This AI Paper from China Introduces SegMamba: A Novel 3D Medical Image Segmentation Mamba Model Designed to Effectively Capture Long-Range Dependencies within Whole Volume Features at Every Scale
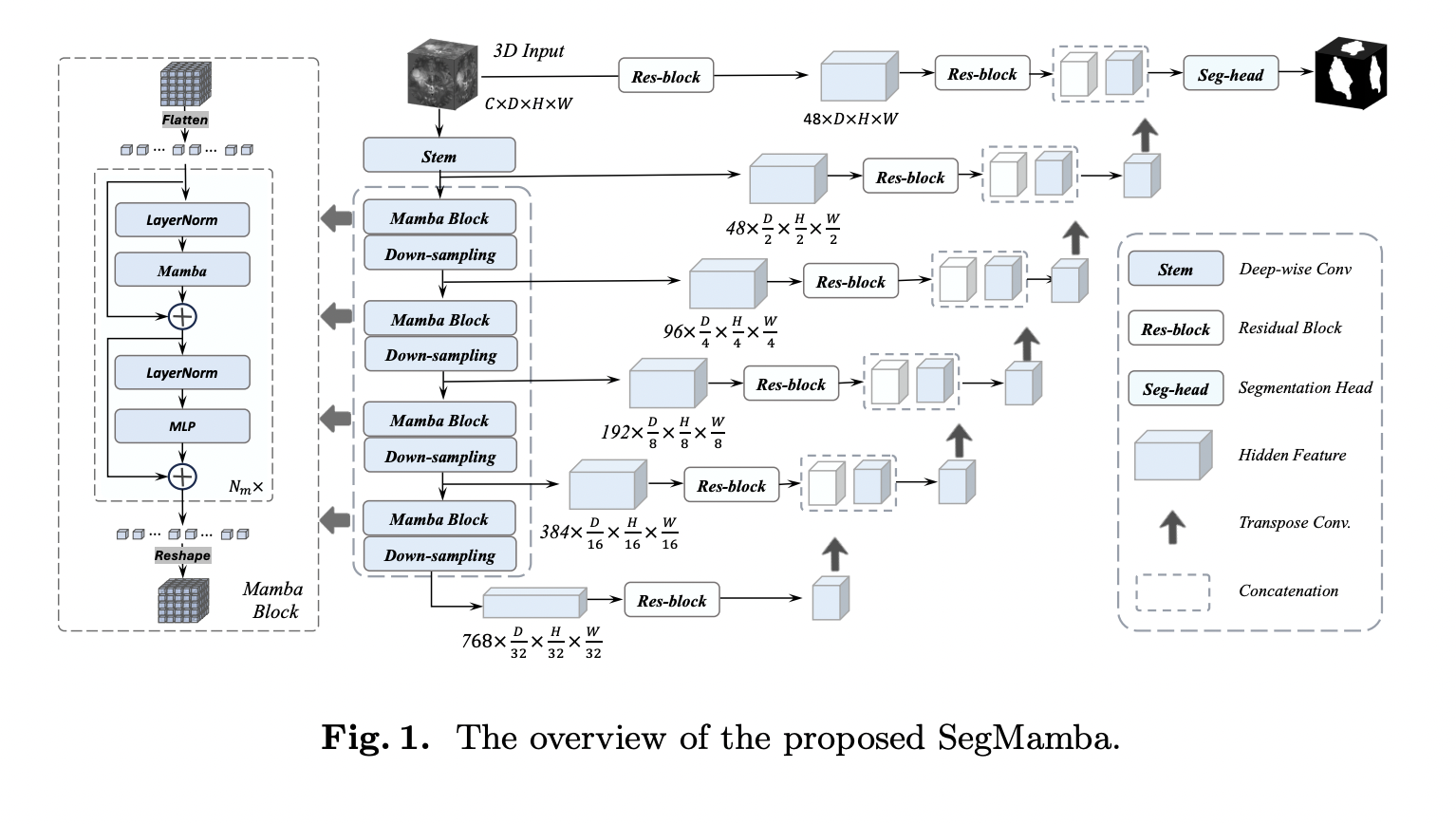
Enhancing the receptive field of models is crucial for effective 3D medical image segmentation. Traditional convolutional neural networks (CNNs) often struggle to capture global information from high-resolution 3D medical images. One proposed solution is the utilization of depth-wise convolution with larger kernel sizes to capture a wider range of features. However, CNN-based approaches need help in capturing relationships across distant pixels.
Recently, there has been an extensive exploration of transformer architectures, leveraging self-attention mechanisms to extract global information for 3D medical image segmentation like TransBTS, which combines 3D-CNN with transformers to capture both local spatial features and global dependencies in high-level features; UNETR, which adopts the Vision Transformer (ViT) as its encoder to learn contextual information. However, transformer-based methods often face computational challenges due to the high resolution of 3D medical images, leading to reduced speed performance.
To address the issues of long sequence modeling, researchers have previously introduced Mamba, a state space model (SSM), to model long-range dependencies efficiently through a selection mechanism and a hardware-aware algorithm. Various studies have applied Mamba in computer vision (CV) tasks. For instance, U-Mamba integrates the Mamba layer to improve medical image segmentation.
At the same time, Vision Mamba proposes the Vim block, incorporating bidirectional SSM for global visual context modeling and position embeddings for location-aware understanding. VMamba also introduces a CSM module to bridge the gap between 1-D array scanning and 2-D plain traversing. However, traditional transformer blocks face challenges in handling large-size features, necessitating the modeling of correlations within high-dimensional features for enhanced visual understanding.
Motivated by this, researchers at the Beijing Academy of Artificial Intelligence introduced SegMamba, a novel architecture combining the U-shape structure with Mamba to model whole-volume global features at various scales. They utilize Mamba specifically for 3D medical image segmentation. SegMamba demonstrates remarkable capabilities in modeling long-range dependencies within volumetric data while maintaining outstanding inference efficiency compared to traditional CNN-based and transformer-based methods.
The researchers conducted Extensive experiments on the BraTS2023 dataset to affirm SegMamba’s effectiveness and efficiency in 3D medical image segmentation tasks. Unlike Transformer-based methods, SegMamba leverages the principles of state space modeling to excel in modeling whole-volume features while maintaining superior processing speed. Even with volume features at a resolution of 64 × 64 × 64 (equivalent to a sequential length of about 260k), SegMamba showcases remarkable efficiency.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.