This AI Paper from Sun Yat-sen University and Tencent AI Lab Introduces FUSELLM: Pioneering the Fusion of Diverse Large Language Models for Enhanced Capabilities
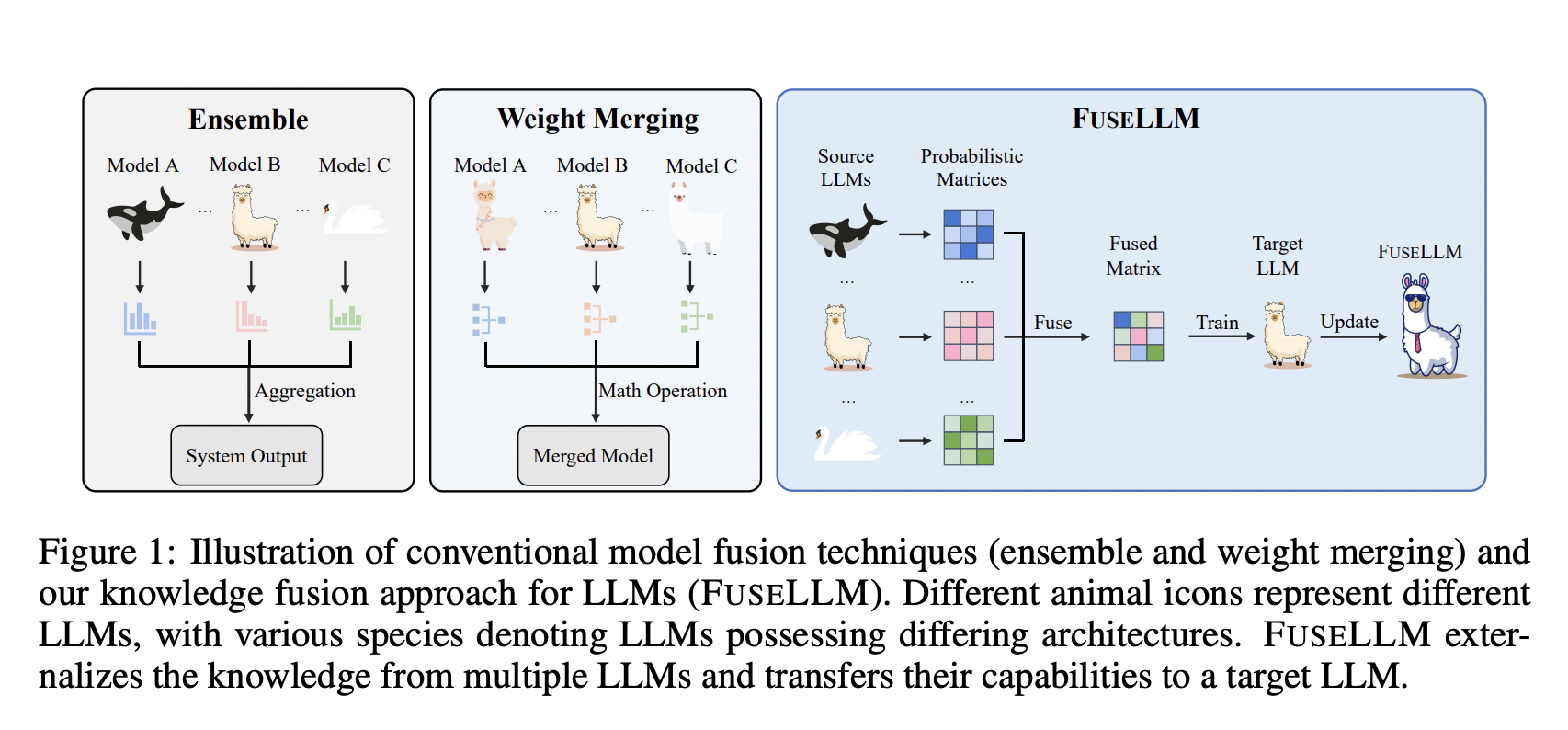
The development of large language models (LLMs) like GPT and LLaMA has marked a significant milestone. These models have become indispensable tools for various natural language processing tasks. However, creating these models from scratch involves considerable costs, immense computational resources, and substantial energy consumption. This has led to an increasing interest in developing cost-effective alternatives. One such innovative approach is the fusion of existing pre-trained LLMs into a more potent and efficient model. This strategy not only offers a reduction in resource expenditure but also harnesses the collective strengths of various models.
Merging multiple LLMs is challenging, mainly due to their diversity in architecture. Simply blending their weights is not feasible, necessitating a more nuanced approach. The goal of knowledge fusion in LLMs is to amalgamate these models to create a new, more powerful one, thereby maximizing the strengths and minimizing the costs associated with individual models. This fusion method has the potential to enhance performance across a spectrum of tasks, providing a versatile tool adaptable for various applications.
The conventional methods for integrating language models typically involve ensemble strategies and weight merging. Ensemble methods, which aggregate outputs from multiple models, face practical challenges with LLMs due to their large memory and time requirements. Weight merging, on the other hand, often fails to yield optimal results when applied to models with significant differences in their parameter spaces. These limitations necessitate a different approach to combine the capabilities of various LLMs effectively.
The researchers from Sun Yat-sen University and Tencent AI Lab introduced a groundbreaking concept – knowledge fusion for LLMs in response to the abovementioned challenges. This method leverages the generative distributions of source LLMs, externalizing their knowledge and strengths and transferring them to a target LLM through lightweight continual training. The core of this approach lies in aligning and fusing the probabilistic distributions generated by the source LLMs. This process involves developing new strategies for aligning tokenizations and exploring methods for fusing probability distributions. A significant emphasis is placed on minimizing the divergence between the probabilistic distributions of the target and source LLMs.

Implementing this methodology is intricate, necessitating a detailed alignment of tokenizations across different LLMs. This is crucial for the effective fusion of knowledge, as it ensures proper mapping of probabilistic distribution matrices. The fusion process involves evaluating the quality of different LLMs and assigning varying levels of importance to their respective distribution matrices based on their prediction quality. This nuanced approach allows the fused model to take advantage of the collective knowledge while preserving the unique strengths of each source LLM.
The performance of FuseLLM was rigorously tested using three popular open-source LLMs with distinct architectures: Llama-2, MPT, and OpenLLaMA. The evaluation encompassed various benchmarks, including reasoning, commonsense, and code generation tasks. The results were remarkable, with the fused model outperforming each source LLM and the baseline in most tasks. The study demonstrated substantial improvements in various capabilities, highlighting the effectiveness of FuseLLM in integrating the collective strengths of individual LLMs.
The research offers several key insights:
- FuseLLM presents an effective method for LLM fusion, surpassing traditional ensemble and weight-merging techniques.
- The fused model showcases superior capabilities in reasoning, commonsense, and code generation tasks.
- The approach opens up new possibilities for developing powerful and efficient LLMs by leveraging existing models.
In conclusion, studying knowledge fusion in LLMs introduces a pioneering approach to developing language models. By combining the capabilities of diverse LLMs, this method offers a fine solution to the challenges of resource-intensive model training. The findings from this research demonstrate the effectiveness of the FuseLLM approach and pave the way for future advancements in natural language processing.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.