Researchers from ETH Zurich and Microsoft Introduce SliceGPT for Efficient Compression of Large Language Models through Sparsification
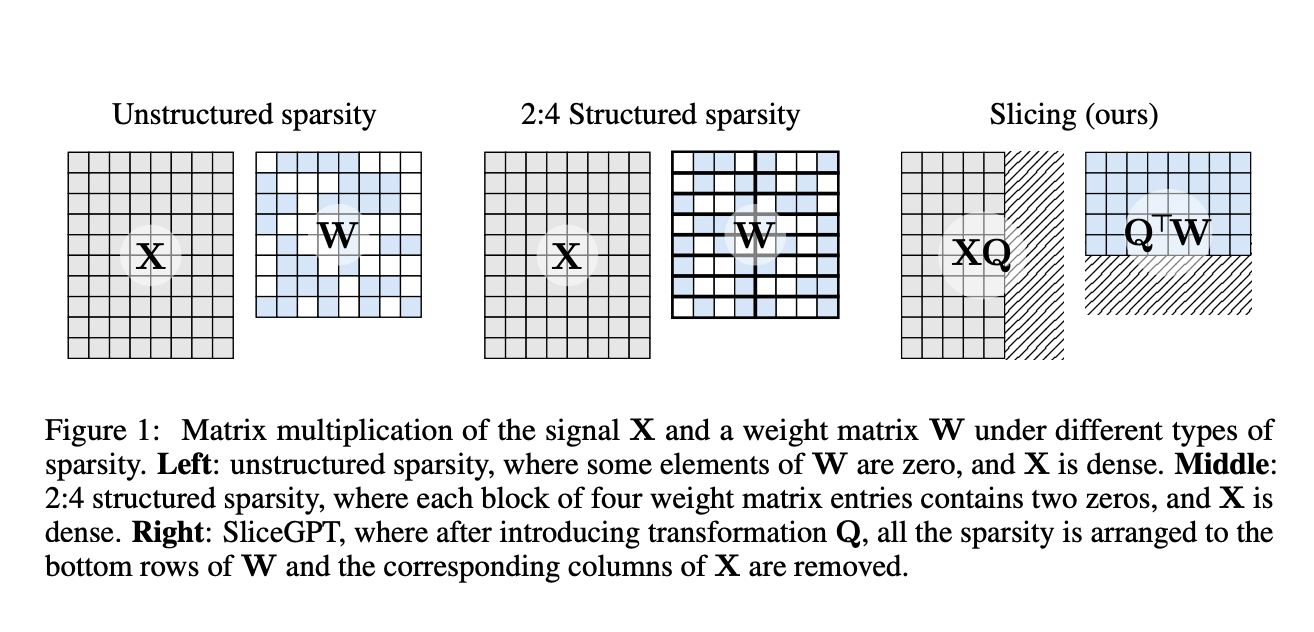
Large language models (LLMs) like GPT-4 require substantial computational power and memory, posing challenges for their efficient deployment. While sparsification methods have been developed to mitigate these resource demands, they often introduce new complexities. For example, these techniques may require extra data structures to support the sparse representations, complicating the system architecture. The potential speedups from sparsification are only partially realized due to limitations in current hardware architectures, which are typically optimized for dense computations.
LLM compression methods include sparsification, low-rank approximation, and structured pruning. Methods like Optimal Brain Surgeon (OBS) are impractical due to high computational demands. GPTQ and SparseGPT focus on quantization and pruning. Low-rank approximation simplifies weight matrices, while other methods propose eliminating specific rows and columns. Techniques like ThiNet and LLM-pruner use linear operations and fine-tuning.
Researchers at ETH Zurich and Microsoft Research have proposed SliceGPT. This post-training sparsification scheme reduces the embedding dimension of the network by replacing each weight matrix with a smaller dense matrix. The sliced models of SliceGPT run on fewer GPUs and achieve faster inference without additional code optimization. The method utilizes computational invariance in transformer networks.
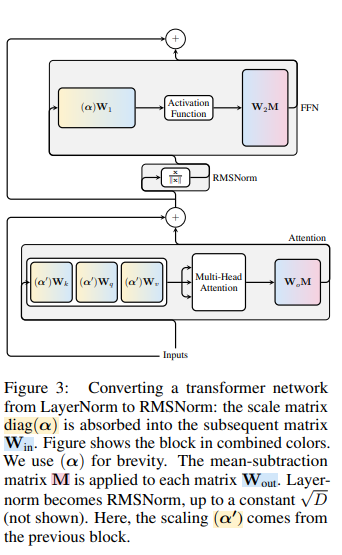
The research approach focuses on RMSNorm operations, which maintain transformation invariance, allowing for the application of orthogonal transformations without altering the model’s function. Networks with LayerNorm can be converted to RMSNorm by integrating LayerNorm’s linear components into adjacent blocks. Principal Component Analysis (PCA) is pivotal in this process and is used to identify and project signals onto their principal components at each layer. Minor components are then sliced off, reducing the network size without compromising performance. This technique, validated through experiments, has been shown to outperform SparseGPT, offering significant speedups across various models and tasks.
SliceGPT demonstrates a breakthrough in compressing LLMs like LLAMA-2 70B, OPT 66B, and Phi-2. It efficiently cuts down up to 25% of model parameters, including embeddings, while preserving high task performance. This increases efficiency, enabling the models to run on fewer GPUs and achieve faster inference times without additional code optimization. On consumer and high-end GPUs, SliceGPT significantly reduces compute requirements during inference to 64% and 66%, respectively. The research highlights that OPT models are more compressible than LLAMA-2 models, with larger models showing less accuracy reduction. SliceGPT is a promising approach for reducing LLMs’ resource demands without compromising effectiveness.
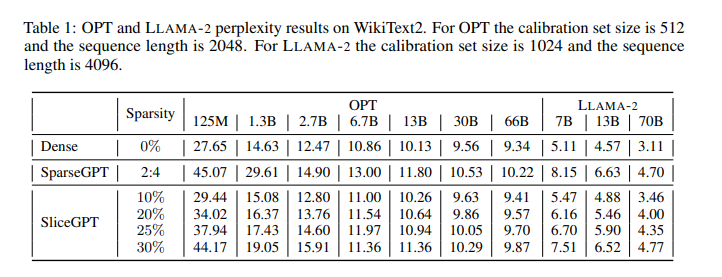
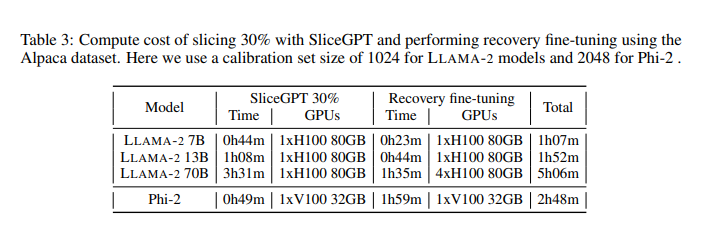
SliceGPT allows for structured pruning of LLMs, reducing the cost of inference and maintaining better performance than SparseGPT. Opportunities for improvement include exploring combined methods with SparseGPT, improving Q computation, and using complementary methods like quantization and structural pruning. Observing computational invariance in SliceGPT can contribute to future research in improving the efficiency of deep learning models and inspire new theoretical insights.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.