Researchers from EPFL and Meta AI Proposes Chain-of-Abstraction (CoA): A New Method for LLMs to Better Leverage Tools in Multi-Step Reasoning
Recent advancements in large language models (LLMs) have propelled the field forward in interpreting and executing instructions. Despite these strides, LLMs still grapple with errors in recalling and composing world knowledge, leading to inaccuracies in responses. To address this, the integration of auxiliary tools, such as using search engines or calculators during inference, has been proposed to enhance reasoning. However, existing tool-augmented LLMs face challenges in efficiently leveraging tools for multi-step reasoning, particularly in handling interleaved tool calls and minimizing inference waiting times.
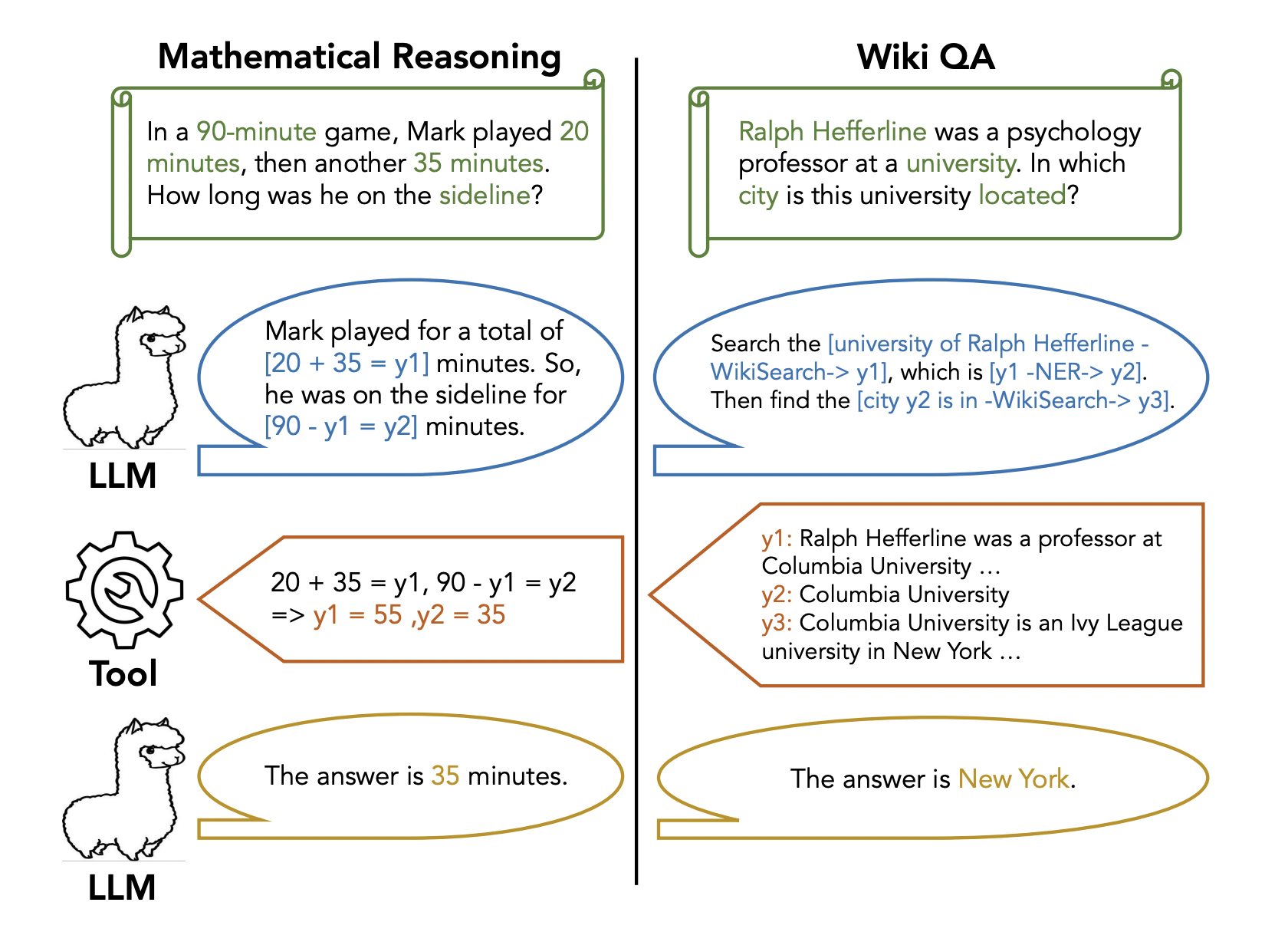
In response to these challenges, this research from EPFL and Meta introduces the Chain-of-Abstraction (CoA) reasoning method, a robust and efficient approach for LLMs to perform multi-step reasoning with tools. The core idea is illustrated in Figure 1, where LLMs are fine-tuned to create reasoning chains with abstract placeholders (e.g., y1, y2, y3). Subsequently, these placeholders are replaced with specific knowledge obtained from external tools, such as calculators or web search engines, grounding the final answer generations.
Moreover, unlike prior methods where LLM decoding and API calls are interleaved, CoA reasoning promotes effective planning by encouraging LLMs to interconnect multiple tool calls and adopt more feasible reasoning strategies. The abstract chain of reasoning allows LLMs to focus on general and holistic reasoning strategies without generating instance-specific knowledge for the model’s parameters. Notably, the decoupling of general reasoning and domain-specific knowledge enables parallel processing, where LLMs can generate the next abstract chain while tools fill the current chain, thus speeding up the overall inference process.
To train LLMs for CoA reasoning, the authors construct fine-tuning data by repurposing existing open-source question-answering datasets (Cobbe et al., 2021; Miao et al., 2020; Yang et al., 2018). LLaMa-70B is prompted to re-write answers as abstract chains, replacing specific operations with abstract placeholders. The resulting CoA traces are validated using domain-specialized tools to ensure accuracy.
The CoA method is evaluated in two domains: mathematical reasoning and Wikipedia question answering (Wiki QA). For mathematical reasoning, LLMs are trained on CoA data constructed by re-writing the GSM8K (Cobbe et al., 2021) training set. CoA outperforms few-shot and regular fine-tuning baselines on both in-distribution and out-of-distribution datasets, showcasing its effectiveness in multi-step reasoning tasks. The CoA method also demonstrates superior performance compared to the Toolformer baseline.
In the Wiki QA domain, HotpotQA (Yang et al., 2018) is utilized to construct fine-tuning CoA data. CoA surpasses baselines, including Toolformer, and achieves remarkable generalization ability on diverse question-answering datasets (WebQuestions, NaturalQuestions, TriviaQA). Domain tools, such as a Wikipedia search engine and named-entity recognition toolkit, further enhance the performance of CoA.
The evaluation results across both domains indicate significant improvements with the CoA method, yielding an average accuracy increase of ∼7.5% and 4.5% for mathematical reasoning and Wiki QA, respectively. These improvements hold across in-distribution and out-of-distribution test sets, particularly benefiting questions requiring complex chain-of-thought reasoning. CoA also exhibits faster inference speeds, outpacing previous augmentation methods on mathematical reasoning and Wiki QA tasks.
In conclusion, The proposed CoA reasoning method separates general reasoning from domain-specific knowledge, fostering more robust multi-step reasoning in LLMs. Its efficiency in tool usage contributes to faster inference, making it a promising approach for diverse reasoning scenarios. The experiments on mathematical reasoning and Wiki QA underscore the versatility and efficacy of the CoA method, suggesting its potential for broader applications in enhancing LLM performance in various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.