Decoding the Impact of Feedback Protocols on Large Language Model Alignment: Insights from Ratings vs. Rankings
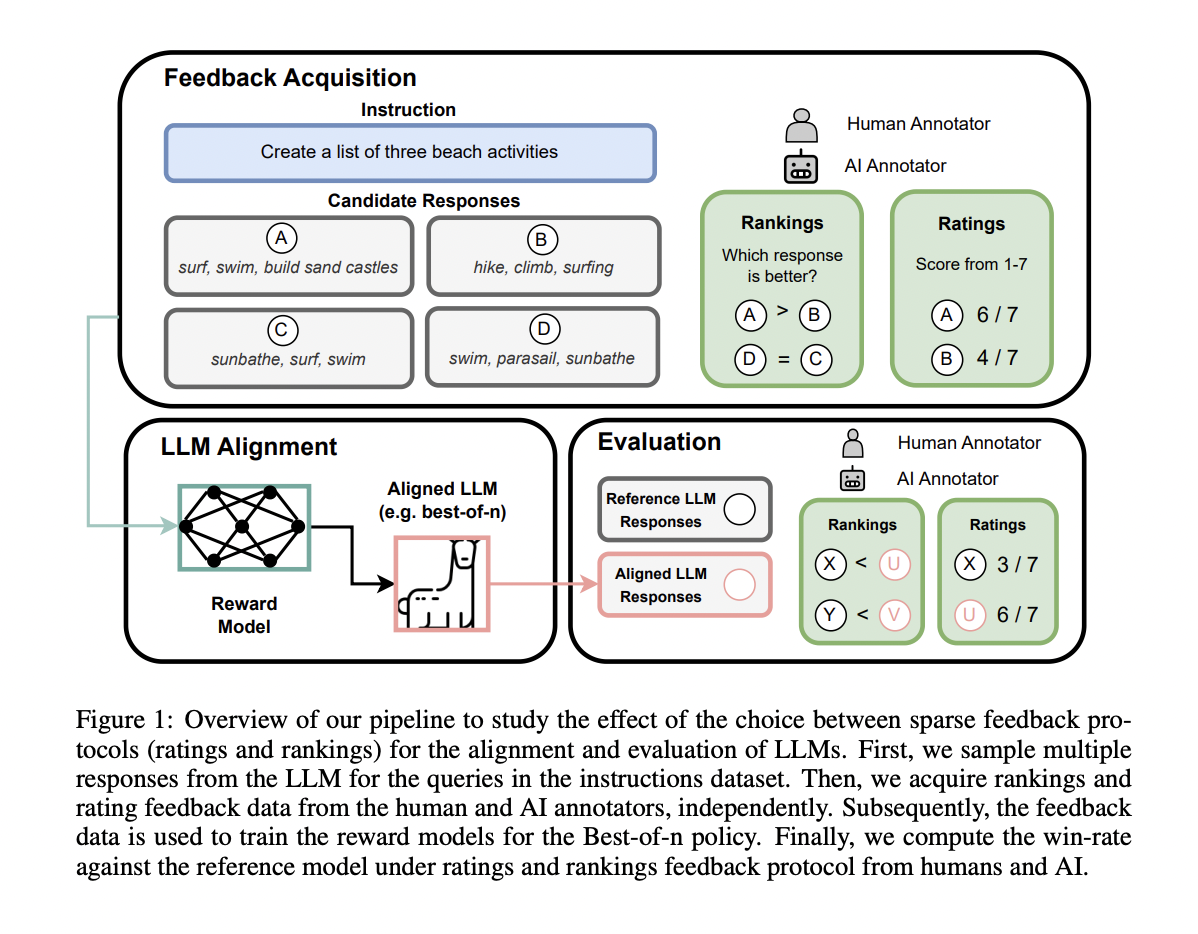
Alignment has become a pivotal concern for the development of next-generation text-based assistants, particularly in ensuring that large language models (LLMs) align with human values. This alignment aims to enhance LLM-generated content’s accuracy, coherence, and harmlessness in response to user queries. The alignment process comprises three key elements: feedback acquisition, alignment algorithms, and model evaluation. While previous efforts focused on alignment algorithms, this study delves into the nuances of feedback acquisition, specifically comparing ratings and rankings protocols, shedding light on a significant consistency challenge.
In existing literature, alignment algorithms such as PPO, DPO, and PRO have been extensively explored under specific feedback protocols and evaluation setups. Meanwhile, feedback acquisition strategies have concentrated on developing fine-grained and dense protocols, which can be challenging and costly. This study analyzes the impact of two feedback protocols, ratings and rankings, on LLM alignment. Figure 1 provides an illustration of their pipeline.

Understanding Feedback Protocols: Ratings vs. Rankings
Ratings involve assigning an absolute value to a response using a predefined scale, while rankings require annotators to select their preferred response from a pair. Ratings quantify response goodness but can be challenging for complex instructions, whereas rankings are easier for such instructions but lack quantification of the gap between responses (Listed in Table 1).
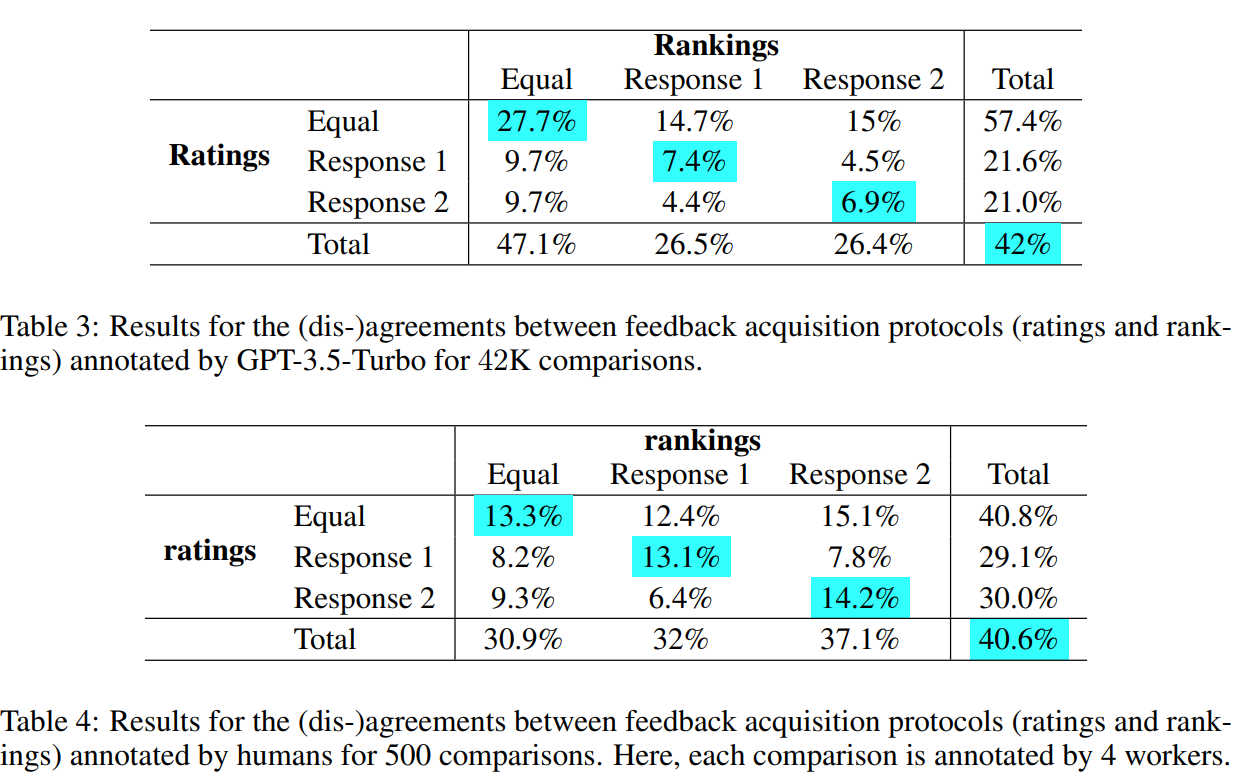
Now we will delve deeper into the initially announced feedback inconsistency problem. The authors make use of the observation that the ratings on a pair of responses for a given instruction can be compared to convert the ratings feedback data into its rankings form. This conversion of the ratings data DA to the rankings data DRA allows us a unique opportunity to study the interplay between the absolute feedback DA and relative feedback DR collected from the annotators, independently. Here, they define the term consistency as the agreement between the ratings (converted to its rankings form) and the rankings received by a pair of responses to a given instruction independent of the ratings data.
We can clearly observe consistency issues from Table 3 and 4 in both human and AI feedback data. Interestingly, the consistency score falls within a similar range of 40% − 42% for both humans and AI, suggesting that a substantial portion of the feedback data can yield contradictory preferences depending on the feedback protocol employed. This consistency problem underscores several critical points: (a) it indicates variations in the perceived quality of responses based on the choice of the feedback acquisition protocols, (b) it underscores that the alignment pipeline can vary significantly depending on whether ratings or rankings are used as sparse forms of feedback, and (c) it emphasizes the necessity of meticulous data curation when working with multiple feedback protocols for aligning LLMs.
Exploring Feedback Inconsistency:
The study delves into the identified feedback inconsistency problem, leveraging an insightful observation. By comparing ratings on a pair of responses, the authors convert rating feedback data (DA) into rankings data (DRA). This conversion offers a unique opportunity to independently study the interplay between absolute feedback (DA) and relative feedback (DR) from annotators. Consistency, defined as the agreement between converted ratings and original rankings, is assessed. Notably, Tables 3 and 4 reveal consistent issues in both human and AI feedback, with a noteworthy consistency score range of 40%−42%. This underscores variations in perceived response quality based on feedback acquisition protocols, highlighting the significant impact on the alignment pipeline and emphasizing the need for meticulous data curation when handling diverse feedback protocols in aligning LLMs.
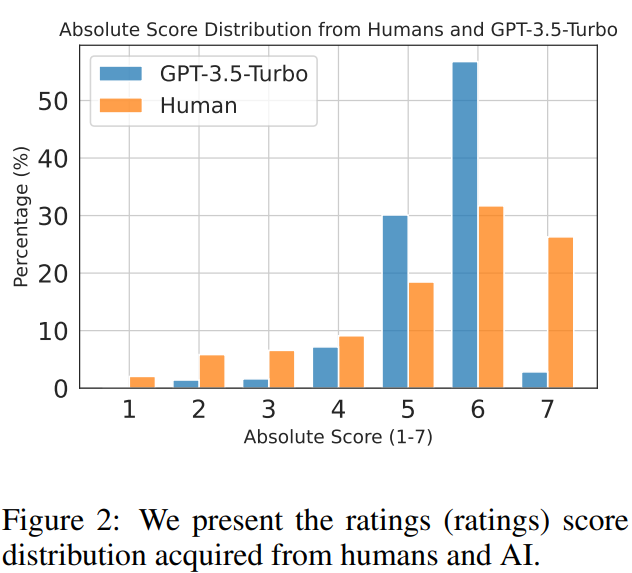
Feedback Data Acquisition
The study uses diverse instructions from sources like Dolly, Self-Instruct, and Super-NI to collect feedback. Alpaca-7B serves as the base LLM, generating candidate responses for evaluation. The authors leverage GPT-3.5-Turbo for large-scale ratings and rankings feedback data collection. They also collect feedback data under the ratings and rankings protocols.
Analysis of rating distribution (shown in Figure 2) indicates human annotators tend to give higher scores, while AI feedback is more balanced. The study also ensures feedback data is unbiased towards longer or unique responses. Agreement analysis (shown in Table 2) between human-human and human-AI feedback shows reasonable alignment rates. In summary, the agreement results indicate that GPT-3.5-Turbo can provide ratings and rankings feedback close to the human’s gold label for the responses to the instructions in our dataset.
Impact on Alignment and Model Evaluation
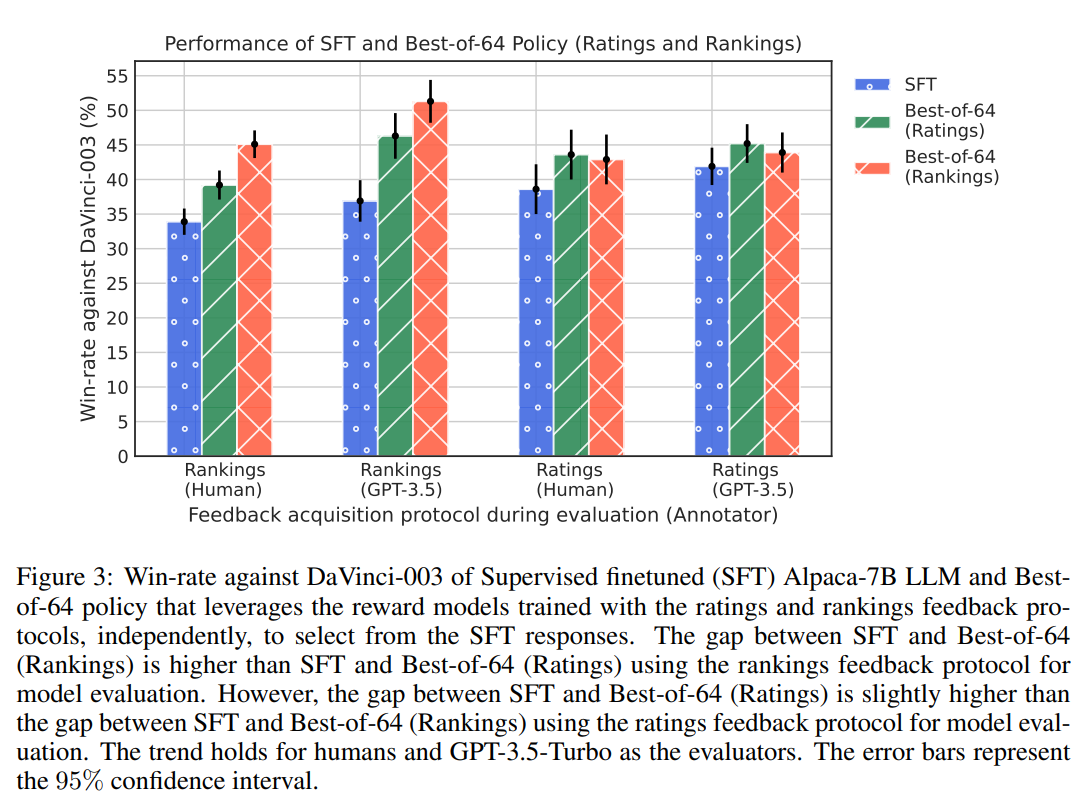
The study trains reward models based on ratings and rankings feedback and assesses Best-of-n policies. Evaluation on unseen instructions reveals Best-of-n policies, especially with rankings feedback, outperform the base LLM (SFT) and demonstrate improvement in alignment (shown in Figure 3).
A surprising revelation in the study unveils an evaluation inconsistency phenomenon, where the feedback protocol choice during evaluation seems to favor the alignment algorithm that aligns with the same feedback protocol. Notably, the gap in win rates between the Best-of-n (rankings) policy and the SFT is more pronounced (11.2%) than the gap observed between the Best-of-n (ratings) policy and SFT (5.3%) under the rankings protocol. Conversely, under the ratings protocol, the gap between the Best-of-n (ratings) policy and SFT (5%) slightly outweighs the gap between the Best-of-n (rankings) policy and SFT (4.3%). This inconsistency extends to evaluations involving GPT-3.5-Turbo, indicating a nuanced perception of policy response quality by annotators (both human and AI) under distinct feedback protocols. These findings underscore the substantial implications for practitioners, highlighting that the feedback acquisition protocol significantly influences each stage of the alignment pipeline.
In conclusion, The study underscores the paramount importance of meticulous data curation within sparse feedback protocols, shedding light on the potential repercussions of feedback protocol choices on evaluation outcomes. In the pursuit of model alignment, future research avenues may delve into the cognitive aspects of the identified consistency problem, aiming to enhance alignment strategies. Exploring richer forms of feedback beyond the scope of absolute and relative preferences is crucial for a more comprehensive understanding and improved alignment in diverse application domains. Despite its valuable insights, the study acknowledges limitations, including its focus on specific types of feedback, potential subjectivity in human annotations, and the necessity to explore the impact on different demographic groups and specialized domains. Addressing these limitations will contribute to developing more robust and universally applicable alignment methodologies in the evolving landscape of artificial intelligence.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.