UCLA Researchers Introduce Group Preference Optimization (GPO): A Machine Learning-based Alignment Framework that Steers Language Models to Preferences of Individual Groups in a Few-Shot Manner
Large Language Models (LLMs) are increasingly employed for various domains, with use cases including creative writing, chatbots, and semantic search. Many of these applications are inherently subjective and require generations catering to different demographics, cultural and societal norms, or individual preferences. Through their large-scale training, current language models are exposed to diverse data that allows them to represent many such opinions. However, expressing these diverse opinions requires steering the LLM generations to user requirements.
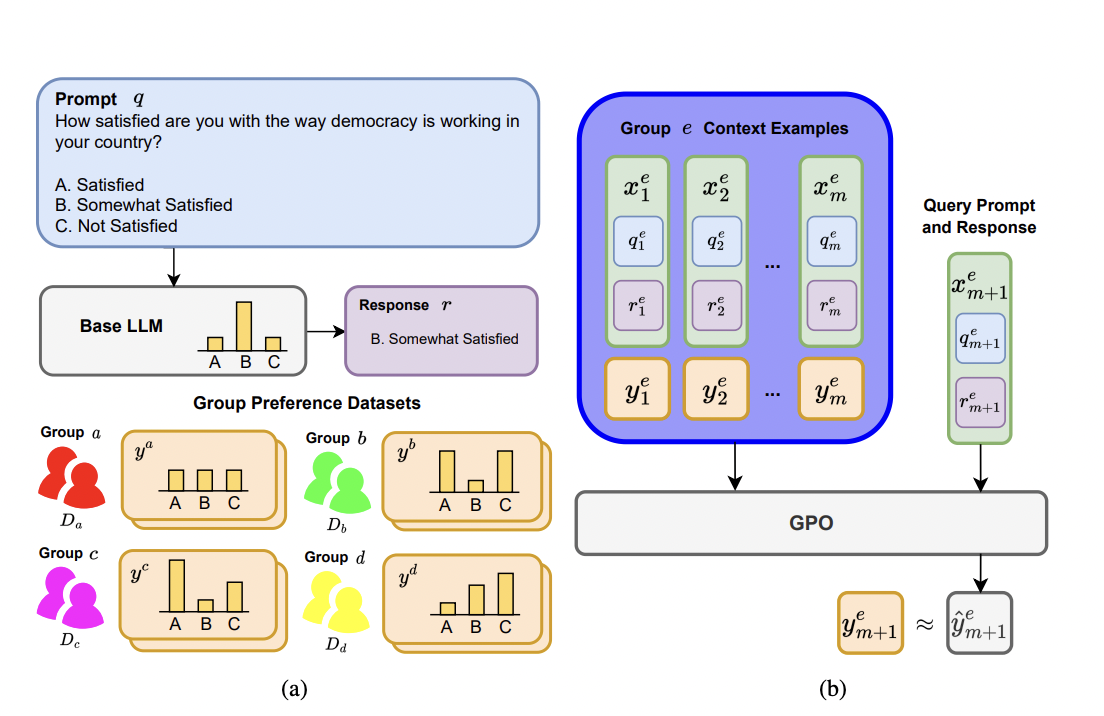
The researchers at the University of California introduced Group Preference Optimization (GPO), which signifies a pioneering approach to aligning large language models (LLMs) with the diverse preferences of user groups efficiently. This alignment is critical for applications involving subjective judgments across varied user demographics. The challenges associated with existing alignment algorithms, characterized by high costs and the need for extensive group-specific preference data and computational resources, are addressed by GPO.
The GPO framework incorporates an independent transformer module, enhancing the base LLM. This module is trained to predict the preferences of specific user groups for LLM-generated content. The parameterization of this module as an in-context autoregressive transformer facilitates few-shot learning, and its training is accomplished through meta-learning on multiple user groups.
Key components of GPO include leveraging few-shot learning to enable the model to adapt to group preferences with minimal data and utilizing meta-learning to train the independent transformer module on diverse user groups, allowing rapid adaptation to new preferences.
Empirical validation was conducted through rigorous evaluations using LLMs of varying sizes. Three human opinion adaptation tasks were considered: aligning with the preferences of US demographic groups, global countries, and individual users. GPO’s performance is compared with existing strategies like in-context steering and fine-tuning methods.
The findings demonstrate that GPO achieves more accurate alignment with group preferences and requires fewer group-specific preferences and reduced training and inference computing resources. This underscores GPO’s efficiency and effectiveness in comparison to existing approaches.
Overall, GPO presents a promising solution for efficiently aligning LLMs with the preferences of diverse user groups, making it particularly applicable to real-world scenarios where nuanced subjective judgments are essential. The emphasis on few-shot learning, meta-learning, and the incorporation of the independent transformer module distinguishes GPO from existing strategies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.