This AI Paper from China Introduces a Groundbreaking Approach to Enhance Information Retrieval with Large Language Models Using the INTERS Dataset
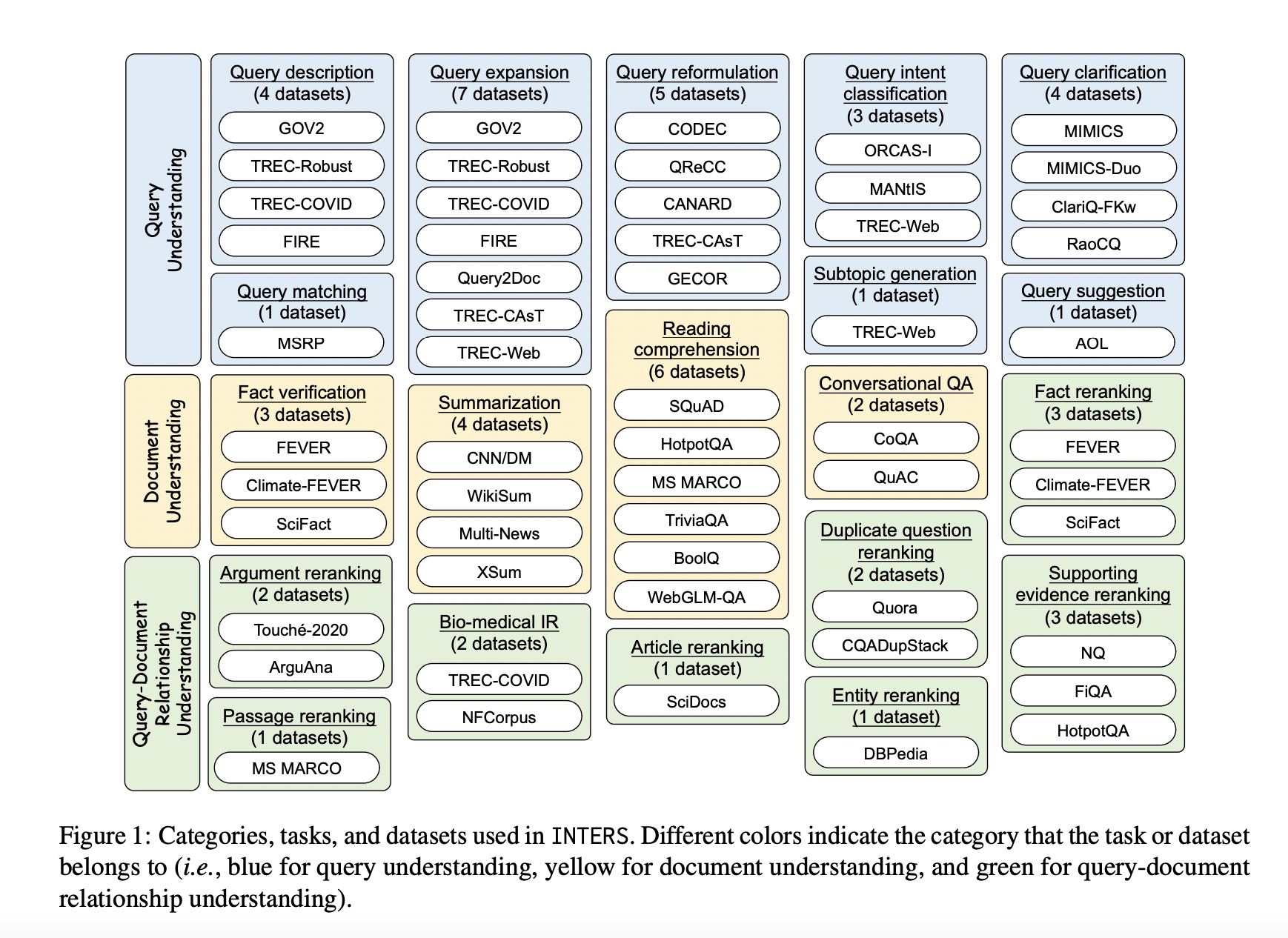
Large Language Models (LLMs) have exhibited remarkable prowess across various natural language processing tasks. However, applying them to Information Retrieval (IR) tasks remains a challenge due to the scarcity of IR-specific concepts in natural language. Addressing this, the idea of instruction tuning has emerged as a pivotal method to elevate LLMs’ capabilities and control. While instruction fine-tuned LLMs have excelled in generalizing to new tasks, a gap exists in their application to IR tasks.

In response, this work introduces a novel dataset, INTERS (INstruction Tuning datasEt foR Search), meticulously designed to enhance the search capabilities of LLMs. This dataset focuses on three pivotal aspects prevalent in search-related tasks: query understanding, document understanding, and the intricate relationship between queries and documents. INTERS is a comprehensive resource encompassing 43 datasets covering 20 distinct search-related tasks.
The concept of Instruction Tuning involves fine-tuning pre-trained LLMs on formatted instances represented in natural language. It stands out by not only enhancing performance on directly trained tasks but also enabling LLMs to generalize to new, unseen tasks. In the context of search tasks, distinct from typical NLP tasks, the focus revolves around queries and documents. This distinction prompts the categorization of tasks into query understanding, document understanding, and query-document relationship understanding.
Tasks & Datasets:
Developing a comprehensive instruction-tuning dataset for a wide range of tasks is resource-intensive. To circumvent this, existing datasets from the IR research community are converted into an instructional format. Categories include (shown in Figure 1):
– Query Understanding: Addresses aspects such as query description, expansion, reformulation, intent classification, clarification, matching, subtopic generation, and suggestion.
– Document Understanding: Encompasses fact verification, summarization, reading comprehension, and conversational question-answering.
– Query-Document Relationship Understanding: Primarily focuses on the document reranking task.
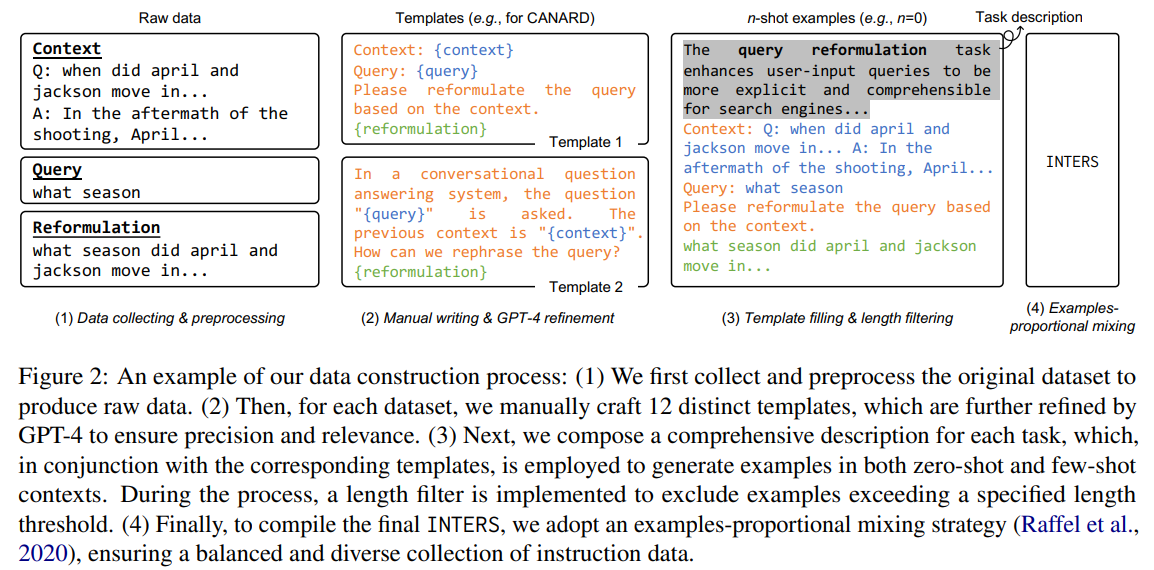
The construction of INTERS (shown in Figure 2) is a meticulous process involving the manual crafting of task descriptions and templates and fitting data samples into these templates. It reflects the commitment to creating a comprehensive and instructive dataset.
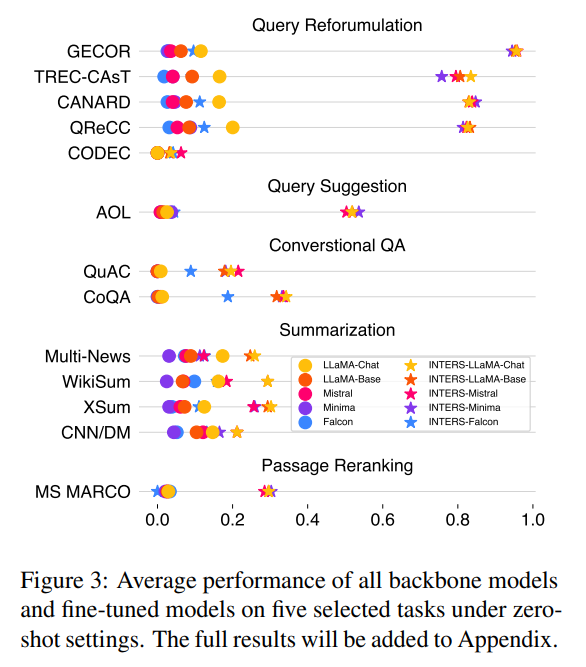
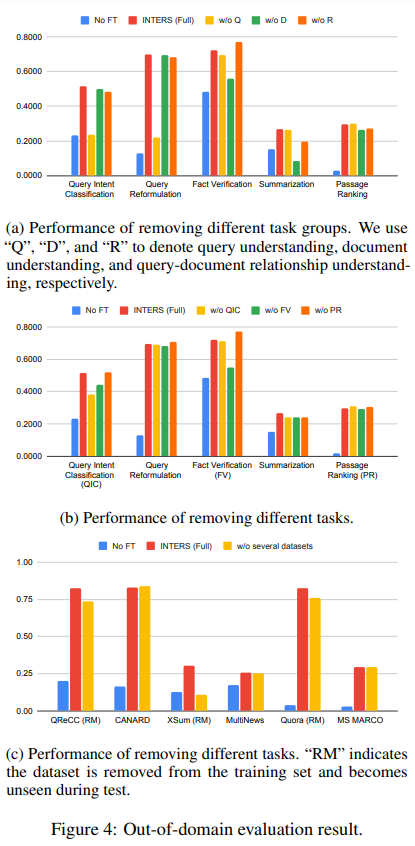
For evaluation, four LLMs of varying sizes are employed: Falcon-RW-1B, Minima-2-3B, Mistral-7B, and LLaMA-2-7B. In an in-domain evaluation (results shown in Figure 3), where all tasks and datasets are exposed during training, the effectiveness of instruction tuning on search tasks is validated. Beyond in-domain evaluation (results are shown in Figure 4), the authors investigate the generalizability of fine-tuned models to new, unseen tasks. Group-level, Task-level, and Dataset-level generalizability are explored, providing insights into the adaptability of instruction-tuned LLMs.
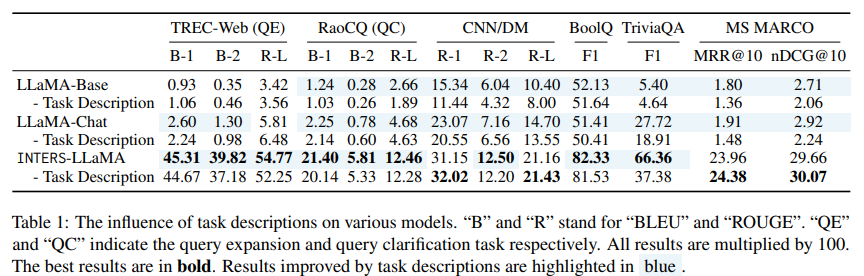
Several experiments aim to understand the impact of different settings within INTERS. Notably, the removal of task descriptions (results present in Table 1) from the dataset significantly affects model performance, highlighting the importance of clear task comprehension.
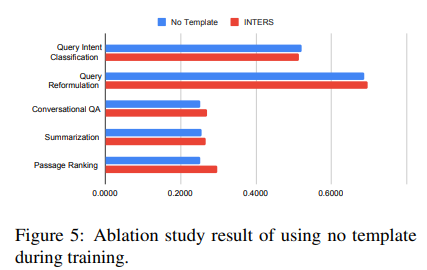
Templates and guiding models in task comprehension are essential components of INTERS. Ablation experiments (as in Figure 5) showcase that the use of instructional templates significantly improves model performance.
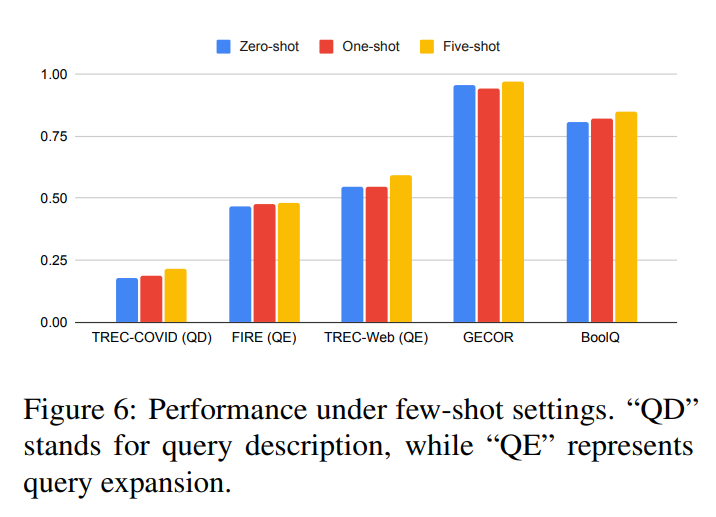
Given INTERS’s mix of zero-shot and few-shot examples, examining few-shot performance is crucial. Testing datasets within models’ input length limits demonstrates (shown in Figure 6) the dataset’s effectiveness in facilitating few-shot learning.
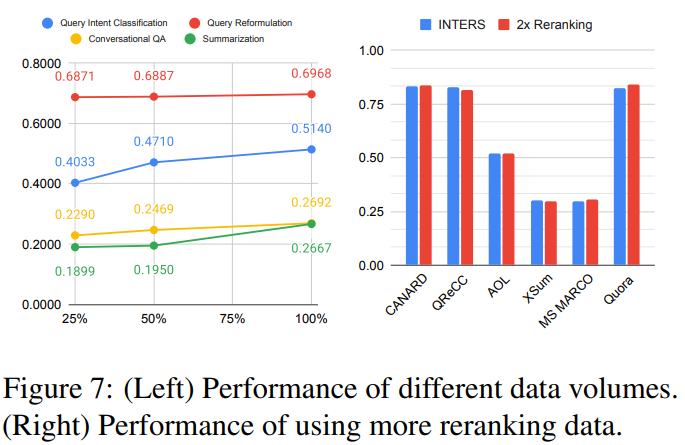
The quantity of training data is explored, with experiments (results shown in Figure 7) indicating that increasing the volume of instructional data generally enhances model performance, albeit with varying sensitivity across tasks.
In summary, this paper presents an exploration of instruction tuning for LLMs applied to search tasks, culminating in the creation of the INTERS dataset. The dataset proves effective in consistently enhancing LLMs’ performance across various settings. The research delves into critical aspects, shedding light on the structure of instructions, the impact of few-shot learning, and the significance of data volumes in instruction tuning. The hope is that this work catalyzes further research in the domain of LLMs, particularly in their application to IR tasks, encouraging ongoing optimization of instruction-based methods to enhance model performance.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.