Meet DiffMoog: A Differentiable Modular Synthesizer with a Comprehensive Set of Modules Typically Found in Commercial Instruments
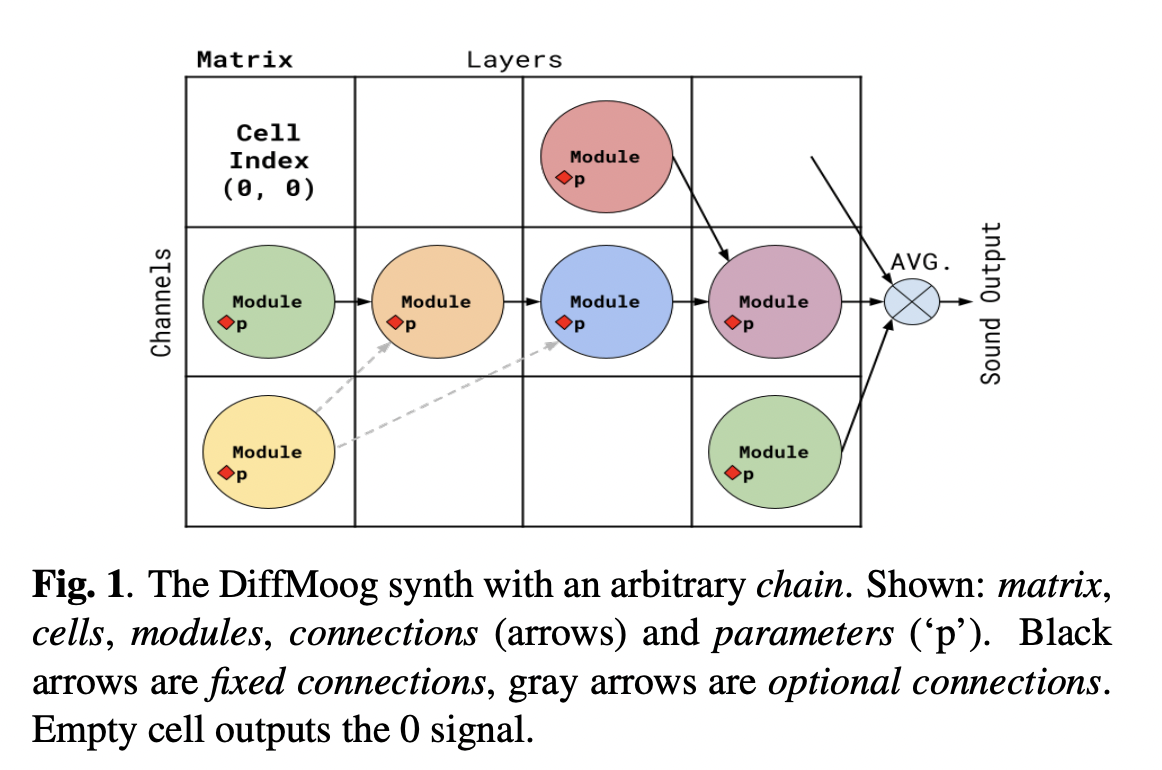
Synthesizers, electronic instruments producing diverse sounds, are integral to music genres. Traditional sound design involves intricate parameter adjustments, demanding expertise. Neural networks aid by replicating input sounds, initially optimizing synthesizer parameters. Recent advances focus on optimizing sound directly for high-fidelity reproduction, requiring unsupervised learning for out-of-domain sounds. Differentiable synthesizers enable automatic differentiation crucial for backpropagation, but existing models could be more complex or lack modularity and essential sound modules. Practical applications require bridging this gap.
Researchers from Tel-Aviv University and The Open University, Israel, have unveiled DiffMoog, a differentiable modular synthesizer for AI-guided sound synthesis. DiffMoog integrates into neural networks, allowing automated sound matching by replicating audio inputs. Its modular architecture includes essential commercial instrument modules, facilitating custom signal chain creation. The open-source platform combines DiffMoog with an end-to-end system, introducing a unique signal-chain loss for optimization. Key contributions encompass an accessible gateway for AI sound synthesis research, a novel loss function, optimization insights, and showcasing the Wasserstein loss’s efficacy in frequency estimations. Challenges in frequency estimation persist, deviating from previous approaches emphasizing DiffMoog’s innovation.
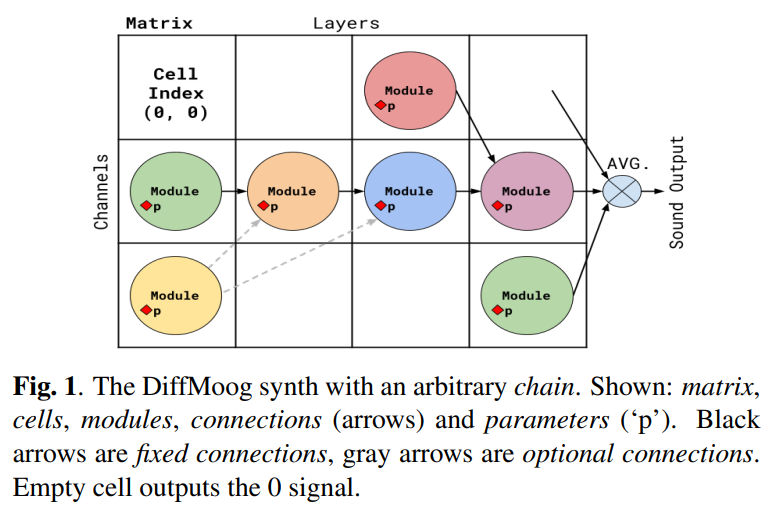
Works in sound matching have utilized supervised datasets of sound samples and their parameters derived from non-differentiable synthesizers, training neural networks to predict sound parameters. Differentiable digital signal processing (DDSP) integrates signal processing modules as differential operations into neural networks, allowing backpropagation. It uses additive synthesis based on the Fourier theorem to construct complex sounds. Differentiable methods have been employed in audio effects applications, including a differentiable mixing console for automatic multitrack mixing and automating DJ transitions with differentiable audio effects. Other works have explored the power of generative adversarial networks (GANs) and diffusion models in sound synthesis. DiffMoog is the first and most comprehensive modular differentiable synthesizer, integrating both FM and subtractive synthesis techniques.
DiffMoog is a differentiable modular synthesizer that integrates a comprehensive set of modules typically found in commercial instruments, including modulation capabilities, low-frequency oscillators, filters, and envelope shapers. The synthesizer is designed to be differentiable, allowing it to be integrated into neural networks for automated sound matching. The study mentions an open-source platform that combines DiffMoog with an end-to-end sound-matching framework, utilizing a signal-chain loss and an encoder network. The researchers also report on their experiments with different synthesizer chains, loss configurations, and neural architectures, exploring the challenges and findings in sound matching using differentiable synthesis.

DiffMoog is a differentiable modular synthesizer that enables automated sound matching and replication of given audio inputs. The researchers have developed an open-source platform that combines DiffMoog with an end-to-end sound-matching framework, utilizing a signal-chain loss and an encoder network. The study provides insights and lessons learned towards sound matching using differentiable synthesis. DiffMoog, with its comprehensive set of modules and differentiable nature, stands as a premier asset for expediting research in audio synthesis and machine learning. The study also reports on the challenges faced in optimizing DiffMoog and demonstrates the excellence of the Wasserstein loss in frequency estimations.
In conclusion, The research suggests that differentiable synthesizers offer potential in sound matching when optimized with spectral loss. However, accurately replicating common sounds poses a significant challenge. Using the Wasserstein distance may address gradient issues in frequency estimation via spectral loss. The platform mentioned in this study is expected to stimulate additional research in this intriguing field. The researchers recommend investigating improved audio loss functions, optimization techniques, and alternative neural network structures to overcome the existing challenges and enhance precision in emulating typical sounds.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.