This AI Report from the Illinois Institute of Technology Presents Opportunities and Challenges of Combating Misinformation with LLMs
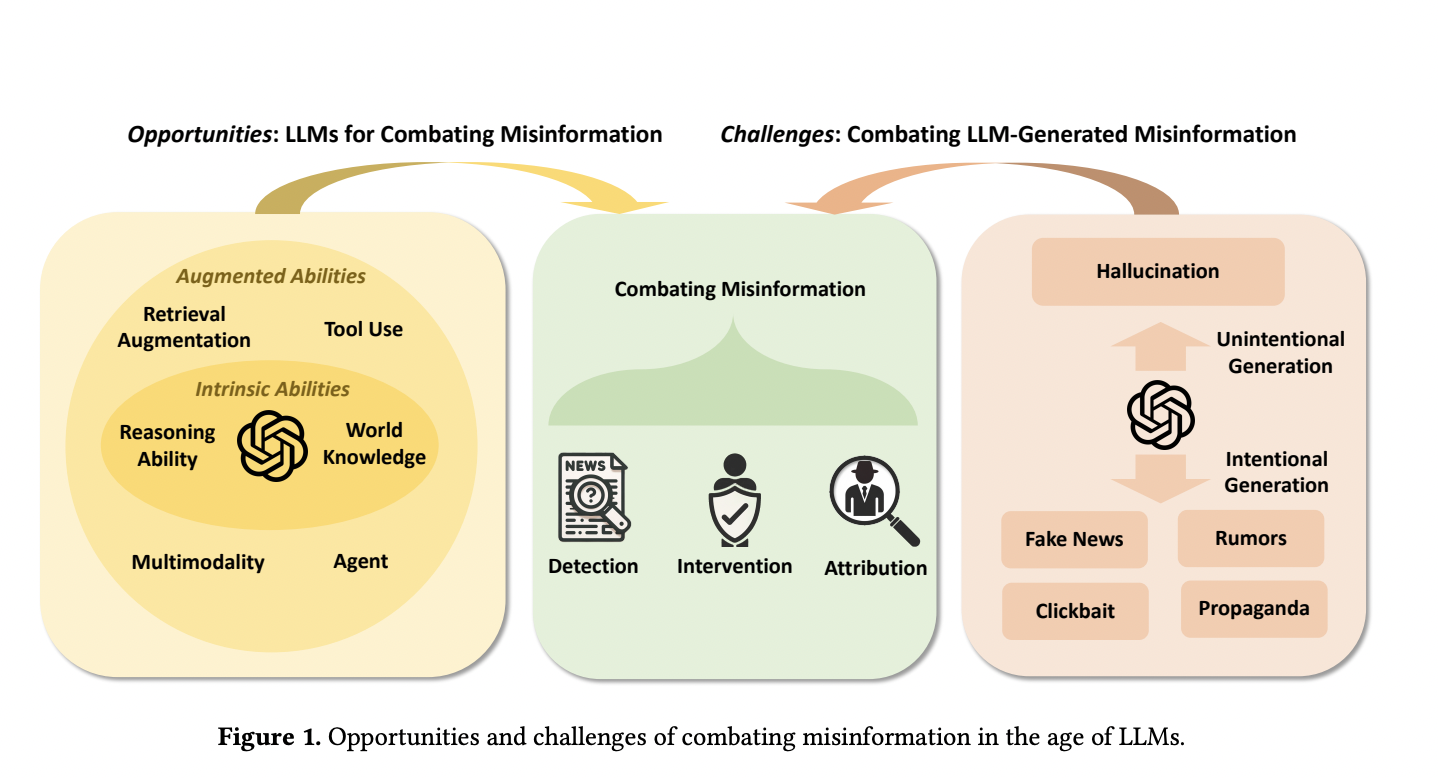
The spread of false information is an issue that has persisted in the modern digital era. The lowering of content creation and sharing barriers brought about by the explosion of social media and online news outlets has had the unintended consequence of speeding up the creation and distribution of different forms of disinformation (such as fake news and rumors) and amplifying their impact on a global scale. The public’s trust in credible sources and the truth might be jeopardized due to the widespread dissemination of false information. It is crucial to fight disinformation to protect information ecosystems and maintain public trust. This is particularly true in high-stakes industries like healthcare and finance.
LLMs have brought a paradigm shift in the fight against misinformation (e.g., ChatGPT, GPT-4). There are new opportunities and obstacles brought about by LLMs, making them a double-edged sword in the battle against disinformation. LLMs could radically alter the existing misinformation detection, intervention, and attribution paradigms due to their extensive knowledge of the world and superior reasoning ability. LLMs can become increasingly more powerful and even act as their agents by adding external information, tools, and multimodal data.
However, studies have also shown that LLMs can be readily programmed to produce false information, intentionally or unintentionally, due to their ability to mimic human speech, which may include hallucinations, and their ability to follow human commands. According to recent research, much more worrying is that LLM-generated misinformation may have more misleading styles and possibly do more damage than human-written misinformation with the same semantics. This makes it harder for humans and detectors to identify.
A new study by researchers at the Illinois Institute of Technology presents a thorough and organized analysis of the possibilities and threats associated with fighting disinformation in the era of LLMs. They hope their work encourages using LLMs to fight disinformation and rally stakeholders from diverse backgrounds to work together to battle LLM-generated misinformation.
Previous paradigms of misinformation detection, intervention, and attribution have begun to be revolutionized by the emergence of LLMs in countering disinformation. The advantages that prove their adoption are as follows:
- To begin with, LLMs include a great deal of global knowledge. Previous benchmarks and related surveys show that LLMs can store much more knowledge than a single knowledge graph due to their billions of parameters and pre-training on large corpora (e.g., Wikipedia). Therefore, LLMs may be able to identify deceptive writings that contain factual inaccuracies.
- LLMs are good reasoners, particularly when it comes to zero-shot problems. They excel in symbolic reasoning, commonsense reasoning, and mathematical reasoning. They can also break down problems into their component parts and reason using rationales in response to statements like “Let’s think step by step. ” As a result, LLMs may be able to use their inherent knowledge to reason about the legitimacy of publications.
- LLMs can function as independent agents by incorporating external information, resources, tools, and multimodal data. Hallucinations, in which the LLM-generated texts contain information that is not real, are one of the main drawbacks of LLMs. The lack of access to current information and potential inadequacy of understanding in specific sectors like healthcare among LLMs is a major contributor to hallucinations. New studies have demonstrated that using external knowledge or resources (like Google) to get current information can help lessen the impact of LLM hallucinations.
The paper highlights that the fight against disinformation could benefit from Large Language Models’ (LLMs) two primary strategies: intervention and attribution.
Dispelling False Claims and Preventing Their Spread
The intervention involves influencing users directly rather than just fact-checking. Debunking false information after it has already been spread is one strategy known as post-hoc intervention. There is a possibility of the backfiring effect, in which debunking could potentially reinforce belief in the false information, even while LLMs might assist in creating more convincing debunking messages. In contrast, pre-emptive intervention inoculates individuals against misinformation before they encounter it by using LLMs to craft convincing “anti-misinformation” messages, such as pro-vaccination campaigns. Both approaches must take ethical considerations and the hazards of manipulation into account.
Finding the Original Author: Attribution
Another important part of the fight is attribution, which is finding out where false information came from. Finding authors has traditionally depended on examining writing styles. Despite the lack of an existing LLM-based attribution solution, the remarkable power of LLMs to alter writing styles implies that they could be a game-changer in this domain.
Human-LLM Partnership: An Effective Group
The team suggests that combining human knowledge with LLMs’ capabilities can create an effective tool. By guiding LLM development, humans may ensure that ethical considerations are prioritized and bias is avoided. Then, LLMs can back up human decision-making and fact-checking with a plethora of data and analysis. The study urges additional research in this area to make the most of human and LLM strengths in countering disinformation.
Misinformation Spread by LLM: A Double-Sided Sword
Even though LLMs provide effective resources for fighting misinformation, they also bring new difficulties. LLMs have the potential to generate individualized misinformation that is both very convincing and difficult to detect and disprove. This presents dangers in domains where manipulation, such as politics and the financial sector, may have far-reaching effects. The study lays out many solutions:
1. Improving LLM Safety:
- Data Selection and Bias Mitigation: Training LLMs on carefully curated data sets that are diverse, high-quality, and free from bias can help reduce the spread of misinformation. Techniques like data augmentation and counterfactual training can also help address biases and misinformation present in existing data.
- Algorithmic Transparency and Explainability: Developing methods to understand how LLMs arrive at their outputs can help identify and address potential biases, hallucinations, and logical inconsistencies. This could involve creating interpretable models or developing tools explaining the generated text’s reasoning.
- Human Oversight and Control Mechanisms: Implementing human oversight mechanisms, such as fact-checking and content moderation, can help prevent the spread of false information generated by LLMs. Additionally, developing user interfaces that allow users to control the outputs of LLMs, for example, by specifying desired levels of factuality or objectivity, can empower users to engage with LLMs more critically.
2. Reducing Hallucinations:
- Fact-Checking and Grounding in Real-World Data: Integrating fact-checking algorithms and knowledge bases into the LLM generation process can help ensure that the outputs are consistent with real-world facts and evidence. This could involve verifying factual claims against external databases or incorporating factual constraints into the model’s training objectives.
- Uncertainty Awareness and Confidence Scoring: Training LLMs to be more aware of their limitations and uncertainties can help mitigate the spread of misinformation. This could involve developing techniques for LLMs to estimate the confidence they have in their outputs and flag potentially unreliable information.
- Prompt Engineering and Fine-Tuning: Carefully crafting prompts and fine-tuning LLMs on specific tasks can help steer their outputs toward desired goals and reduce the likelihood of hallucinations. This approach requires understanding the specific context and desired outcomes of LLM usage and designing prompts that guide the model toward generating accurate and relevant information.
The team highlights that there is no silver bullet for addressing LLM safety and hallucinations. Implementing a combination of these approaches, alongside continuous research and development, is crucial for ensuring that LLMs are used responsibly and ethically in the fight against misinformation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.