Fireworks AI Introduces FireAttention: A Custom CUDA Kernel Optimized for Multi-Query Attention Models
Mixture-of-Experts (MoE) is an architecture based on the “divide and conquer” principle to solve complex tasks. Multiple individual machine learning (ML) models (called experts) work individually based on their specializations to provide the most optimal results. To better understand their use cases, Mistral AI recently released Mixtral, an open-source high-quality MoE model that outperformed or matched GPT-3.5 on most standard benchmarks and was first hosted on Fireworks AI’s platform.
Although the platform demonstrated an impressive inference speed of up to 175 tokens/sec, the researchers at Fireworks AI have tried to improve the efficiency of serving MoE models without significantly impacting the quality. They have introduced a large language model (LLM) serving stack having FP16 and FP8-based FireAttention, which delivers four times better speed-up than other open-source software. FireAttention is a custom CUDA kernel that has been optimized for Multi-Query Attention Models like Mixtral and for FP16 and FP8 support in hardware.
Quantization methods like SmoothQuant and AWQ fell short of improving the model performance, especially during generation. The main reason for that is LLM activations have non-uniform distribution, which is challenging for integer methods. On the contrary, FP8 leverages hardware support, which makes it flexible to deal with such distributions.
For evaluation, the researchers have considered a very general setup of prompt length 1K and the number of generated tokens as 50, which covers long prompt and short generation use cases. Their quality and performance study is based on the Mixtral model. They focused on language understanding and used the MMLU metric for measuring the model quality. The MMLU metric consists of enough test data examples, and the Mixtral model also performs quite well on it, allowing for easy detection of any quantization error. For assessing the latency and throughput, they used the following two metrics: token generation latency for a given number of requests/second (RPS) and total request latency for a given RPS.
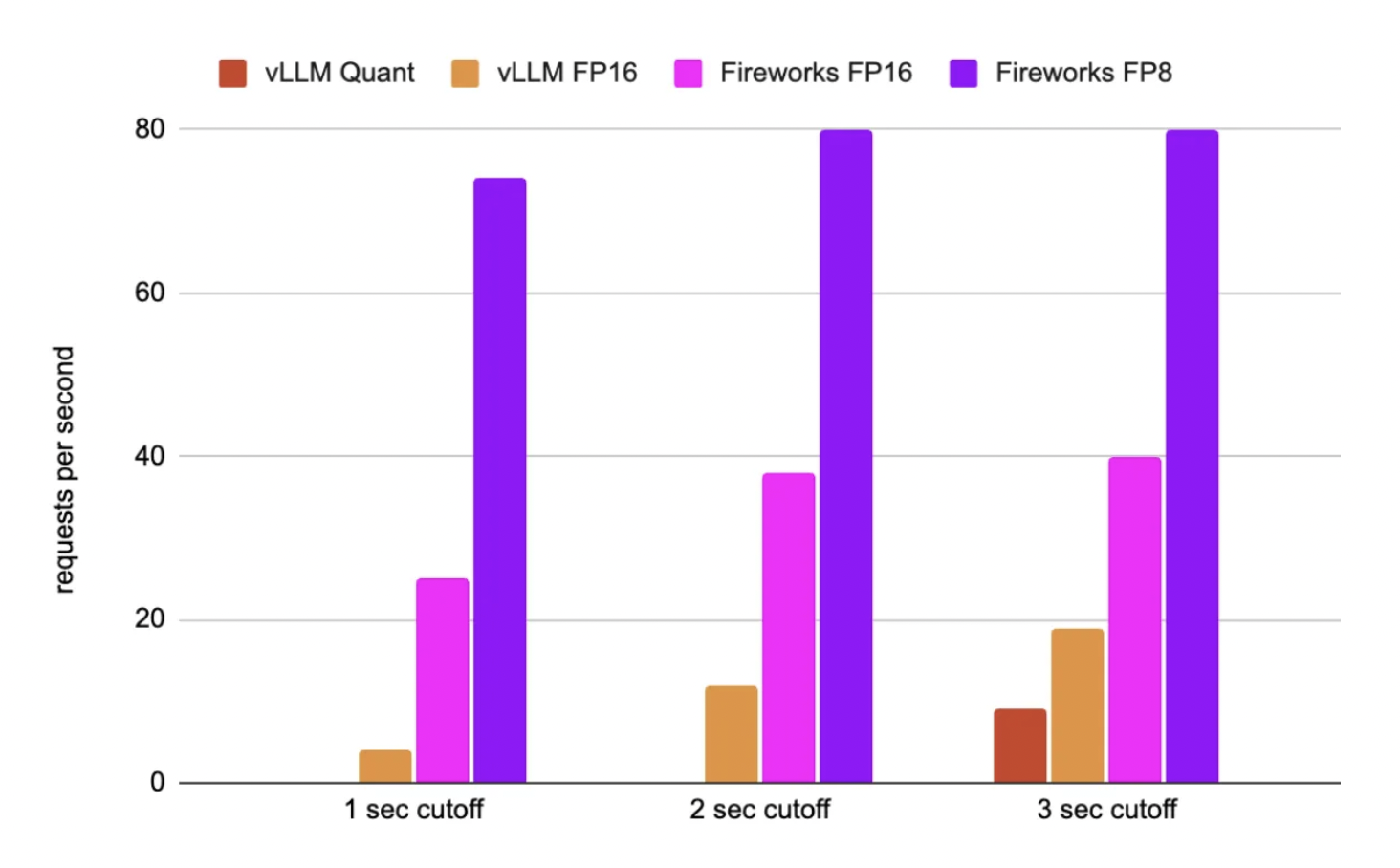
The results show that the Fireworks FP16 Mixtral model implementation is superior to that of vLLM (a high-throughput and memory-efficient inference and serving engine for LLMs). Moreover, the FP8 implementation is significantly better than the already efficient FP16 one. Additionally, it reduces the model size by two times and, therefore, allows for a more efficient deployment. When it is combined with the memory bandwidth and FLOPs speed-ups, it leads to a considerable improvement (2x) of the effective requests/second. Lastly, as there is no one-size-fits-all approach regarding the performance of LLMs, different vLLM and Fireworks LLM service configurations show their strengths in different setups.
In conclusion, FireAttention FP16 and FP8 implementations provide a remarkable tradeoff for LLM in terms of accuracy and performance tradeoff. More specifically, FP8 shrinks the model size twice and improves the number of effective requests/second by the same amount, highlighting its superiority over previous quantization methods. This research paper marks a significant step in developing even more efficient serving for MoE models like Mixtral with negligible impact on quality.
![]()
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.