Enhancing the Accuracy of Large Language Models with Corrective Retrieval Augmented Generation (CRAG)
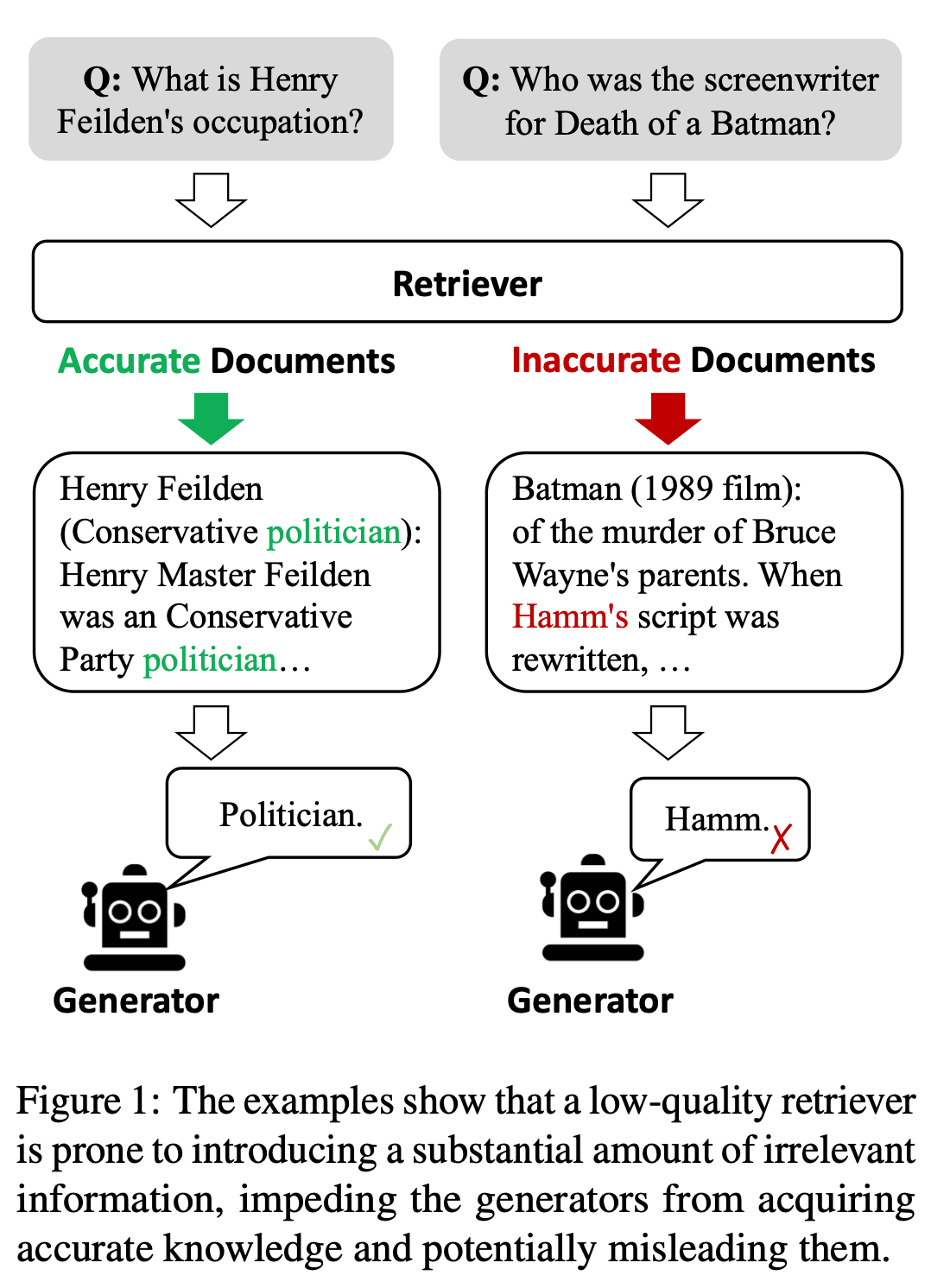
In natural language processing, the quest for precision in language models has led to innovative approaches that mitigate the inherent inaccuracies these models may present. A significant challenge is the models’ tendency to produce “hallucinations” or factual errors due to their reliance on internal knowledge bases. This issue has been particularly pronounced in large language models (LLMs), which often need improvement despite their linguistic prowess when generating content that aligns with real-world facts.
The concept of retrieval-augmented generation (RAG) was introduced to combat this by bolstering LLMs through the integration of external, relevant knowledge during the generation process. However, RAG’s success heavily depends on the accuracy and relevance of the retrieved documents. The pivotal question arises: what happens when the retrieval process fails, introducing inaccuracies or irrelevant information into the generative process?
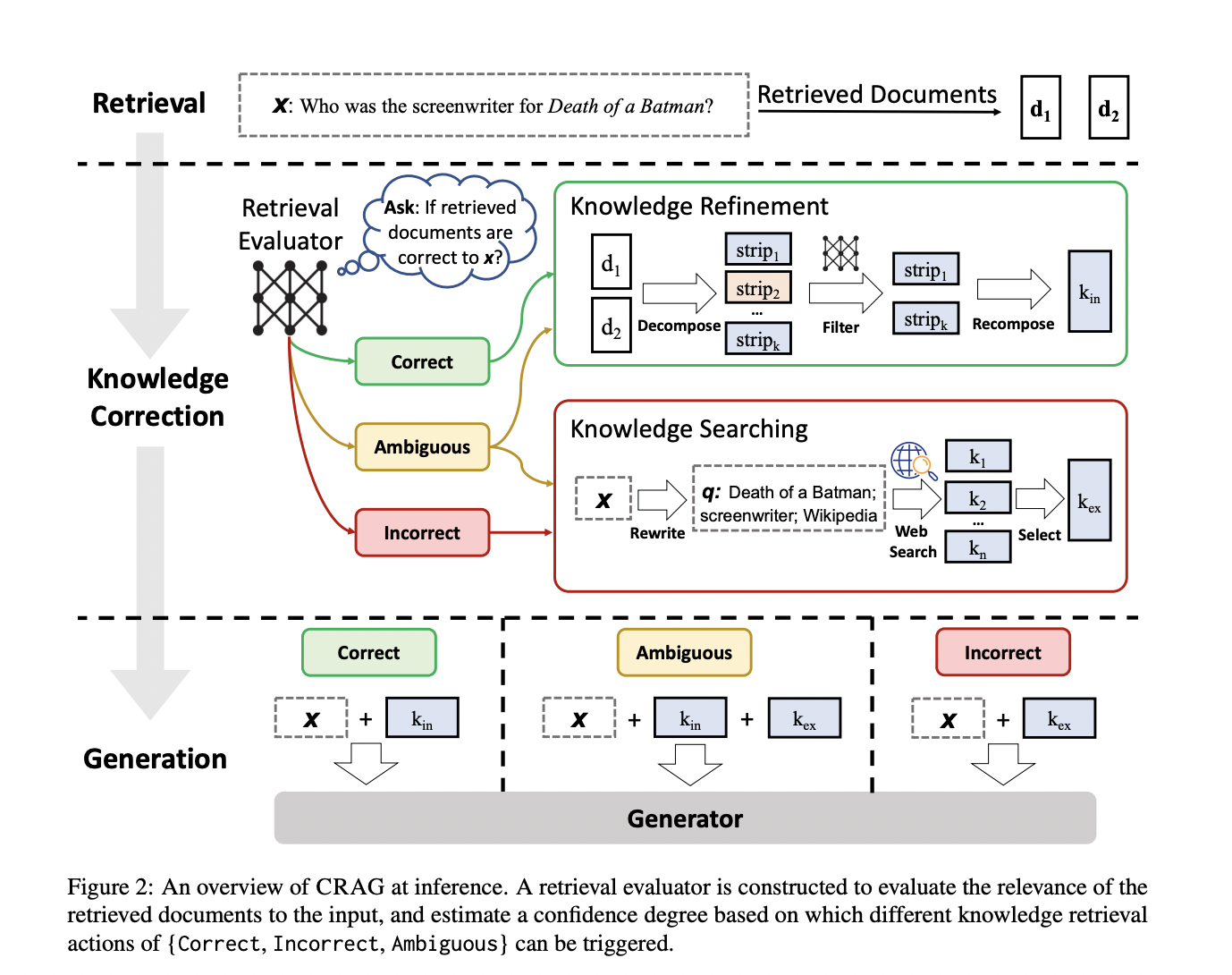
Meet Corrective Retrieval Augmented Generation (CRAG), a groundbreaking methodology devised by researchers to fortify the generation process against the pitfalls of inaccurate retrieval. At its core, CRAG introduces a lightweight retrieval evaluator, a mechanism designed to assess the quality of retrieved documents for any given query. This evaluator is pivotal, offering a nuanced understanding of the retrieved documents’ relevance and reliability. Based on its assessments, the evaluator can trigger different knowledge retrieval actions, enhancing the generated content’s robustness and accuracy.
CRAG’s methodology is distinguished by its dynamic approach to document retrieval. CRAG doesn’t stop at mere acknowledgment when the evaluation deems the retrieved documents suboptimal. Instead, it employs a sophisticated decompose-recompose algorithm, selectively focusing on the crux of the retrieved information while discarding the chaff. This ensures that only the most relevant, accurate knowledge is integrated into the generation process. Moreover, CRAG embraces the vastness of the web, utilizing large-scale searches to augment its knowledge base beyond static, limited corpora. This not only broadens the spectrum of retrieved information but also enriches the quality of the generated content.
The efficacy of CRAG has been rigorously tested across multiple datasets, encompassing both short- and long-form generation tasks. The results are telling. CRAG consistently outperforms standard RAG approaches, showcasing its ability to navigate accurate knowledge retrieval and integration complexities. This is particularly evident in its application to short-form question answering and long-form biography generation, where the precision and depth of information are paramount.
These advancements signify a leap forward in pursuing more reliable, accurate language models. CRAG’s ability to refine the retrieval process, ensuring high relevance and reliability in the external knowledge it leverages, marks a significant milestone. This method addresses the immediate challenge of “hallucinations” in LLMs and sets a new standard for integrating superficial knowledge in the generation process.
In essence, CRAG redefines the landscape of language model accuracy. Its development underscores a pivotal shift towards models that generate fluent text and do so with unprecedented factual integrity. This progress promises to enhance the utility of LLMs across a spectrum of applications, from automated content creation to sophisticated conversational agents, paving the way for a future where language models reliably mirror the richness and accuracy of human knowledge.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.