked component of uncertainty methods. Ensembles were the most robust across various tasks and settings, while test-time augmentation emerged as a feasible lightweight alternative.
The approach systematically dissects the components of uncertainty methods, examining aspects such as the segmentation backbone, prediction models, uncertainty measures, and aggregation strategies. This detailed analysis allows for a deeper understanding of each component’s role and interdependencies, clarifying what drives uncertainty estimation improvements.
While aleatoric uncertainty measures captured ambiguity better than epistemic uncertainty measures in simulated data, this was not consistently the case in real-world datasets. The study also found that the effectiveness of separating epistemic from aleatoric uncertainty varied greatly depending on the inherent ambiguities in the training and test data. Evaluating downstream tasks, including OoD detection, active learning, and failure detection, provided practical insights for selecting the most suitable uncertainty method based on specific application needs.
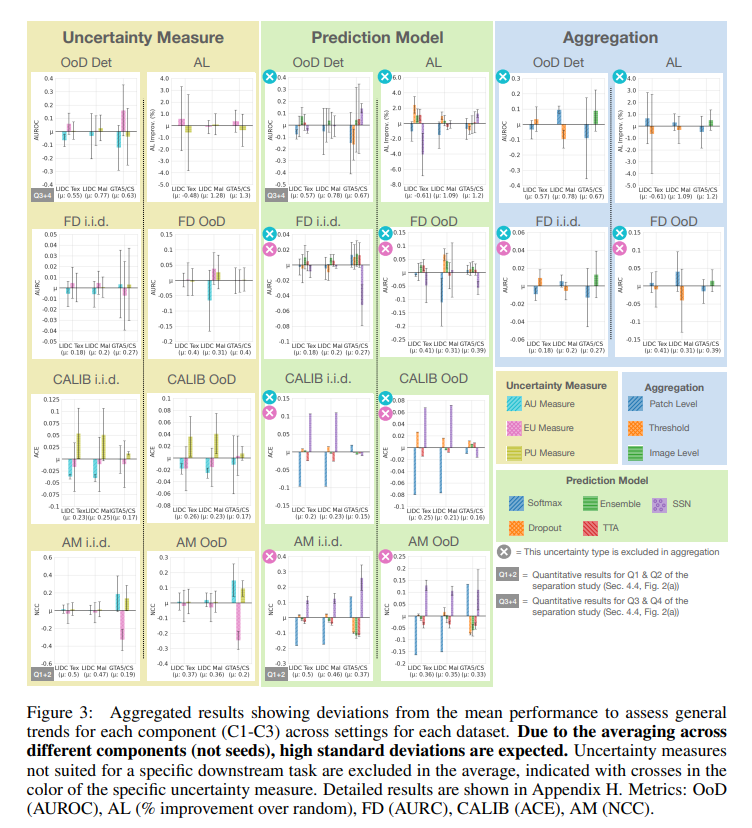
The research concludes by emphasizing that the feasibility and benefits of separating different types of uncertainty should not be assumed but rather require empirical evidence. The study also underscores the importance of selecting optimal components of uncertainty methods based on dataset properties and the interplay between these components.
In conclusion, this study bridges the gap between theoretical and practical aspects of uncertainty estimation in semantic segmentation and offers a robust foundation for future research. By systematically dissecting and validating uncertainty methods, the researchers have provided a comprehensive guide for practitioners and academics, facilitating the development of more reliable and efficient segmentation systems.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.