Meet VMamba: An Alternative to Convolutional Neural Networks CNNs and Vision Transformers for Enhanced Computational Efficiency
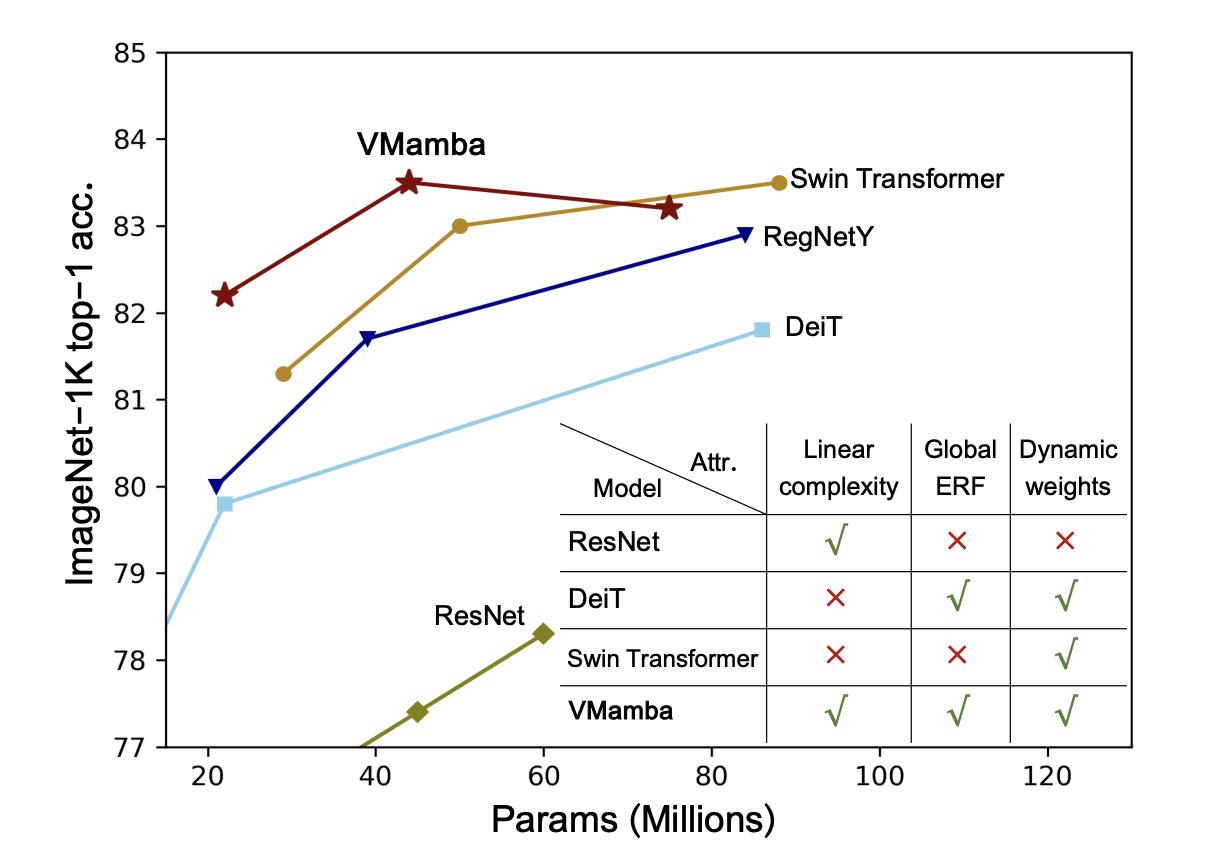
There are two major challenges in visual representation learning: the computational inefficiency of Vision Transformers (ViTs) and the limited capacity of Convolutional Neural Networks (CNNs) to capture global contextual information. ViTs suffer from quadratic computational complexity while excelling in fitting capabilities and international receptive field. On the other hand, CNNs offer scalability and linear complexity concerning image resolution but lack the dynamic weighting and global perspective of ViTs. These issues highlight a need for a model that brings together the strengths of both CNNs and ViTs without inheriting their respective computational and representational limitations.
Significant research exists in the evolution of machine visual perception. CNNs and ViTs have emerged as dominant graphical foundation models with unique strengths in processing visual information. State Space Models (SSMs) have gained prominence for their efficiency in modeling long sequences, influencing both NLP and computer vision domains.
A team of researchers at UCAS, in collaboration with Huawei Inc. and Pengcheng Lab, introduced the Visual State Space Model (VMamba), a novel architecture for visual representation learning. VMamba is inspired by the state space model and aims to address the computational inefficiencies of ViTs while retaining their advantages, such as global receptive fields and dynamic weights. The research emphasizes VMamba’s innovative approach to tackling the direction-sensitive issue in visual data processing, proposing the Cross-Scan Module (CSM) for efficient spatial traversal.
CSM is used to transform visual images into patch sequences and utilizes a 2D state space model as its core. VMamba’s selective scan mechanism and discretization process enhance its capabilities. The model’s effectiveness is validated through extensive experiments, comparing its effective receptive fields with models like ResNet50 and ConvNeXt-T and its performance in semantic segmentation on the ADE20K dataset.
Regarding the specifics of VMamba’s remarkable performance in various benchmarks, it achieved 48.5-49.7 mAP in object detection and 43.2-44.0 mIoU in instance segmentation on the COCO dataset, surpassing established models. On the ADE20K dataset, the VMamba-T model achieved 47.3 mIoU and 48.3 mIoU with multi-scale inputs in semantic segmentation, outperforming competitors like ResNet, DeiT, Swin, and ConvNeXt, as mentioned before. It also showed superior accuracy in semantic segmentation with various input resolutions. The comparative analysis highlighted VMamba’s global effective receptive fields, distinguishing it from other models with local ERFs.
The research on VMamba marks a significant leap in visual representation learning. It successfully integrates the strengths of CNNs and ViTs, offering a solution to their limitations. The novel CSM enhances VMamba’s efficiency, making it adept at handling various visual tasks with improved computational effectiveness. This model demonstrates its robustness across multiple benchmarks and suggests a new direction for future developments in graphical foundation models. VMamba’s approach to maintaining global receptive fields while ensuring linear complexity underscores its potential as a groundbreaking tool in computer vision.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.

Credit: Source link
Comments are closed.