This AI Paper Unveils the Potential of Speculative Decoding for Faster Large Language Model Inference: A Comprehensive Analysis
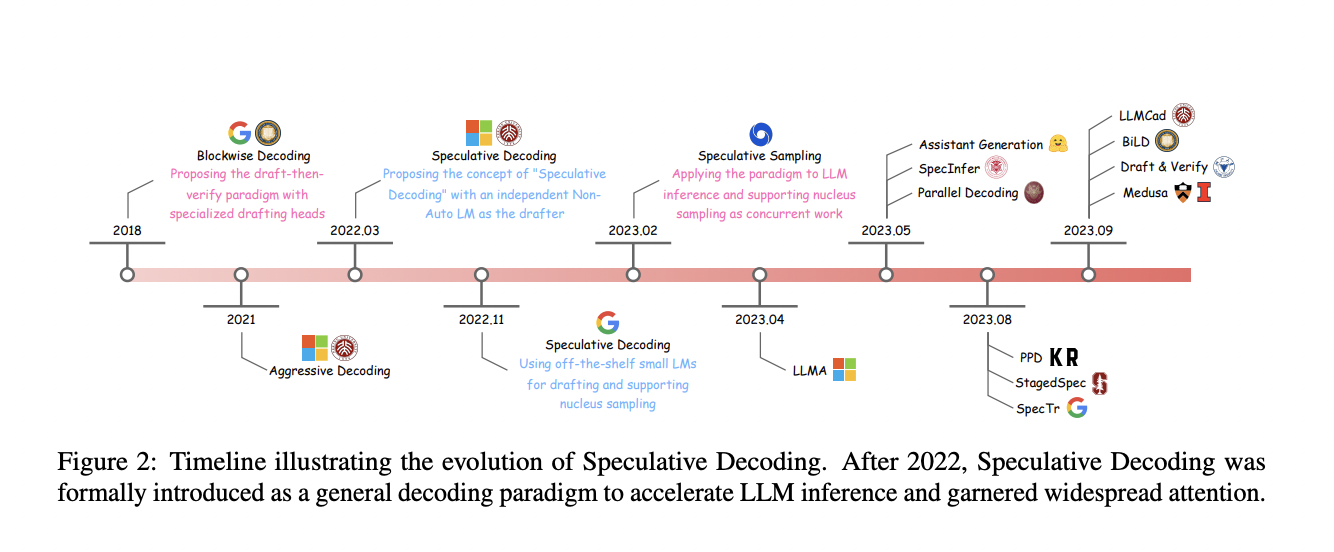
Large Language Models (LLMs) are crucial to maximizing efficiency in natural language processing. These models, central to various applications ranging from language translation to conversational AI, face a critical challenge in the form of inference latency. This latency, primarily resulting from traditional autoregressive decoding where each token is generated sequentially, increases with the complexity and size of the model, posing a significant hurdle to real-time responsiveness.
Researchers have developed an innovative approach, which is the center of this survey, known as Speculative Decoding, to address this. This method diverges from the conventional sequential token generation by allowing multiple tokens to be processed simultaneously, significantly accelerating the inference process. At its core, Speculative Decoding consists of two fundamental steps: drafting and verification. In the drafting phase, a specialized model, known as the drafter, quickly predicts multiple future tokens. These tokens are not final outputs but hypotheses of the next tokens. The drafter model operates efficiently, generating these predictions rapidly, which is crucial for the overall speed of the process.
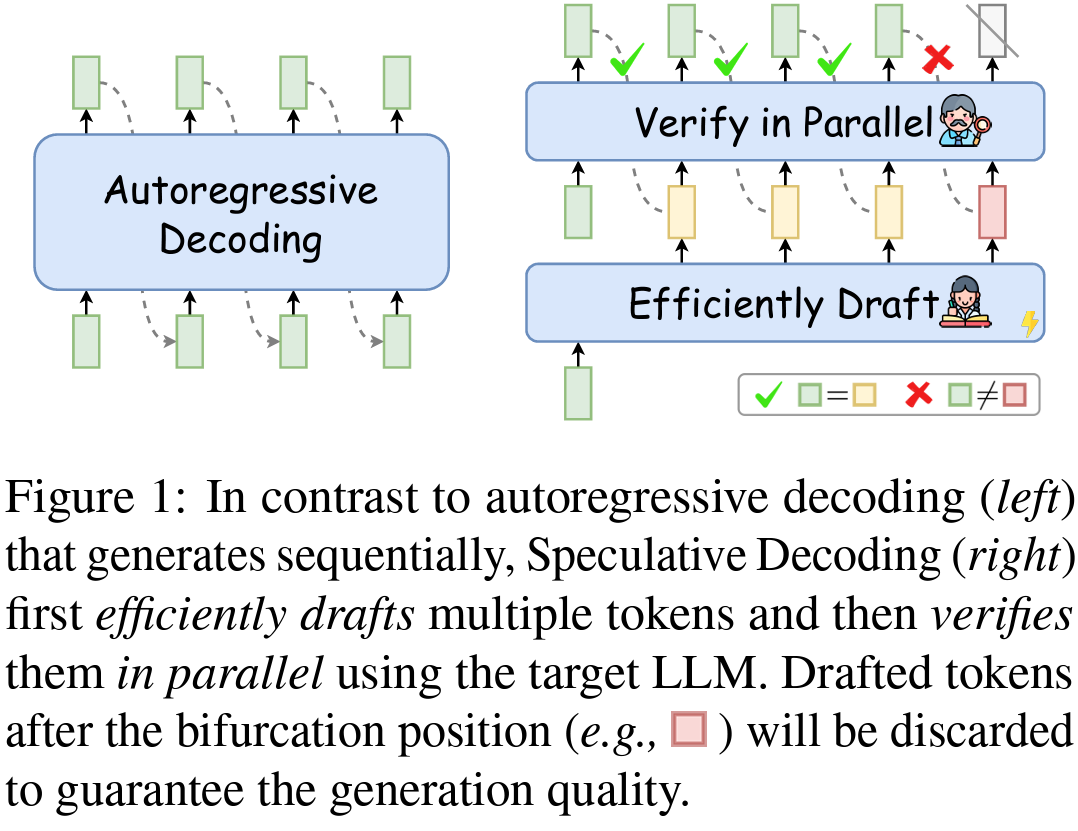
Following the drafting phase, the verification step comes into play. Here, the target LLM evaluates the drafted tokens in parallel, ensuring that the output maintains the quality and coherence expected from the model. This parallel processing approach significantly differs from the traditional method, where each token’s generation depends on the previous ones. By reducing the dependency on sequential processing, Speculative Decoding minimizes the time-consuming memory read/write operations typical in LLMs.
The performance and results of Speculative Decoding have been noteworthy. Researchers have demonstrated that this method can achieve substantial speedups in generating text outputs without compromising the quality. This efficiency gain is particularly significant given the increasing demand for real-time, interactive AI applications, where response time is crucial. For instance, in scenarios like conversational AI, where immediacy is key to user experience, the reduced latency offered by Speculative Decoding can be a game-changer.
Moreover, Speculative Decoding has broader implications for AI and machine learning. Offering a more efficient way to process large language models opens up new possibilities for their application, making them more accessible and practical for a wider range of uses. This includes real-time interaction and complex tasks like large-scale data analysis and language understanding, where processing speed is a limiting factor.
Speculative Decoding is a major advancement in LLMs. Addressing the critical challenge of inference latency enhances the practicality of these models and broadens their potential applications. This breakthrough stands as a testament to the continual innovation in AI, paving the way for more responsive and sophisticated AI-driven solutions.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.