Alibaba Researchers Introduce Mobile-Agent: An Autonomous Multi-Modal Mobile Device Agent
Mobile device agents utilizing Multimodal Large Language Models (MLLM) have gained popularity due to the rapid advancements in MLLMs, showcasing notable visual comprehension capabilities. This progress has made MLLM-based agents viable for diverse applications. The emergence of mobile device agents represents a novel application, requiring these agents to operate devices based on screen content and user instructions.

Existing work highlights the capabilities of Large Language Model (LLM)-based agents in task planning. However, challenges persist, particularly in the mobile device agent domain. While MLLMs show promise, including GPT-4V, they lack sufficient visual perception for effective mobile device operations. Previous attempts utilized interface layout files for localization but faced limitations in file accessibility, hindering their effectiveness.
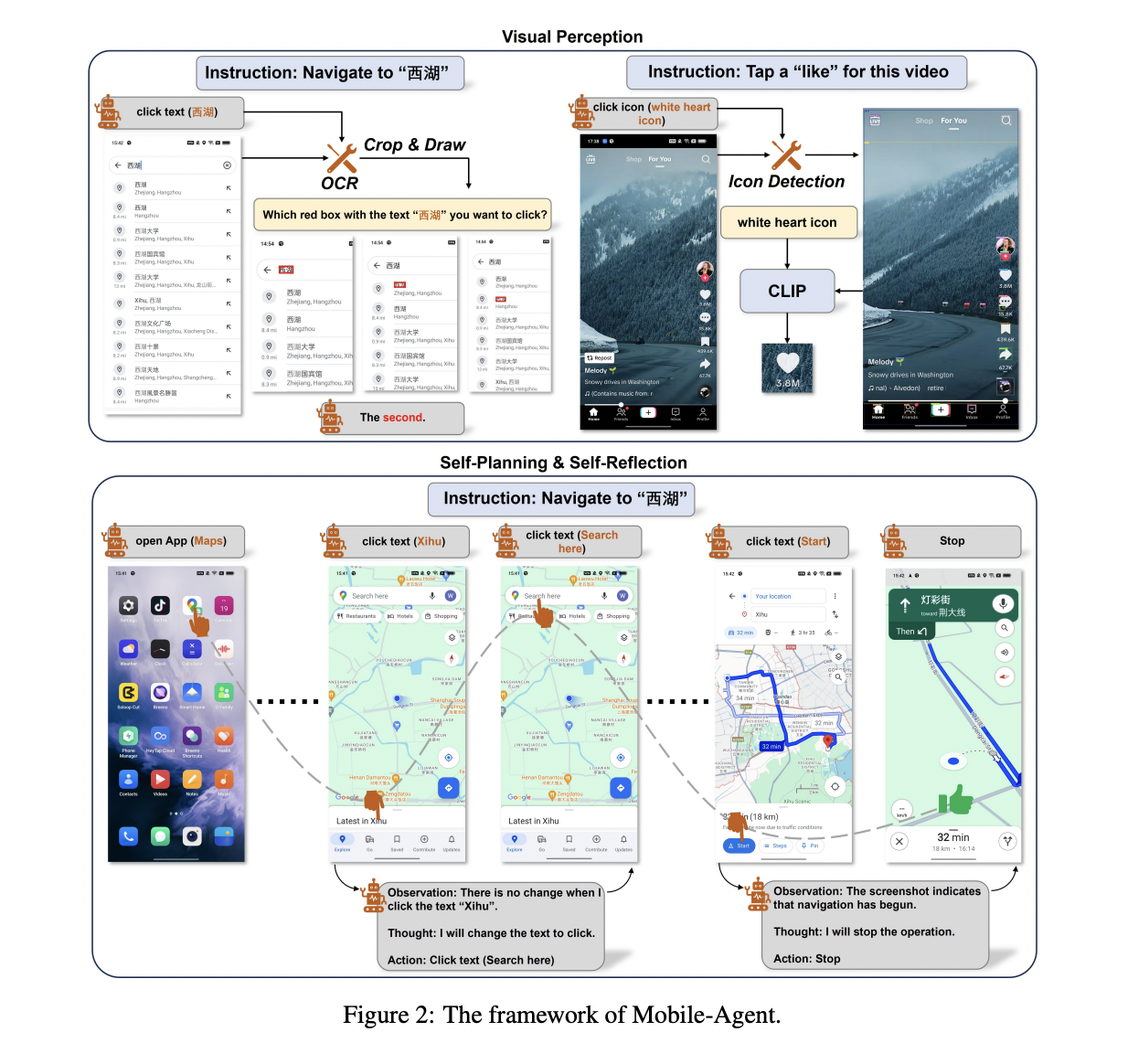
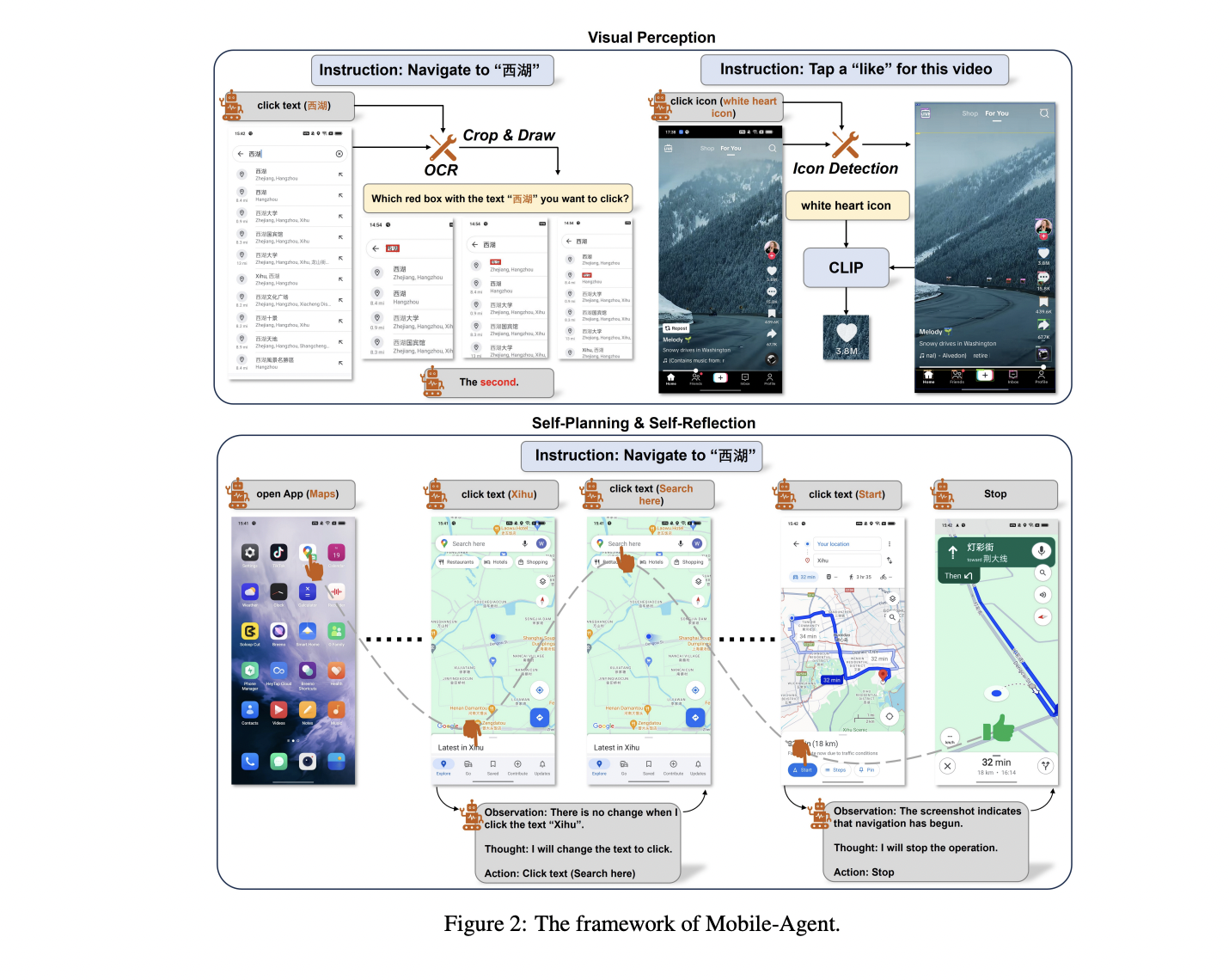
Beijing Jiaotong University and Alibaba Group researchers have introduced Mobile-Agent, an autonomous multi-modal mobile device agent. Their approach utilizes visual perception tools to accurately identify and locate visual and textual elements within an app’s front-end interface. Leveraging the perceived vision context, Mobile-Agent autonomously plans and decomposes complex operation tasks, navigating through mobile apps step by step. Mobile-Agent differs from previous solutions by eliminating reliance on XML files or mobile system metadata, offering enhanced adaptability across diverse mobile operating environments through a vision-centric approach.
Mobile-Agent employs OCR tools for text and CLIP for icon localization. The framework defines eight operations, enabling the agent to perform tasks such as opening apps, clicking text or icons, typing, and navigating. The Mobile Agent exhibits iterative self-planning and self-reflection, enhancing task completion through user instructions and real-time screen analysis. The mobile agent completes each step of the operation iteratively. Before the iteration begins, the user needs to input an instruction. During the iteration, the agent may encounter errors, leading to the inability to complete the instruction. To improve the success rate of instruction, there is a self-reflection method.
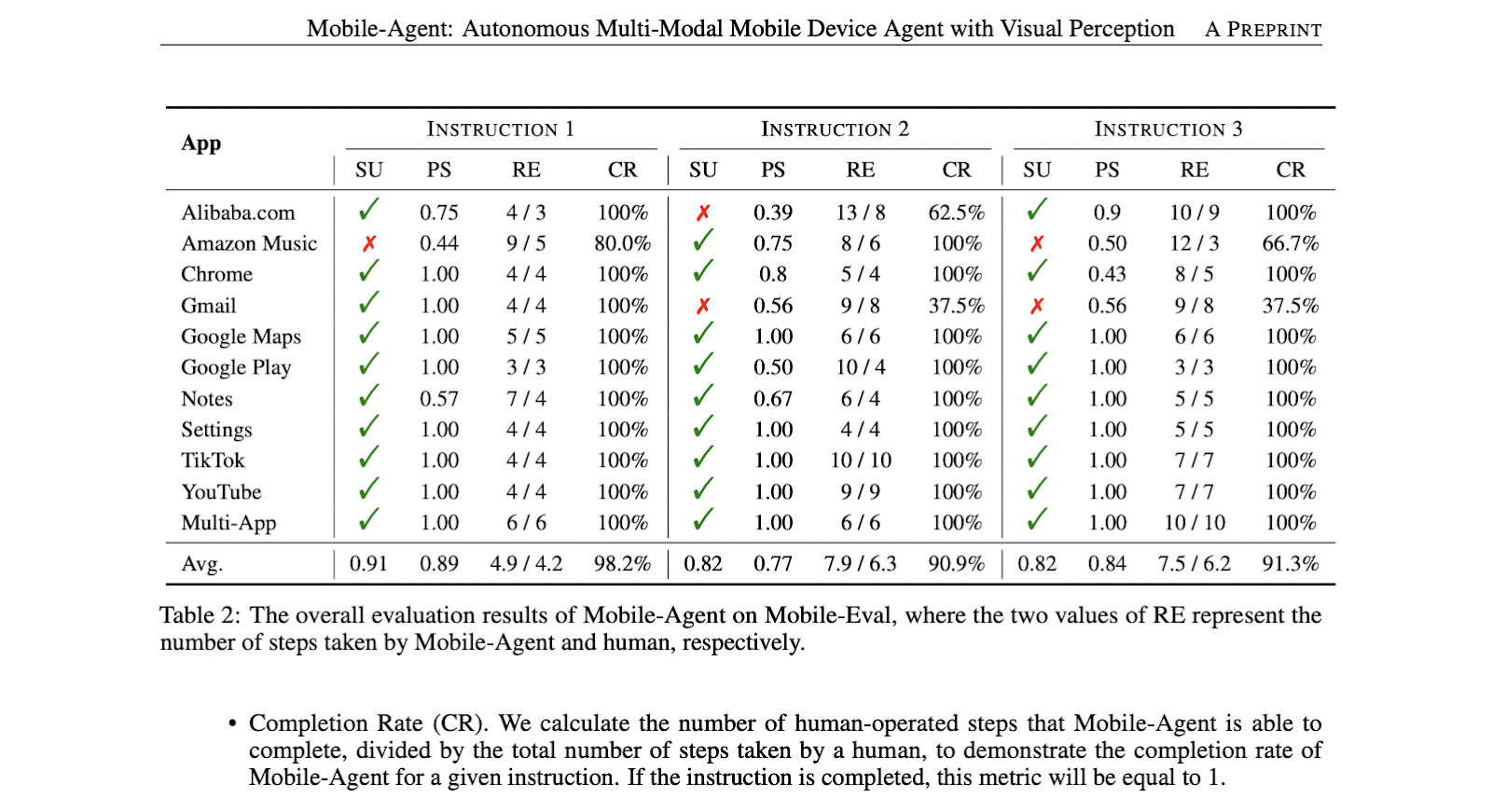
The researchers presented Mobile-Eval, a benchmark of 10 popular mobile apps with three instructions each to evaluate Mobile-Agent comprehensively. The framework achieved completion rates of 91%, 82%, and 82% across instructions, with a high Process Score of around 80%. Relative Efficiency demonstrated Mobile-Agent’s 80% capability compared to human-operated steps. The results highlight the effectiveness of Mobile-Agent, showcasing its self-reflective capabilities in correcting errors during the execution of instructions, contributing to its robust performance as a mobile device assistant.
To sum up, Beijing Jiaotong University and Alibaba Group researchers have introduced Mobile-Agent, an autonomous multimodal agent proficient in operating diverse mobile applications through a unified visual perception framework. By precisely identifying and locating visual and textual elements within app interfaces, Mobile-Agent autonomously plans and executes tasks. Its vision-centric approach enhances adaptability across mobile operating environments, eliminating the need for system-specific customizations. The study demonstrates Mobile-Agent’s effectiveness and efficiency through experiments, highlighting its potential as a versatile and adaptable solution for language-agnostic interaction with mobile applications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.