Meet Time-LLM: A Reprogramming Machine Learning Framework to Repurpose LLMs for General Time Series Forecasting with the Backbone Language Models Kept Intact
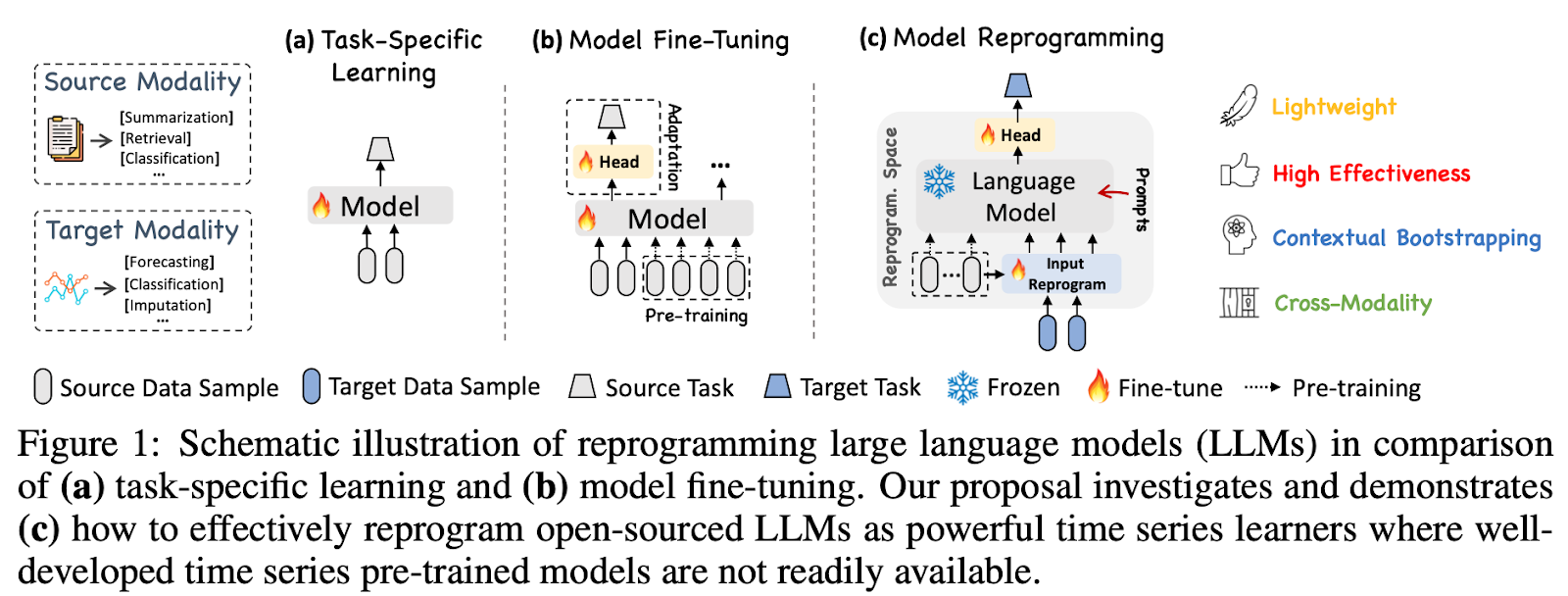
In the rapidly evolving data analysis landscape, the quest for robust time series forecasting models has taken a novel turn with the introduction of TIME-LLM, a pioneering framework developed by a collaboration between esteemed institutions, including Monash University and Ant Group. This framework departs from traditional approaches by harnessing the vast potential of Large Language Models (LLMs), traditionally used in natural language processing, to predict future trends in time series data. Unlike the specialized models that require extensive domain knowledge and copious amounts of data, TIME-LLM cleverly repurposes LLMs without modifying their core structure, offering a versatile and efficient solution to the forecasting problem.
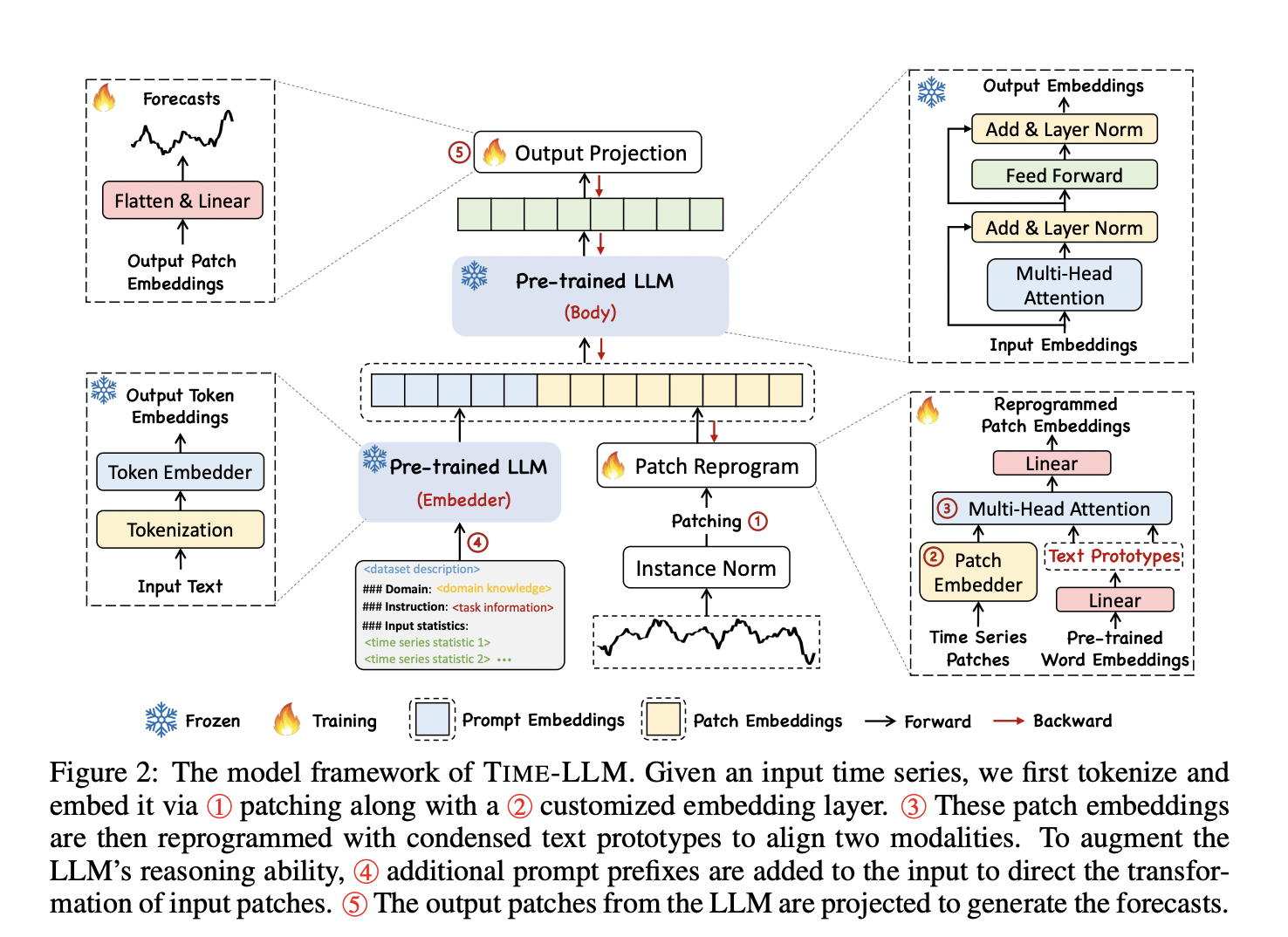
At the heart of TIME-LLM lies an innovative reprogramming technique that translates time series data into text prototypes, effectively bridging the gap between numerical data and the textual understanding of LLMs. This method, known as Prompt-as-Prefix (PaP), enriches the input with contextual cues, allowing the model to interpret and forecast time series data accurately. This approach not only leverages LLMs’ inherent pattern recognition and reasoning capabilities but also circumvents the need for domain-specific data, setting a new benchmark for model generalizability and performance.
The methodology behind TIME-LLM is both intricate and ingenious. By segmenting the input time series into discrete patches, the model applies learned text prototypes to each segment, transforming them into a format that LLMs can comprehend. This process ensures that the vast knowledge embedded in LLMs is effectively utilized, enabling them to draw insights from time series data as if it were natural language. Adding task-specific prompts further enhances the model’s ability to make nuanced predictions, providing a clear directive for transforming the reprogrammed input.
Empirical evaluations of TIME-LLM have underscored its superiority over existing models. Notably, the framework has demonstrated exceptional performance in both few-shot and zero-shot learning scenarios, outclassing specialized forecasting models across various benchmarks. This is particularly impressive considering the diverse nature of time series data and the complexity of forecasting tasks. Such results highlight the adaptability of TIME-LLM, proving its efficacy in making precise predictions with minimal data input, a feat that traditional models often need help to achieve.
The implications of TIME-LLM’s success extend far beyond time series forecasting. By demonstrating that LLMs can be effectively repurposed for tasks outside their original domain, this research opens up new avenues for applying LLMs in data analysis and beyond. The potential to leverage LLMs’ reasoning and pattern recognition capabilities for various types of data presents an exciting frontier for exploration.
In essence, TIME-LLM embodies a significant leap forward in data analysis. Its ability to transcend traditional forecasting models’ limitations, efficiency, and adaptability positions it as a groundbreaking tool for future research and applications. TIME-LLM and similar frameworks are vital for shaping the next generation of analytical tools. They’re versatile and powerful, making them indispensable for navigating complex data-driven decision-making.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.