Can Large Language Models be Trusted for Evaluation? Meet SCALEEVAL: An Agent-Debate-Assisted Meta-Evaluation Framework that Leverages the Capabilities of Multiple Communicative LLM Agents
Despite the utility of large language models (LLMs) across various tasks and scenarios, researchers need help to evaluate LLMs properly in different situations. They use LLMs to check their responses, but a solution must be found. This method is limited because there aren’t enough benchmarks, and it often requires a lot of human input. They urgently need better ways to test how well LLMs can evaluate things in all situations, especially when users define new scenarios.
LLMs have advanced significantly, demonstrating impressive performance across various tasks. However, evaluating their outputs presents complex challenges. Current approaches primarily rely on automated metrics, often employing LLMs for evaluation. While some functions undergo rigorous meta-evaluation, requiring costly human-annotated datasets, many applications need more scrutiny, leading to potential unreliability in LLMs as evaluators.
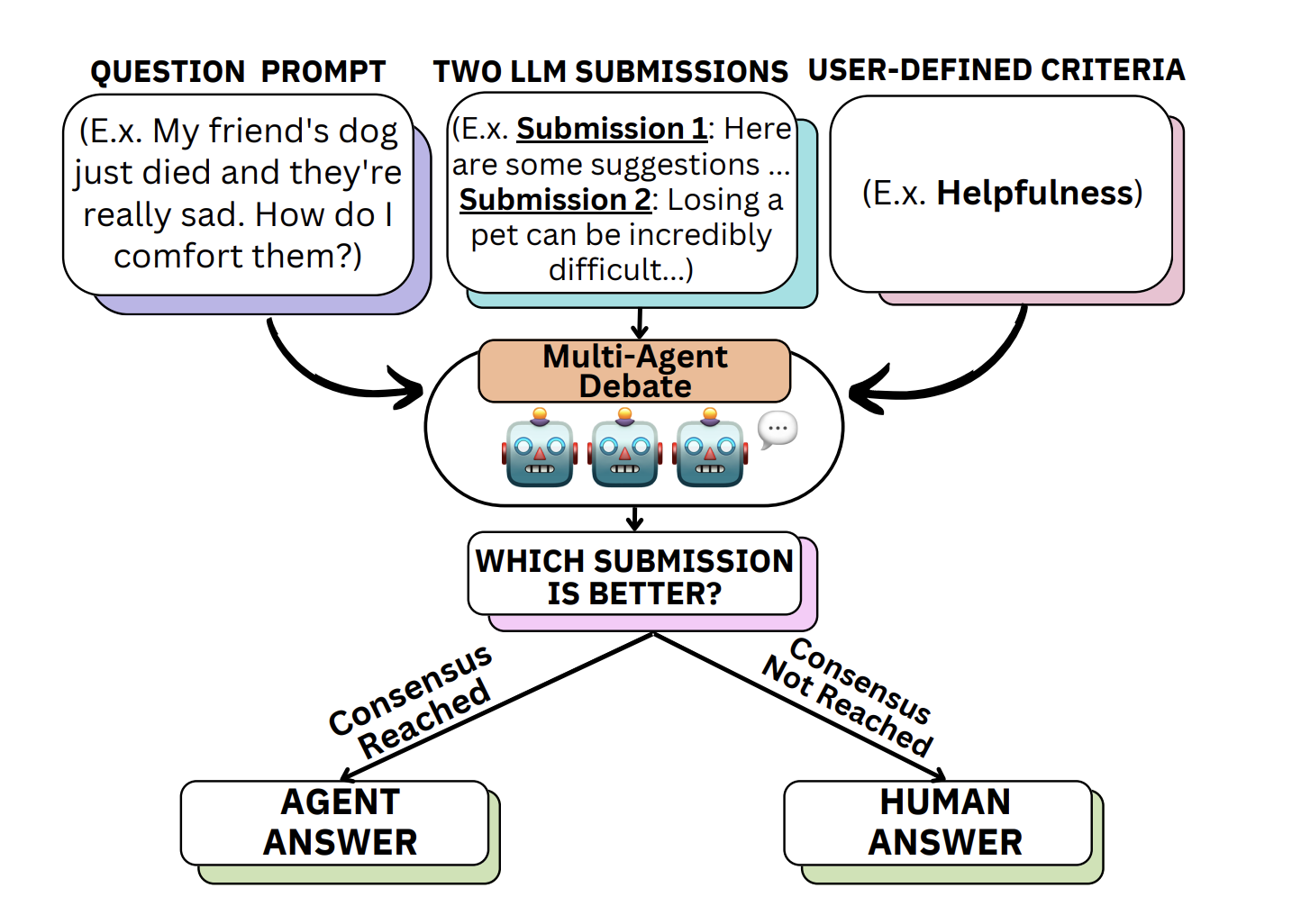
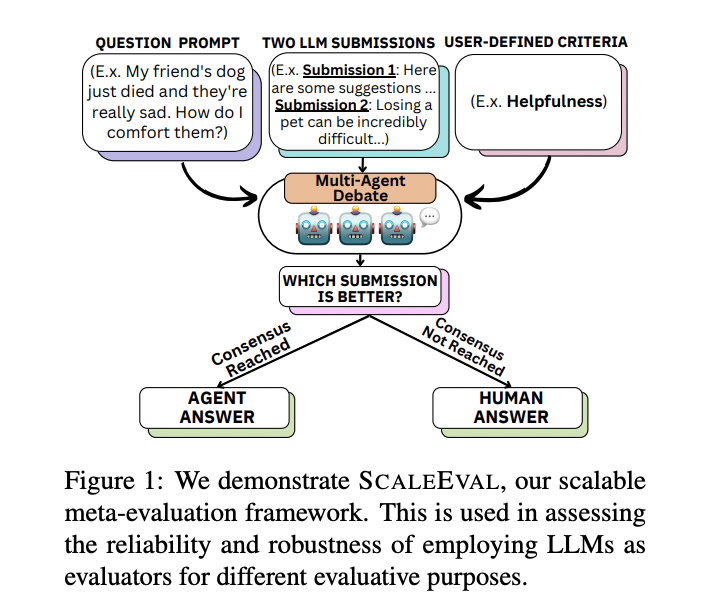
Researchers from Shanghai Jiao Tong University, Carnegie Mellon University, Shanghai Artificial Intelligence Laboratory, and Generative AI Research Lab (GAIR) introduce SCALEEVAL, a meta-evaluation framework utilizing multiple communicative LLM agents with an agent-debate approach. This system facilitates multi-round discussions, aiding human annotators in identifying the most proficient LLMs for evaluation. This approach substantially reduces the burden on annotators, especially in scenarios where extensive annotations were traditionally necessary for meta-evaluation.
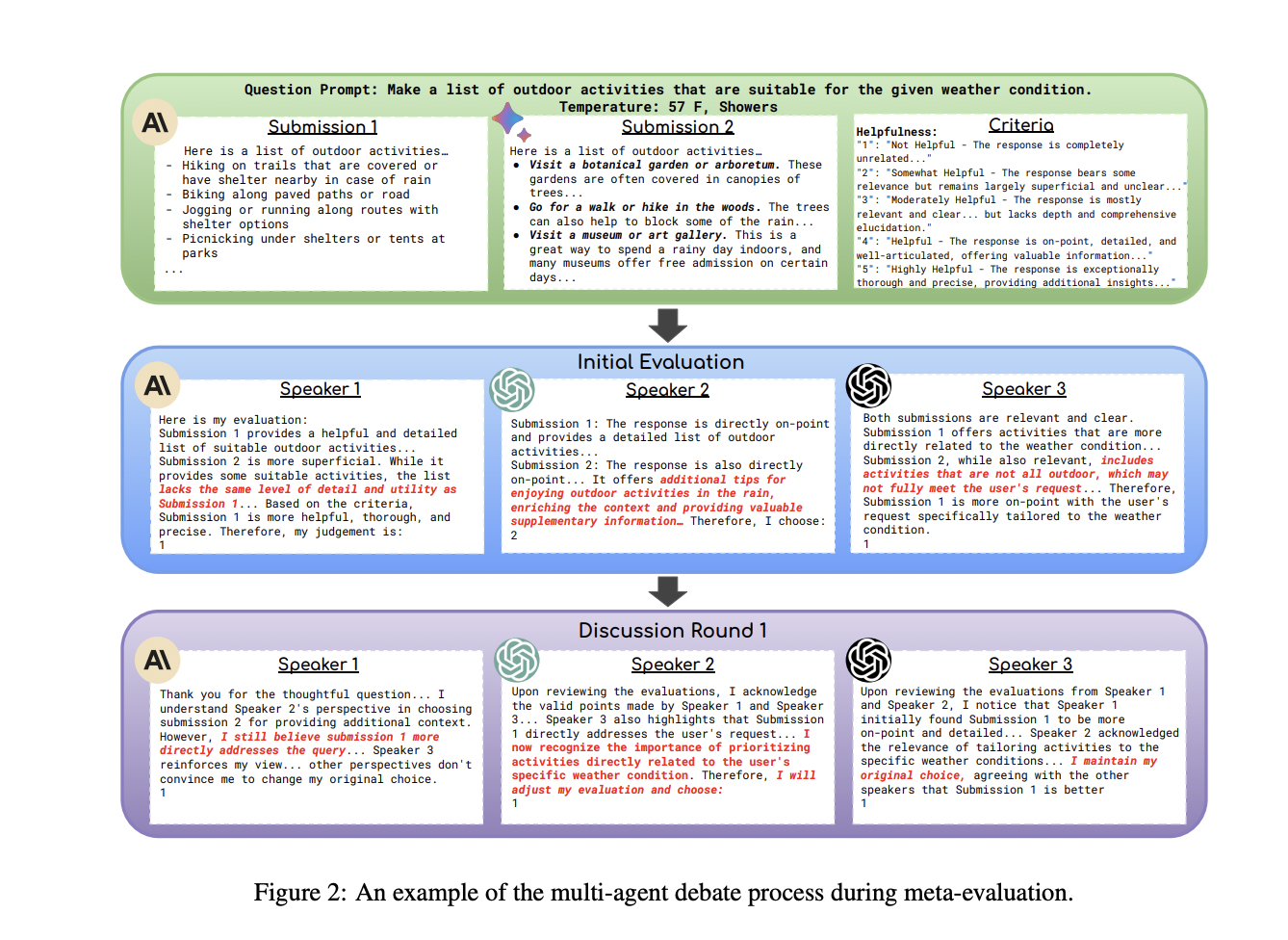
SCALEEVAL leverages multi-agent debate for reliable meta-evaluation of LLMs. In the meta-evaluation process, LLM agents engage in rounds of discussions to assess responses based on user-defined criteria. This reduces the reliance on extensive human annotation and ensures scalability. The evaluation framework involves pairwise response comparisons, focusing on LLMs like gpt-3.5-turbo. Human expert meta-meta evaluation validates the proposed method’s reliability by applying the agent-debate-assisted and human expert annotation protocols. This approach balances efficiency with human judgment for accurate and timely assessments.
Studies reveal that LLMs’ performance as evaluators tends to decline when specific letters in criteria prompts are masked. The removal of guiding phrases further diminishes effectiveness. Gpt-4-turbo and gpt-3.5-turbo exhibit resilience, maintaining consistent agreement rates across criteria formats. In contrast, Claude-2 displays confusion and reluctance, especially with adversarial prompts, rejecting approximately half of the questions. The tested LLMs struggle with substituted criteria information, indicating room for improvement in their design and application despite their advanced capabilities.
In conclusion, The researchers have introduced SCALEEVAL, a scalable meta-evaluation framework utilizing agent-debate assistance to assess LLMs as evaluators. This proposal addresses the inefficiencies of conventional, resource-intensive meta-evaluation methods, which are crucial as LLM usage grows. The study not only validates the reliability of SCALEEVAL but also illuminates the capabilities and limitations of LLMs in diverse scenarios. This work contributes to advancing scalable solutions for evaluating LLMs, which is vital for their expanding applications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.