This AI Paper from Meta and NYU Introduces Self-Rewarding Language Models that are Capable of Self-Alignment via Judging and Training on their Own Generations
Future models must receive superior feedback for effective training signals to advance the development of superhuman agents. Current methods often derive reward models from human preferences, but human performance limitations constrain this process. Relying on fixed reward models impedes the ability to enhance learning during Large Language Model (LLM) training. Overcoming these challenges is crucial for achieving breakthroughs in creating agents with capabilities that surpass human performance.
Leveraging human preference data significantly enhances the ability of LLMs to follow instructions effectively, as demonstrated by recent studies. Traditional Reinforcement Learning from Human Feedback (RLHF) involves learning a reward model from human preferences, which is then fixed and employed for LLM training using methods like Proximal Policy Optimization (PPO). An emerging alternative, Direct Preference Optimization (DPO), skips the reward model training step, directly utilizing human preferences for LLM training. However, both approaches face limitations tied to the scale and quality of available human preference data, with RLHF additionally constrained by the frozen reward model’s quality.
Meta and New York University researchers have proposed a novel approach called Self-Rewarding Language Models, aiming to overcome bottlenecks in traditional methods. Unlike frozen reward models, their process involves training a self-improving reward model that is continuously updated during LLM alignment. By integrating instruction-following and reward modeling into a single system, the model generates and evaluates its examples, refining instruction-following and reward modeling abilities.
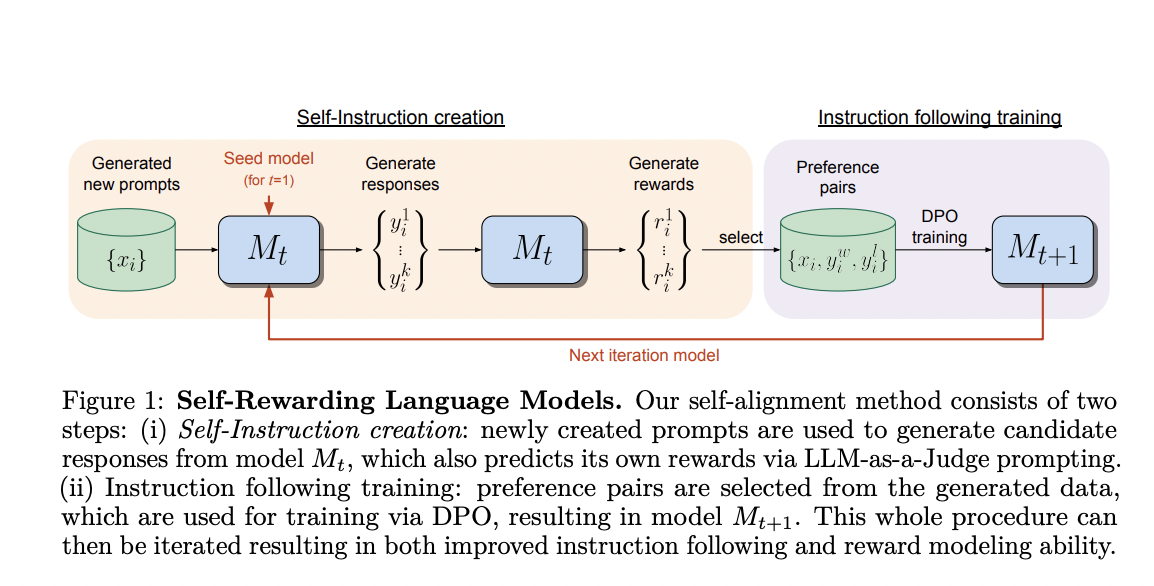
Self-Rewarding Language Models start with a pretrained language model and a limited set of human-annotated data. The model is designed to simultaneously excel in two key skills: i) instruction following and ii) self-instruction creation. The model self-evaluates generated responses through the LLM-as-a-Judge mechanism, eliminating the need for an external reward model. The iterative self-alignment process involves developing new prompts, evaluating responses, and updating the model using AI Feedback Training. This approach enhances instruction following and improves the model’s reward modeling ability over successive iterations, deviating from traditional fixed reward models.

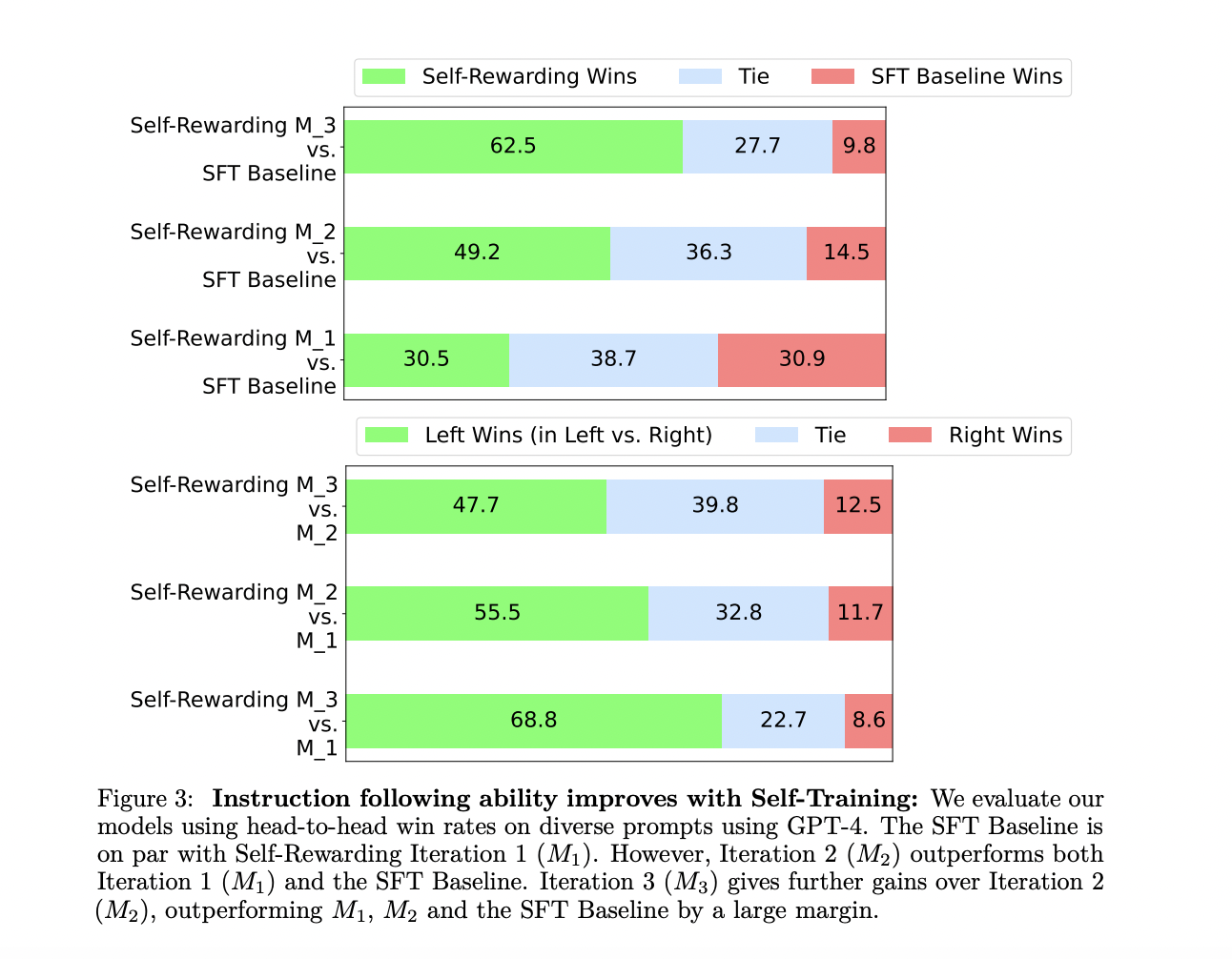
Self-Rewarding Language Models demonstrate significant improvements in instruction following and reward modeling. Iterative training iterations show substantial performance gains, outperforming prior iterations and baseline models. The self-rewarding models exhibit competitive performance on the AlpacaEval 2.0 leaderboard, surpassing existing models (Claude 2, Gemini Pro, and GPT4) with proprietary alignment data. The method’s effectiveness lies in its ability to iteratively enhance instruction following and reward modeling, providing a promising avenue for self-improvement in language models. The model’s training is demonstrated to be superior to alternative approaches that rely solely on positive examples.
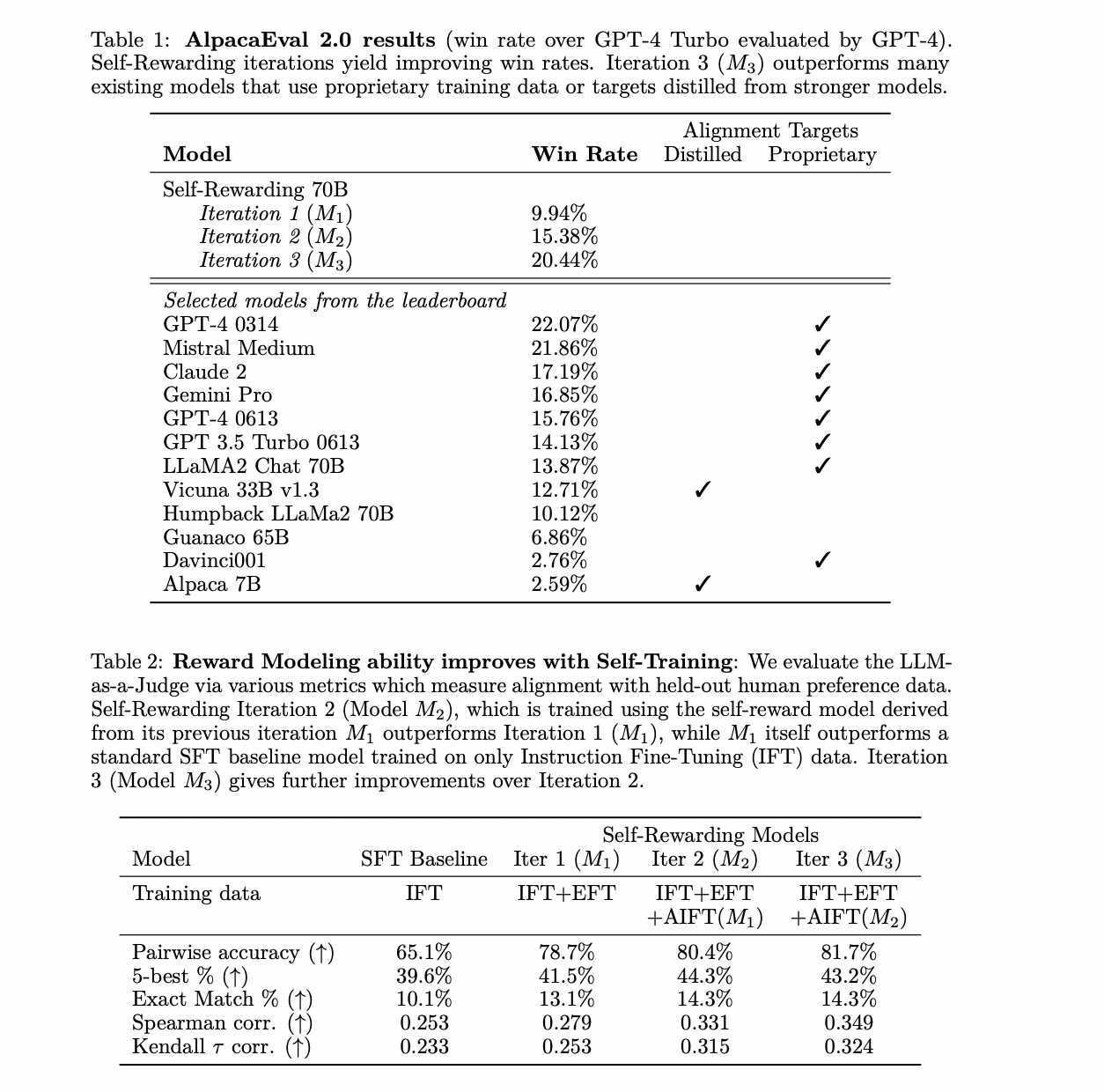
The researchers from Meta and New York University introduced self-rewarding language models capable of iterative self-alignment by generating and judging their training data. The model assigns rewards to its generations through LLM-as-a-Judge prompting and Iterative DPO, improving both instruction-following and reward-modeling abilities across iterations. While acknowledging the preliminary nature of the study, the approach presents an exciting research avenue, suggesting continual improvement beyond traditional human-preference-based reward models in language model training.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.