DeepSeek-AI Introduce the DeepSeek-Coder Series: A Range of Open-Source Code Models from 1.3B to 33B and Trained from Scratch on 2T Tokens
In the dynamic field of software development, integrating large language models (LLMs) has initiated a new chapter, especially in code intelligence. These sophisticated models have been pivotal in automating various aspects of programming, from identifying bugs to generating code, revolutionizing how coding tasks are approached and executed. The impact of these models is vast, offering to increase productivity and decrease the likelihood of errors common in manual coding processes.
However, a significant challenge in this area has been the disparity in capabilities between open-source, proprietary, and closed-source code models. While the latter have shown impressive performance, their restricted accessibility hinders broad-based research and application, leading to a notable performance gap that needs addressing. This gap has been a barrier to the democratization of advanced coding tools, limiting the potential for widespread innovation and application in various coding scenarios.
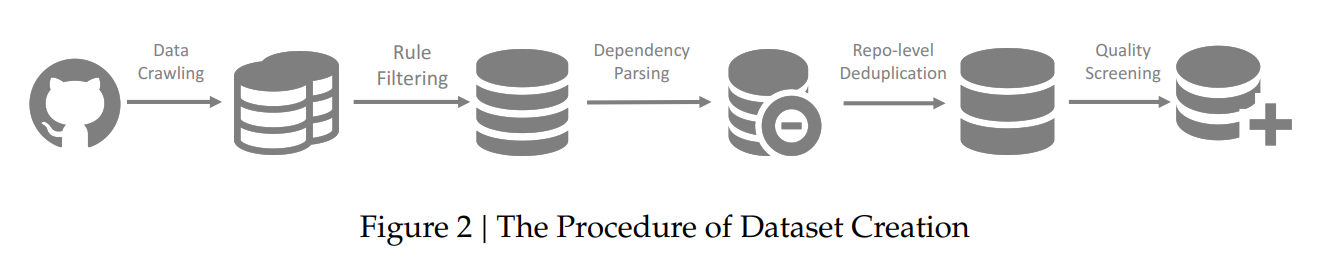
Code models have been trained primarily at the file level, not accounting for the complex interdependencies between various files in a programming project. This has often resulted in a gap in their practical application, as real-world coding projects typically involve intricate relationships between numerous files. Acknowledging this limitation is crucial for developing models that are not only theoretically proficient but also practically applicable.
The research team from DeepSeek-AI and Peking University developed the DeepSeek-Coder series. This pioneering range of open-source code models varies from 1.3B to 33B parameters. It is uniquely trained from the ground up on an extensive corpus covering 87 programming languages. This development represents a significant stride in bridging the existing gap and enhancing the functionality of open-source models in code intelligence.
The methodology adopted by DeepSeek-Coder is particularly noteworthy. These models employ a novel ‘fill-in-the-middle’ training approach and an extended context window capability. This approach allows the models to handle more intricate and longer code sequences, significantly enhancing their code completion capabilities. It also makes them highly versatile, enabling them to be more effectively applied in complex coding scenarios that involve multiple files and extended contexts. This methodological innovation is a key differentiator, setting DeepSeek-Coder apart from traditional models.

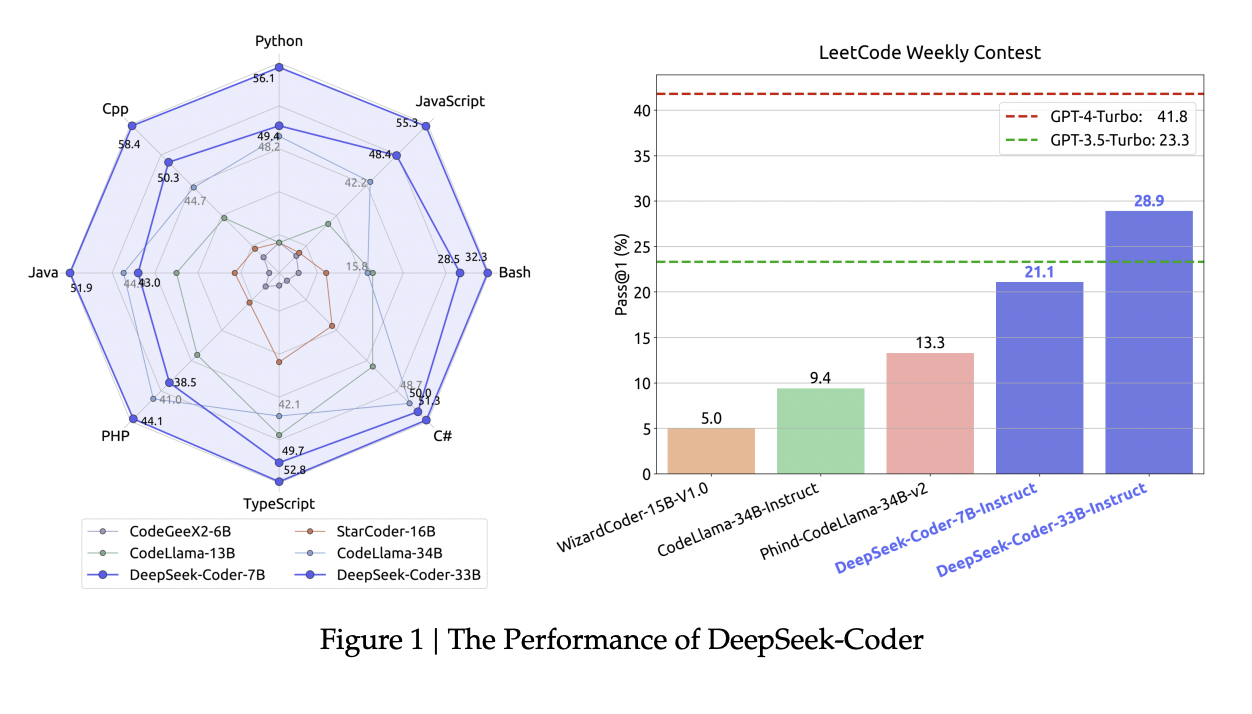
The performance of the DeepSeek-Coder models is a standout feature, demonstrating their superiority in the open-source domain. In particular, the DeepSeek-Coder-Base 33B model consistently outperforms other open-source models across various benchmarks. Furthermore, the DeepSeek-Coder-Instruct 33B variant shows remarkable results in code-related tasks, surpassing some of the leading closed-source models, including OpenAI’s GPT-3.5 Turbo. These results are a testament to the efficacy of the innovative training and design approach of the DeepSeek-Coder series.
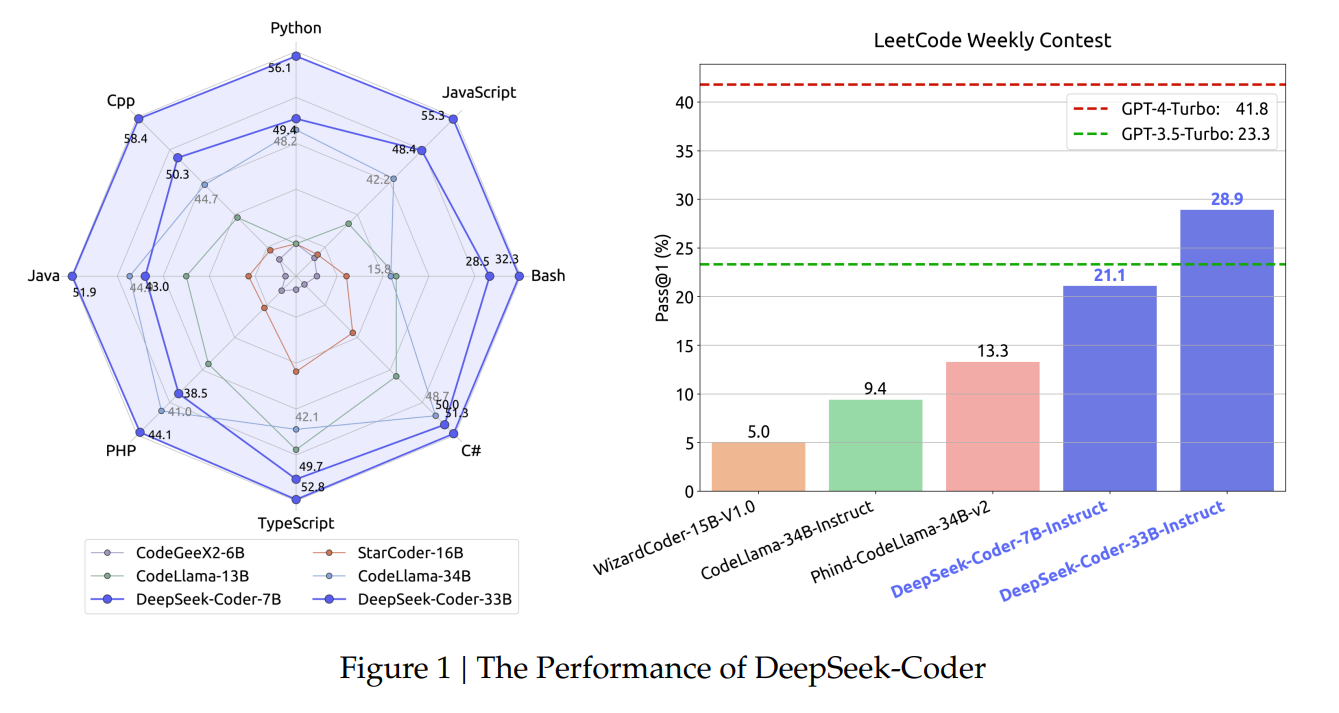
In conclusion, the DeepSeek-Coder series marks a pivotal advancement in code intelligence. By effectively addressing the gap between open-source and proprietary code models, DeepSeek-Coder sets a new benchmark in the performance of code models. Its ability to understand and process complex code sequences and its proficiency in various programming languages underscores its potential to revolutionize code generation and comprehension. This development is a leap towards more accessible, efficient, and advanced coding tools, paving the way for broader innovation and application in software development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.