Can Large Language Models Understand Context? This AI Paper from Apple and Georgetown University Introduces a Context Understanding Benchmark to Suit the Evaluation of Generative Models

In the ever-evolving landscape of natural language processing (NLP), the quest to bridge the gap between machine interpretation and the nuanced complexity of human language continues to present formidable challenges. Central to this endeavor is the development of large language models (LLMs) capable of parsing and fully understanding the contextual nuances underpinning human communication. This pursuit has led to significant innovations, yet a persistent gap remains, particularly in the models’ ability to navigate the intricacies of context-dependent linguistic features.
The core issue at hand extends beyond the conventional boundaries of language model evaluation, venturing into the realm where the subtleties of dialogue, narrative structure, and implicit meaning converge. Traditional approaches, while groundbreaking, often fall short of fully capturing the breadth of context’s role in language comprehension. Recognizing this, a dedicated team of researchers pioneered to craft a benchmark that rigorously tests LLMs across a spectrum of contextually rich scenarios. Unlike its predecessors, this new benchmark is meticulously designed to probe the models’ proficiency in discerning and utilizing contextual cues across a diverse set of linguistic tasks.
The researchers from Georgetown University and Apple introduced an array of tasks, each tailored to evaluate different facets of contextual understanding. From coreference resolution, where the model must identify linguistic entities that refer to the same thing across sentences, to dialogue state tracking, which requires keeping track of evolving conversation states, the benchmark pushes LLMs to their limits. Other tasks, such as implicit discourse relation classification and query rewriting, further test the models’ ability to infer relationships between sentences and reformulate queries in a context-aware manner. This multifaceted approach assesses current capabilities and illuminates the path toward more sophisticated language comprehension models.
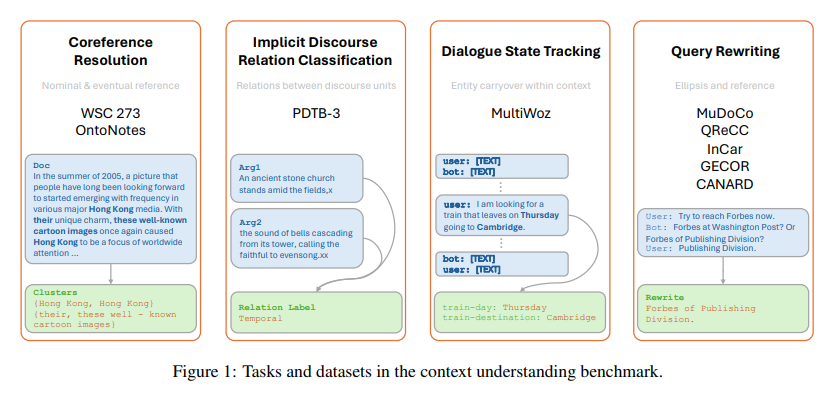
An equally thorough evaluation methodology complements the benchmark’s rigorous design. The researchers employed state-of-the-art LLMs and examined their performance across the benchmark’s tasks. The results revealed variance in the models’ ability to grasp and apply linguistic context. Some models demonstrated remarkable proficiency in certain tasks while others struggled, underscoring the complexity of context comprehension in NLP. This nuanced performance analysis serves as a critical tool for identifying strengths and areas needing enhancement within current language models.
Reflecting on the study’s findings, several key insights emerge:
- The disparity in model performance across different tasks underscores the multifaceted nature of context in language. It suggests that comprehensive contextual understanding requires a model capable of adapting to various linguistic scenarios.
- The benchmark represents a significant advancement in the field, offering a more holistic and nuanced framework for evaluating language models. It sets a new standard for future research and development by encompassing a broader spectrum of contextual challenges.
- The research highlights the ongoing need for language model training and development innovation. As models evolve, so must the methodologies used to assess their comprehension capabilities. The benchmark facilitates this evolution and drives the field toward more nuanced and human-like language understanding.
In conclusion, the journey toward models that can truly understand human language in all its complexity is challenging and exhilarating. This research marks a pivotal step forward, offering a comprehensive tool for evaluating and enhancing contextual understanding in language models. As the field progresses, the insights gained from this work will undoubtedly play a crucial role in shaping the next generation of NLP technologies, ultimately bringing us closer to seamless human-machine communication.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.